
《Towards AI Search Paradigm》
本文提出了一个“AI搜索范式”,区别于传统搜索引擎和现有检索增强生成(RAG)系统的工作模式。传统的搜索系统像一条直线流水线,按部就班地检索、排序、生成答案,难以处理需要多步骤推理的复杂问题。这篇论文提出的新范式则像一个动态协作的专家团队,由四个核心的LLM(大语言模型)智能体组成:Master(大师)、Planner(规划师)、Executor(执行器)和Writer(作家)。Master负责分析用户问题的复杂性并组建最合适的智能体团队;Planner负责将复杂问题分解成一个可执行的计划图;Executor负责调用各种工具(如搜索、计算)来完成具体的子任务;Writer则负责综合所有结果,生成一个全面、连贯的答案。这种架构的精髓在于其动态性和协作性,能够像人一样思考、规划并解决问题,而不是机械地匹配和生成。
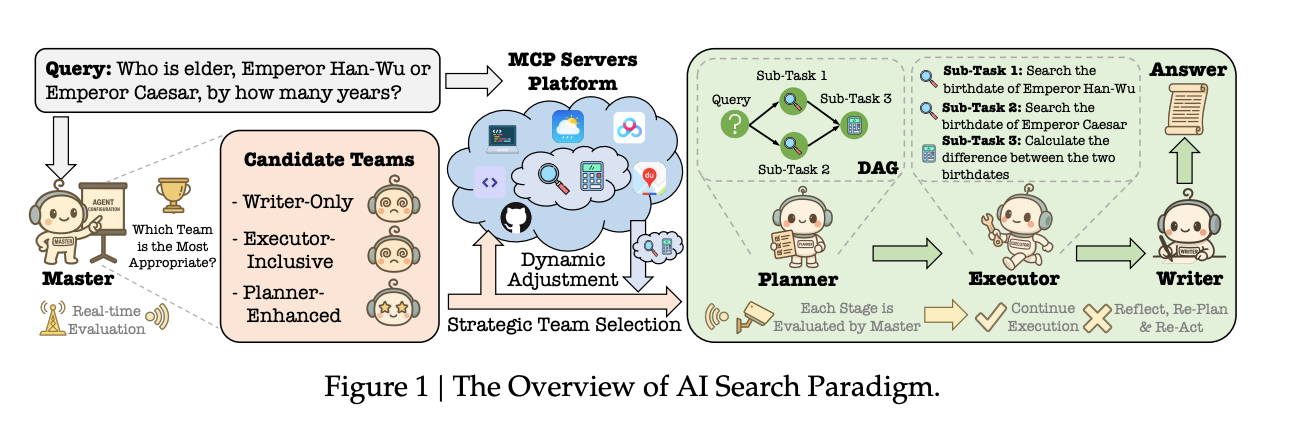
系统概述
通过一个具体的例子“汉武帝和凯撒谁更年长,年长多少岁?”生动地展示了新范式的工作流程,并与传统RAG系统进行了对比,其启发性在于揭示了“规划”在信息处理中的重要性。该系统会根据问题的复杂程度,选择三种不同的团队配置:对于“汉武帝叫什么名字”这类简单问题,采用**“作家-唯一(Writer-Only)”配置,直接生成答案;对于“今天北京天气适合出门吗”这类需要外部信息但无需复杂推理的问题,采用“执行器-包含(Executor-Inclusive)”配置,由执行器调用天气工具后,作家再整合信息;而对于汉武帝与凯撒年龄比较的复杂问题,则启动最高级的“规划师-增强(Planner-Enhanced)”**配置。在这个模式下,Master首先识别出问题的复杂性,然后委派Planner。
Planner会将问题分解为三个子任务:1. 搜索汉武帝的生卒年份;2. 搜索凯撒的生卒年份;3. 计算年龄差。这个过程被构建成一个有向无环图(DAG),清晰地表达了任务间的依赖关系。随后,Executor按图索骥,调用搜索和计算工具完成任务,最后由Writer综合信息,生成最终答案。这个流程与传统RAG系统一次性检索或简单的“思考-行动”循环相比,展现了更强的逻辑性、鲁棒性和解决复杂问题的能力。
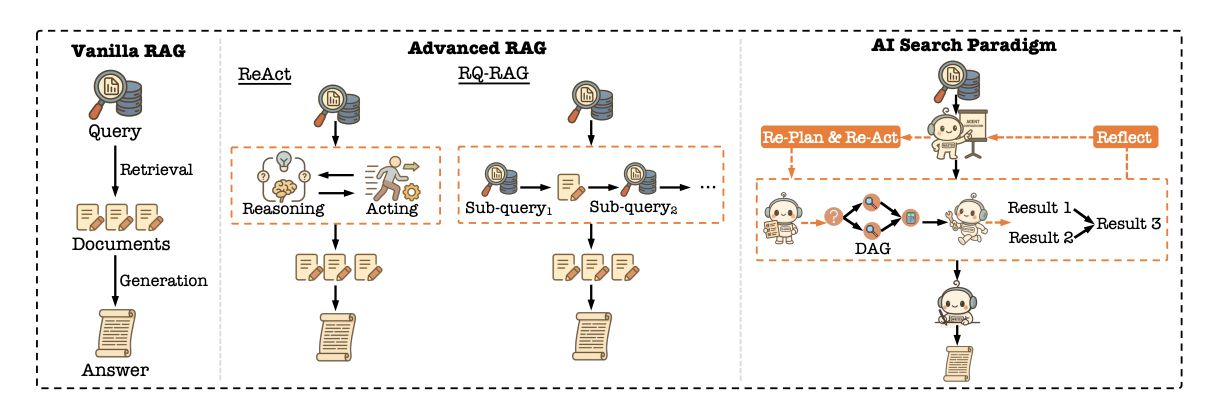
任务规划师
任务规划师是整个系统的大脑,本章详细阐述了它如何解决“规划什么”和“用什么规划”的核心问题。首先,为了解决不同工具API接口标准不一的问题,系统引入了模型-上下文协议(MCP),这是一个统一的、中立的工具接口标准,让所有工具都能被AI无缝理解和调用。其次,面对海量工具,Planner并非全部加载,而是引入了动态能力边界(Dynamic Capability Boundary)的概念。具体做法是:先通过一个名为DRAFT的自动化框架,通过“经验收集-经验学习-文档重写”的循环,迭代优化工具的API文档,使其对LLM更友好;然后,利用k-means++算法对工具进行功能聚类,形成“工具包”以备不时之需(如同一个工具坏了,可以从同类工具包中找替代品);最后,通过一个名为COLT的先进检索方法,该方法不仅看重查询与工具的语义相似性,更通过图学习捕捉工具间的“协作关系”(例如,解决一个复杂问题需要计算器、汇率查询、股价查询三个工具协同工作),从而为当前任务检索出一个功能完备的工具集。在拥有了合适的工具后,Planner会利用思维链和结构化草图提示策略,将用户的复杂查询生成一个基于DAG(有向无环图)的全局任务计划。这个计划是机器可读、可验证的,并且在执行过程中,Master会持续监控,一旦发现执行失败或结果不完整,便会指导Planner进行反思和重新规划(Re-Action)。最后,为了让Planner变得更聪明,系统还采用强化学习(GRPO算法)对其进行优化,其奖励函数综合考虑了最终答案的正确性、用户反馈、输出格式和中间步骤的执行成功率,通过一个全面的奖励信号$\mathcal{R}_{All}=\mathcal{R}_{Ansuver}+\mathcal{R}_{Feedback}+\mathcal{R}_{Format}+\mathcal{R}_{Execution}$来指导Planner学习更优的规划策略。

任务执行器 (Task Executor)
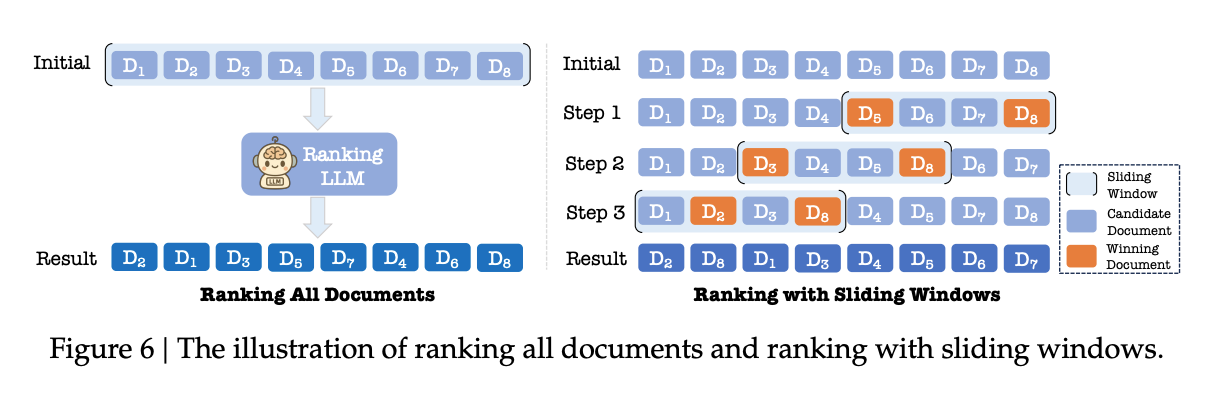
它将传统搜索中“服务于人”的排序目标,转变为“服务于LLM”的召回目标。也就是说,执行器的首要任务不再是给用户提供一个最佳的点击链接列表,而是为后续的Writer(作家)智能体提供一套全面、高质量、让LLM能“读懂”并用于生成答案的参考文档。为了实现LLM偏好对齐(LLM Preference Alignment),执行器采取了四大关键措施:1. LLM标注:利用RankGPT(通过滑动窗口处理长列表)和TourRank(模拟体育赛事中的“锦标赛”机制)等高效的列表排序方法,让LLM来为文档排序,生成高质量的训练数据。2. 参考选择:通过分析LLM在生成答案时实际引用了哪些文档,反过来优化检索策略,从而在未来更倾向于检索这类高质量的文档。3. 生成奖励:这是一种更直接的对齐方式,通过强化学习,让排序器(Ranker)尝试不同的排序策略(如“时效性优先”或“权威性优先”),然后根据生成器(Generator)产出答案的好坏给予奖励或惩罚,直接以最终答案质量为导向来优化排序。4. LLM排序的蒸馏:将一个强大的、但推理成本高昂的“教师”LLM的复杂排序能力,通过RankNet损失函$\mathcal{L}=\sum_{i=1}^{n}\sum_{j=1}^{n}1_{r_{i}^{\prime}<\sigma_{j}^{\prime}}log(1+exp(s_{i}^{S}-s_{j}^{S}))$,“蒸馏”到一个轻量级的、适合在线部署的“学生”排序模型中。此外,为了应对AI搜索中海量子查询带来的性能压力,本章还提出了构建轻量级系统的思路,即用一个统一的LLM模型替代传统“倒排索引+向量检索+精排”的复杂多阶段架构,并利用LLM增强特征,让LLM直接从文本和图像中提取更深层次的语义特征(如权威性、时效性),从而极大地简化了系统并提升了效果。

**基于LLM的生成 **
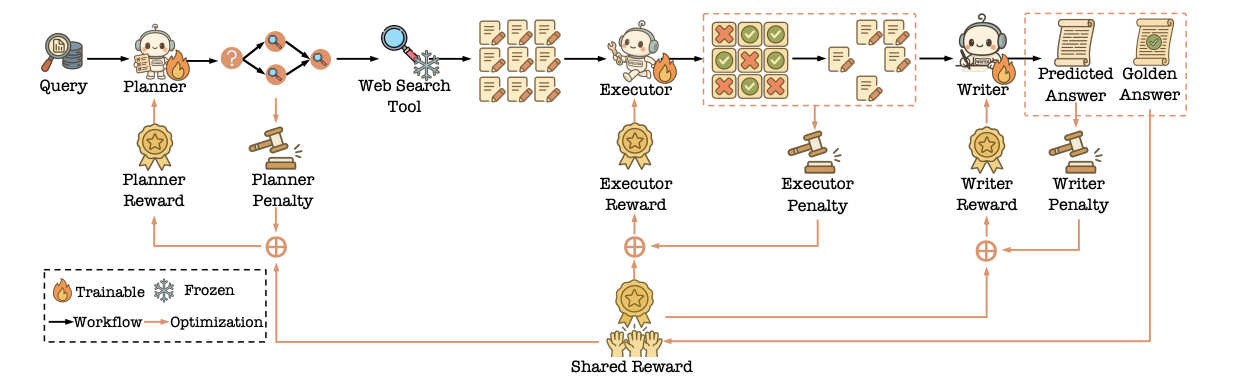
本章聚焦于Writer(作家)智能体,其核心启发在于如何确保最终生成的答案既鲁棒(不怕干扰)、又对齐(符合用户期望),并且能从用户行为中持续学习。关键做法如下:1. 构建鲁棒的RAG系统:为了应对检索器召回的文档中可能存在的噪声和错误,论文提出了一种名为ATM的对抗性训练方法。该方法引入一个“攻击者(Attacker)”智能体,专门负责制造假知识或打乱文档顺序来“攻击”输入,而“生成器(Generator)”,即Writer,则被训练来抵御这种攻击,从而增强其在嘈杂环境下的表现。这个过程通过一个创新的MITO损失函数$\mathcal{L}_{M\Gamma TO}=\mathcal{L}_{SFT}(a|q,D^{\prime})+\alpha\mathcal{L}_{KL}$进行迭代优化。2. RAG任务对齐:为了让生成结果符合用户的三大核心需求——信息丰富度、鲁棒性和引用质量,论文提出了PA-RAG技术。它通过一个两阶段过程实现对齐:首先,通过指令微调让模型具备基础的利用和引用文档的能力;然后,通过直接偏好优化(DPO)技术,按照“信息丰富度 -> 鲁棒性 -> 引用质量”这个由易到难的顺序,对专门构建的偏好数据进行分阶段、课程学习式的优化。3. 利用用户反馈进行优化:为了让模型持续进步,论文提出了RLHB(基于人类行为的强化学习)方法。它不再依赖昂贵的人工标注,而是直接将在线用户的真实行为(如点击、点赞、页面停留时间)转化为奖励信号,通过一个判别器和生成器的对抗训练机制,让Writer的生成策略直接对齐真实用户的偏好。4. 多智能体联合优化:为了解决RAG系统中各模块(规划器、执行器、作家)单独优化可能导致“局部最优,全局不优”的问题,论文提出了MMOA-RAG框架。该框架将整个RAG流程视为一个多智能体协作任务,使用多智能体PPO(MAPPO)算法进行端到端联合优化。所有智能体共享一个最终的全局奖励(如最终答案的F1分数),并结合各自的惩罚项(如规划器生成过多子问题、作家生成答案过长等),从而确保整个团队为了“生成高质量答案”这一共同目标协同工作。

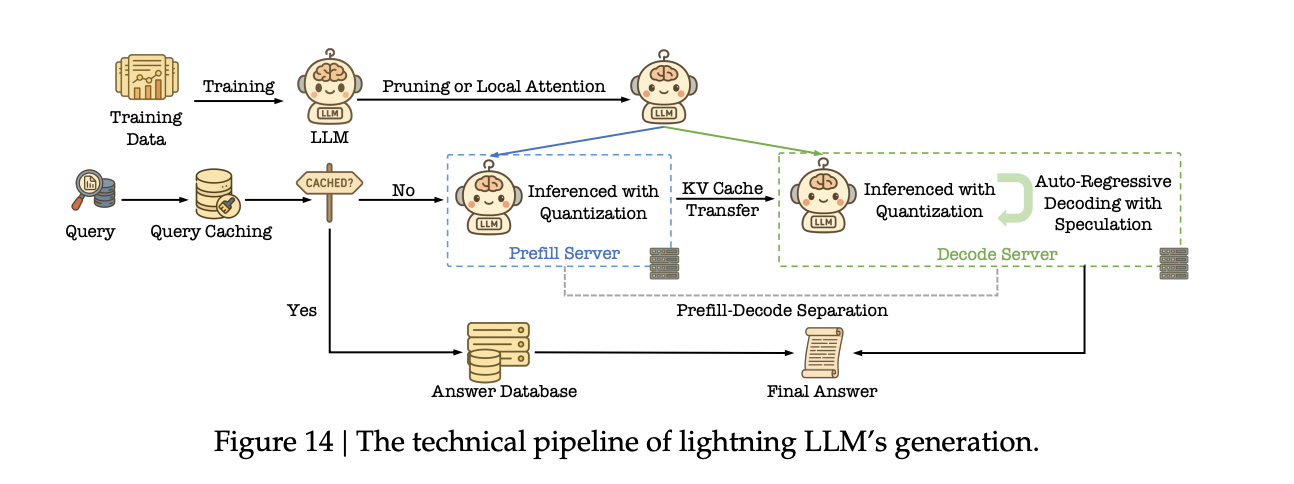
轻量化LLM生成
如何为计算和存储密集型的LLM“瘦身”,以满足搜索应用对低延迟和低成本的苛刻要求。这些轻量化技术分为两大类:
算法层面:核心是减少模型的计算量和参数量。具体方法包括局部注意力(Local Attention),即用计算成本更低的注意力机制(只关注部分上下文)来替代需要全局计算的原始注意力机制,并且这种替换通常只需少量微调甚至无需训练;以及模型剪枝(Model Pruning),特别是结构化剪枝,它直接移除整个神经元、注意力头甚至网络层,从而得到一个更小、更快的稠密模型,能直接在现有硬件上加速。
基础设施层面:核心是优化推理流程和资源利用。具体方法包括专门针对搜索场景的输出长度缩减(通过提示、训练或压缩中间状态,让模型输出更简洁)、语义缓存(Semantic Caching)(缓存相似问题的答案,避免重复计算);以及更通用的技术,如量化(Quantization)(将模型权重从高精度浮点数转为低精度整数或浮点数,减小内存占用并加速计算)、Prefill-Decode分离部署(将计算密集的提示处理阶段和内存带宽密集的生成阶段分开部署,优化资源分配),以及推测解码(Speculative Decoding)(用一个小的“草稿”模型快速生成多个候选词,然后由大模型一次性并行验证,从而加速生成过程)。
评估
本章的启发在于它不仅展示了新范式的优越性,还通过多维度、多场景的评估方式验证了其有效性。在人工评估中,系统将新范式(AI Search)与传统系统(Web Search)的结果进行“背靠背”比较,并使用归一化胜率(NWR) $NWR=\frac{\#Win-\#Lose}{\#Win+\#Tie+\#Lose}$ 这一量化指标。结果显示,对于简单问题,两者表现相当;但对于中等复杂和复杂问题,新范式的优势显著,尤其在复杂查询上实现了13%的相对提升,证明了其强大的推理和规划能力。在在线A/B测试中,系统在真实的百度搜索流量上进行了实验,结果显示新范式显著改善了多项核心用户体验指标,如查询改写率(CQR)降低1.45%(说明用户更容易一次性得到满意答案),日活跃用户数(DAU)提升1.85%,页面浏览量(PV)和用户停留时间(Dwell Time)也均有提升。最后,通过案例分析直观对比了新旧系统在处理简单查询“泰山多高?”和复杂查询“汉武帝和凯撒谁更年长?”时的表现差异,生动地展示了新范式在面对需要多步推理和工具调用的复杂问题时,如何通过规划、分解、执行、综合的流程得出正确答案,而传统系统则无能为力。
结论
本章总结了论文的核心贡献,其启发性在于清晰地勾勒出了下一代AI驱动搜索引擎的蓝图。论文提出的模块化、多智能体AI搜索范式,通过模拟人类的协作式问题解决流程,有效地克服了传统信息检索(IR)和现有RAG系统的局限性。该范式通过主动规划、动态工具整合和迭代推理,将搜索体验从被动的“文档列表提供者”提升为主动的“问题解决伙伴”,显著降低了用户的认知负担。这项工作不仅集成和优化了学术界与工业界的前沿技术,为未来的AI搜索研究和开发提供了一个结构清晰、内容详实的实践指南,也为如何实现更高效的智能体协作与无缝工具集成等未来研究方向指明了道路。