《Group Sequence Policy Optimization》
稳定、高效地训练大语言模型。与以往算法在单个token层面计算重要性比例不同,GSPO 在整个序列的似然度(sequence likelihood)基础上定义重要性比例,并在序列级别上进行裁剪、奖励分配和优化。研究表明,GSPO相比于GRPO算法,在训练效率和模型性能上都表现更优,并且显著稳定了混合专家(MoE)模型的强化学习训练过程,还有简化强化学习基础设施的潜力。这些优点最终促成了最新的Qwen3模型的显著性能提升。
预备知识
理解GSPO所需要的基础知识。用 $\pi_{\theta}$ 表示自回归语言模型策略,x代表问题(query),y代表回答(response)。然后回顾了两种关键的现有算法。一是“近端策略优化”(Proximal Policy Optimization, PPO),它通过裁剪机制将策略更新限制在旧策略附近,其目标函数为
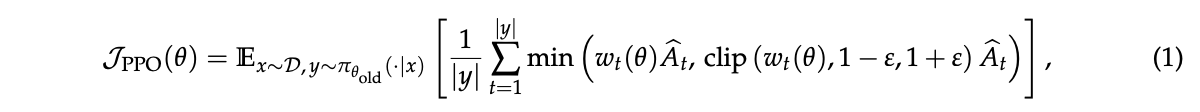
PPO的主要挑战是严重依赖一个与策略模型大小相当的价值模型(value model),这带来了巨大的计算和内存开销,而且价值模型的可靠性难以保证 。二是“群体相对策略优化”(Group Relative Policy Optimization, GRPO),它通过计算同一问题下多个回答之间的相对优势,从而绕开了对价值模型的需求。GRPO的目标函数为
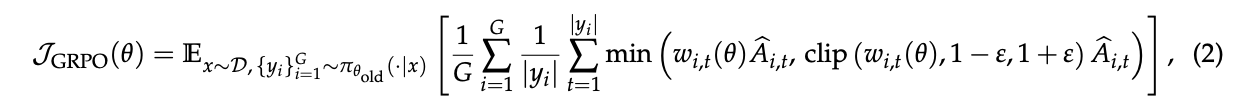
其中优势函数 $\hat{A}_{i,t}$ 是通过将单个回答的奖励与一组回答的平均奖励进行比较得出的。
动机
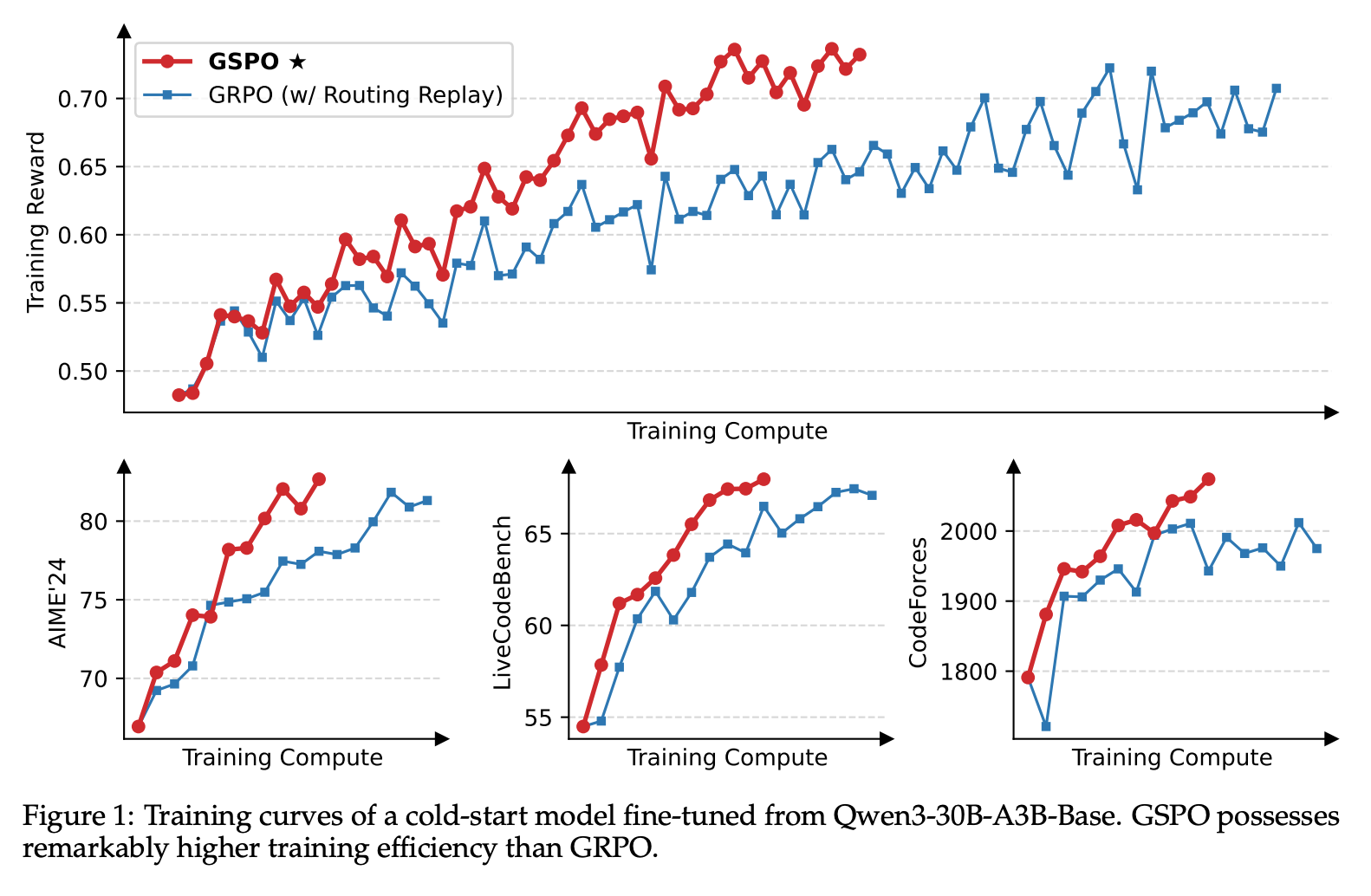
在进行大规模RL训练时,为了充分利用硬件,通常需要很大的批次大小(batch size),并通过多轮小批次(mini-batch)更新来提高样本效率,这就引入了off-policy学习的场景,即用于优化的数据来自于旧策略 $\pi_{\theta_{old}}$ 而非当前策略 $\pi_{\theta}$ 。尽管PPO和GRPO中的裁剪机制是为了应对这种偏离,但作者指出GRPO的目标函数存在一个更根本的设计缺陷。这个缺陷源于对重要性采样权重的不当使用 。重要性采样的原理 $E_{z\sim\pi_{tar}}[f(z)]=E_{z\sim\pi_{beh}}[\frac{\pi_{tar}(z)}{\pi_{beh}(z)}f(z)]$ 要求通过对多个样本的加权平均来修正分布差异。然而,GRPO在每个token(token)级别上应用权重$\frac{\pi_\theta\left(y_{i, t} \mid x, y_{i, 优化的基本单元(unit of optimization)应该与奖励(reward)的基本单元相匹配 。在语言模型的强化学习中,奖励是针对整个生成的序列(sequence)而给出的,因此,在词元(token)级别进行离策略校正和优化本身就是有问题的。正是基于这一洞察,作者决定放弃词元级别的优化目标,转而探索直接在序列级别上使用重要性权重并进行优化,这直接催生了GSPO算法的设计 。 虽然token级别的重要性权重存在问题,但序列级别的重要性权重 $\frac{\pi_{\theta}(y|x)}{\pi_{\theta_{old}}(y|x)}$ 具有明确的理论意义,它衡量了由旧策略生成的整个序列y与新策略的偏离程度,这与序列级别的奖励天然对齐。基于此,GSPO的核心目标函数被定义为: 其中,重要性比例 $s_{i}(\theta)$ 基于序列似然度定义并进行了长度归一化,即 这样做是为了减少方差,并使不同长度序列的重要性比例保持在统一的数值范围内。 通过梯度分析,作者揭示了GSPO和GRPO的根本区别:GSPO对一个序列中的所有token给予相同的权重,即序列整体的重要性权重,而GRPO则对每个token使用不同的、充满噪声的权重,从而消除了GRPO的不稳定因素。此外,论文还提出了一个变体GSPO-token,它允许在token级别上自定义优势 $\hat{A}_{i,t}$,以适应多轮对话等需要更精细控制的场景,同时在理论上保持了与标准GSPO相同的稳定性和优化特性。 实验展示了GSPO与GRPO在多个基准测试(如AIME'24、LiveCodeBench)上的训练曲线,结果表明GSPO的训练过程更稳定,并且在相同的计算资源下,能更快地达到更高的训练奖励和模型性能。一个有趣的发现是,GSPO裁剪掉的token(tokens)比例远高于GRPO(高出两个数量级),但训练效率却更高。这反直觉地说明,GRPO的token级梯度估计充满了噪声且效率低下,而GSPO的序列级方法能提供更可靠、有效的学习信号。接着,论文重点讨论了GSPO对混合专家(MoE)模型训练的益处。MoE模型在RL训练中存在“专家激活不稳定”的问题,即梯度更新后,模型处理相同输入时激活的专家会发生变化,这使得GRPO的token级重要性比例剧烈波动,导致训练失败。之前的解决方法是采用一种名为“路由回放”(Routing Replay)的复杂策略来强制使用相同的专家。而GSPO通过关注对专家变化不敏感的序列整体似然度,从根本上解决了这个问题,不再需要“路由回放”这类复杂的变通方法,简化了训练过程并能充分发挥MoE模型的全部能力 。最后,GSPO还有助于简化RL的基础设施,因为它对训练和推理引擎之间的计算精度差异容忍度更高,可能避免重新计算似然度这一耗时步骤,从而简化整个工作流程 。算法
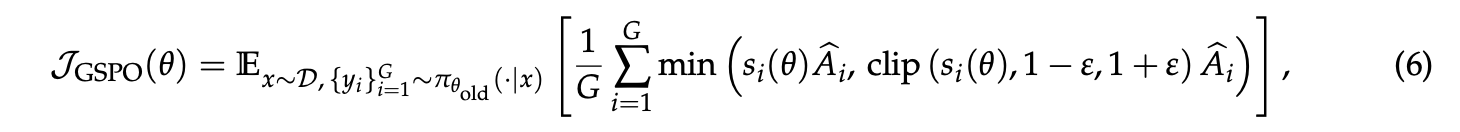
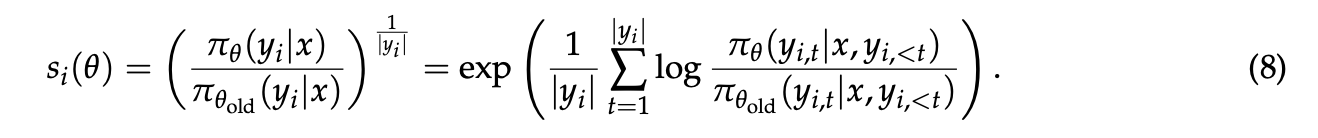
实验与讨论