
《Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation 》
这篇论文的核心是提出了一种名为“Multiverse”的新型生成模型框架,旨在让大型语言模型(LLM)能够实现原生的并行生成。这个框架的灵感来源于一个关键发现:传统的自回归模型在生成长序列(如解题步骤)时,其输出内容在逻辑上已经隐含了可以并行的部分。Multiverse 模型将经典的 MapReduce 计算范式(一种分而治之的思想)内化到了模型结构中,通过三个阶段进行工作:首先是 Map(映射) 阶段,模型自主地分析任务并将其分解为多个子任务;其次是 Process(处理) 阶段,模型并行地执行这些独立的子任务;最后是 Reduce(规约) 阶段,模型将所有并行分支的结果无损地合并,并生成最终结论。为了实现这一框架,研究者们进行了一套完整的“协同设计”,涵盖了数据、算法和系统三个层面,并成功地将一个强大的自回归模型(Qwen-2.5-32B)用极低的成本(1000个样本,3小时训练)转化为了 Multiverse 模型。最终结果表明,该模型在保持与顶尖自回归模型相当的推理性能的同时,由于其并行生成能力,获得了最高可达2倍的推理速度提升。
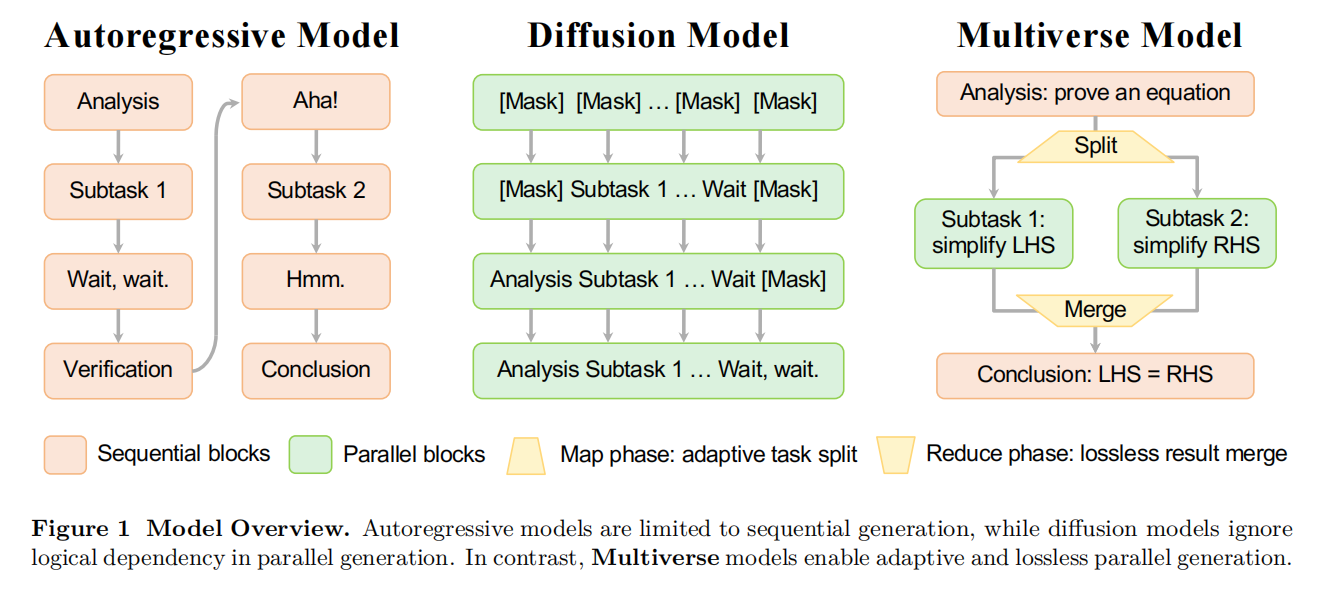
我们能否设计一个模型,让它能“智能地”决定何时拆分任务进行并行处理,何时合并结果,并且整个过程都在模型内部无缝完成?这为 Multiverse 框架的提出奠定了基础,即让模型学会自己做“项目管理”,从单线程工作者进化为高效的多任务团队。
长链思维(CoT)生成:逻辑上是顺序还是并行?
深入分析了现有顶尖模型生成的长篇推理数据。他们发现,超过98%的推理案例中都存在可以并行的部分。他们将这些并行模式分为两类:集体性分支(Collective Branches),比如分析一个问题的多个方面,所有方面的结果最后都要用到;以及 选择性分支(Selective Branches),比如探索多种解题思路,最后只选择最有效的一种。更关键的一步是,他们通过“提示测试”(Prompting Test)和“探针测试”(Probing Test)证明,尽管这些模型能无意识地生成含并列逻辑的内容,但它们实际上无法主动地、显式地去规划和识别这种并行结构。这就像一个人虽然可以说出包含并列关系的话,但他自己并没有意识到“并列”这个语法结构。这个发现非常重要,它说明了现有模型“知其然,而不知其所以然”,从而论证了创造一个能主动理解和运用并行思维的新模型框架的必要性。
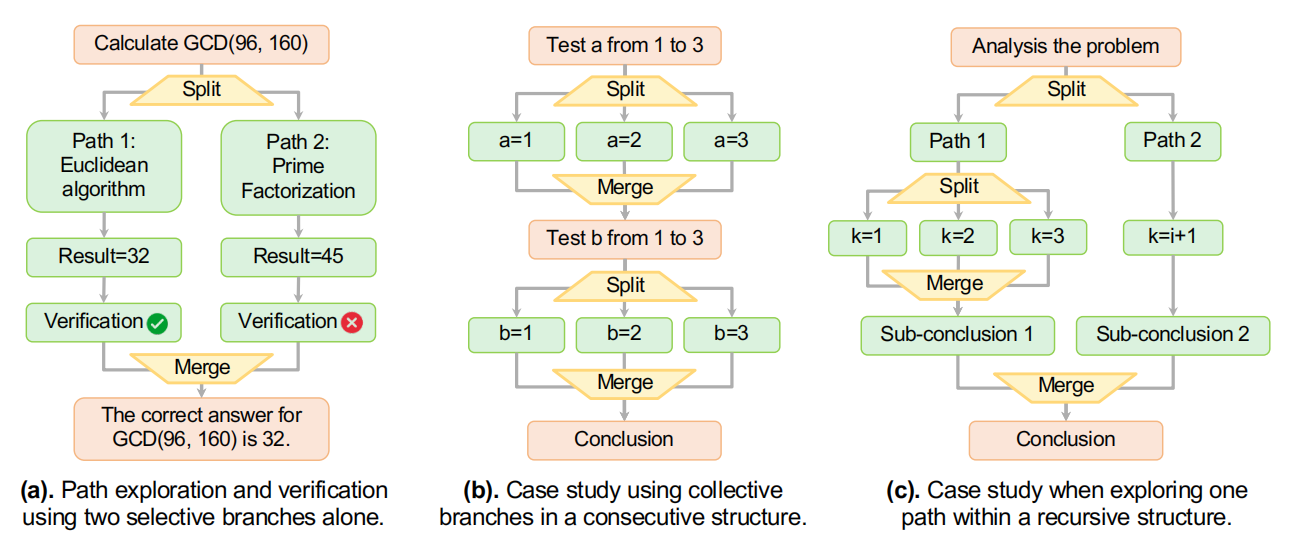
为原生并行生成模型设计 Multiverse
Multiverse 框架的理论核心,最具创造性的做法是将 MapReduce 思想和一套特殊的“控制标签”结合起来,从而在模型层面实现了对生成流程的精确控制。
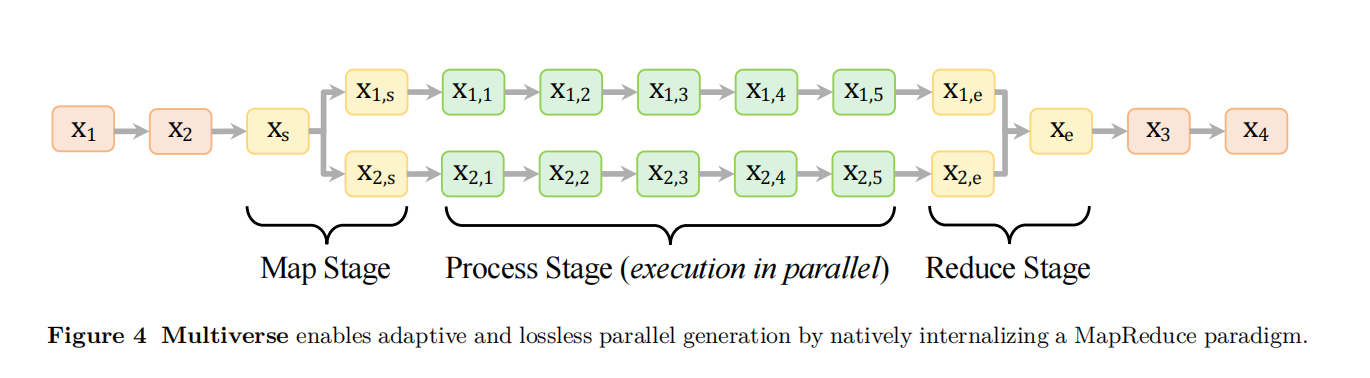
其核心流程分为三步:
1. Map(映射)阶段,模型首先生成一个任务分解计划,就像一个项目经理写下任务大纲;
2. Process(处理)阶段,模型根据计划,在多个独立的“路径”(Path)中并行生成内容,每个路径处理一个子任务;
3. Reduce(规约)阶段,当所有路径都完成后,模型将所有路径的输出信息整合起来,进行总结和最终推理。
为了让模型和推理系统能够“听懂”这个流程,作者设计了一套类似XML的控制标签,例如 <Parallel> 标志着并行块的开始,<Goal> 和 <Outline> 定义了总目标和各个子任务,<Path> 包裹着每个并行的处理过程,而 <Conclusion> 则触发最终的合并与总结。这种设计非常巧妙,它把复杂的并行逻辑控制问题,转化成了一个模型生成特定“指令文本”的问题,让模型能够自我指导其生成过程,实现了“代码即流程”。
构建一个真实世界中的 Multiverse 模型
其核心思想是“数据、算法、系统”三位一体的协同设计,每一步都充满了巧思。
5.1 数据管理 (Data Curation): 最大的难题是“从0到1”——没有现成的并行化训练数据。作者的解决方案“Multiverse Curator”是一个极具启发性的自动化数据处理流水线。它使用一个强大的LLM(Gemini 2.5 Pro)作为“数据标注员”,通过五步提示工程,将现有的海量、高质量的“顺序”推理数据,自动转换为带有并行结构标签的 Multiverse 数据格式。这五个步骤包括:解析为树状摘要、识别并行节点、用控制标签重构、填回原始内容、添加Map/Reduce阶段并重写路径以保证独立性。这个方法极大地降低了数据准备的成本,为训练新架构模型提供了一条捷径。

5.2 算法设计 (Algorithm Design): 挑战在于标准 Transformer 的“因果注意力”(Causal Attention)是为顺序生成设计的。作者提出的“Multiverse Attention”通过两个精巧的修改解决了这个问题:1. 修改注意力掩码 (Attention Mask),使得在一个并行路径(Path)里的Token无法“看到”其他并行路径里的Token,从而保证了路径间的独立性。2. 修改位置编码 (Position Embeddings),让每个并行路径都从相同的位置索引重新开始计算,仿佛它们是同时开始的独立序列。当需要合并时,所有路径再汇集到一个新的、共享的位置上。这个设计的精妙之处在于改动很小,与原有注意力机制高度兼容,因此可以利用预训练好的模型权重,仅通过少量数据微调就能快速学会新的并行注意力模式,实现了“数据高效”。
5.3 系统实现 (System Implementation): 算法和数据就绪后,还需要一个能“执行”并行指令的推理引擎。作者基于现有开源引擎(SGLang)开发了“Multiverse Engine”。这个引擎的关键是一个“解释器”,它能实时读取模型生成的控制标签。当检测到 <Parallel> 标签时,它会自动创建多个并行的生成流,并利用前缀共享(Radix Attention)等技术高效复用KV缓存。当所有并行路径都完成后,引擎会自动将它们的KV缓存状态合并,并送入 <Conclusion> 标签,让模型继续进行顺序的总结生成。这个系统真正打通了从模型“意图”到硬件“执行”的最后一公里,实现了“训推一体”。
实验
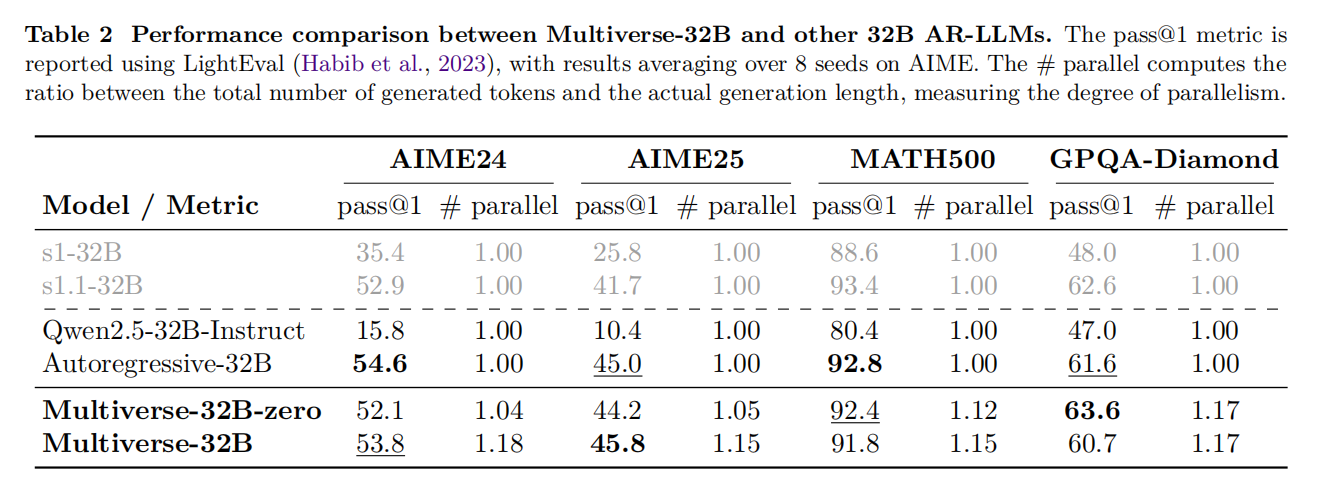
本章通过实验结果证明了 Multiverse 框架的有效性。最具说服力的发现是,经过少量数据微调的 Multiverse-32B 模型,在多个高难度推理基准测试(如AIME数学竞赛题)上,其准确率(pass@1)与使用相同基础模型、在原始顺序数据上训练的自回归模型不相上下,甚至有时还略有超出。这表明,引入并行结构并没有损害模型的推理能力。更有价值的发现来自于“预算控制实验”:在给定相同的生成时间(即相同的上下文长度限制)下,Multiverse 模型因为可以并行生成更多token,所以其最终性能平均高出1.87%。这直观地展示了并行化带来的“性价比”优势。他们还引入了一个衡量并行度的指标 # Parallel(生成总token数与顺序生成步数的比值),数据显示模型确实在按预期进行并行生成。
效率分析
这一章深入分析了并行化带来的实际速度提升。最核心的结论是,模型的并行度(Parallel)与每个Token的生成延迟(Latency per token)之间存在明显的反比关系,即并行度越高,生成每个字的平均时间就越短。实验数据显示,在大多数情况下,并行化带来了平均18.5%的加速,在一些并行度较高的例子中,速度提升可达2.1倍。另一项重要的测试表明,这种加速效果在不同的批处理大小(Batch Size,从1到128)下都保持稳定。这说明 Multiverse 模型的效率增益具有很好的可扩展性,无论是在线服务单个用户(小batch)还是离线处理大量数据(大batch),都能从中受益。
局限性与更广泛影响
作者也坦诚地指出了局限性,例如目前主要在推理任务上进行了验证,未来可以探索更多样的数据类型;同时,当前还只是监督微调,未来若能结合强化学习,或许能让模型探索出更复杂、更高效的并行策略。在更广泛的影响方面,作者强调,这种并行化技术能显著提升GPU利用率,尤其是在长下文、小批量的场景下,能有效降低延迟和能耗,为解决过去因耗时过长而难以处理的超复杂问题提供了一条可行的道路,是通往更强大人工智能(ASI)的一个有希望的方向。