
MiniMax-M1 是全球首个开放权重的大规模混合注意力推理模型 ,它通过创新的架构设计和训练方法,旨在高效地扩展模型的测试时计算能力,以处理复杂任务 。该模型的核心动力源于一个结合了混合专家(MoE)与Lightning注意力(Lightning Attention)机制的混合架构 。M1 模型基于其前身 MiniMax-Text-01 开发而来 ,总参数量达到 4560 亿,但每个词元(token)仅激活 459 亿参数 ,从而实现了高效率。得益于其架构,M1 原生支持高达 100 万词元的超长上下文 ,并且计算成本极低,例如,在生成 10 万词元长度的内容时,其计算量仅为 DeepSeek R1 的 25% 。为了训练模型卓越的推理能力,团队采用了大规模强化学习(RL) ,并为此开发了一种名为 CISPO 的新颖 RL 算法 。该算法通过裁剪重要性采样权重而非词元更新来稳定训练,表现优于其他竞争算法 。这种高效的架构与算法相结合,使得 M1 的完整强化学习训练在 512 个 H800 GPU 上仅用三周便得以完成,成本约为 53.47 万美元 。团队公开发布了两个版本,分别拥有 40K 和 80K 的“思考预算” ,在标准基准测试中,其表现与 DeepSeek-R1 和 Qwen3-235B 等顶尖开源模型相当或更优,尤其在复杂的软件工程、智能体工具使用和长上下文任务上展现出明显优势 。
为可扩展的强化学习做准备
这一章的启发点在于它揭示了在进行高成本的强化学习(RL)之前,扎实的“地基”工作是多么重要,以及如何高效地打好这个地基。这个准备工作分为两个关键步骤。
第一步是持续预训练 (Continual Pre-training),目标是增强基础模型的内在推理能力。他们的做法是,在原有模型基础上,再用 7.5 万亿个精心筛选的、侧重于推理的词元进行训练。这里的关键操作是,他们优化了数据处理流程,特别提高了数学和代码类高质量数据的比例至 70%,并且严格避免使用合成数据,以保证数据质量和多样性。一个非常重要的实践经验是,为了训练超长文本(100 万词元),他们没有一步到位,而是采用分阶段逐步延长训练文本长度的策略(从 32K 开始),有效避免了训练过程中可能出现的梯度爆炸问题。
第二步是监督微调 (Supervised Fine-Tuning, SFT),目标是为模型注入特定的“思维模式”,即“思维链”(Chain-of-Thought)。他们的做法是,精心筛选了大量包含长篇思考过程的样本,覆盖数学、代码、问答等多个领域(其中数学和代码占 60%),让模型在强化学习开始前就“学会”如何进行有条理的思考,为后续更高效、更稳定的 RL 训练奠定了坚实的基础。
高效的强化学习扩展:算法与Lightning注意力
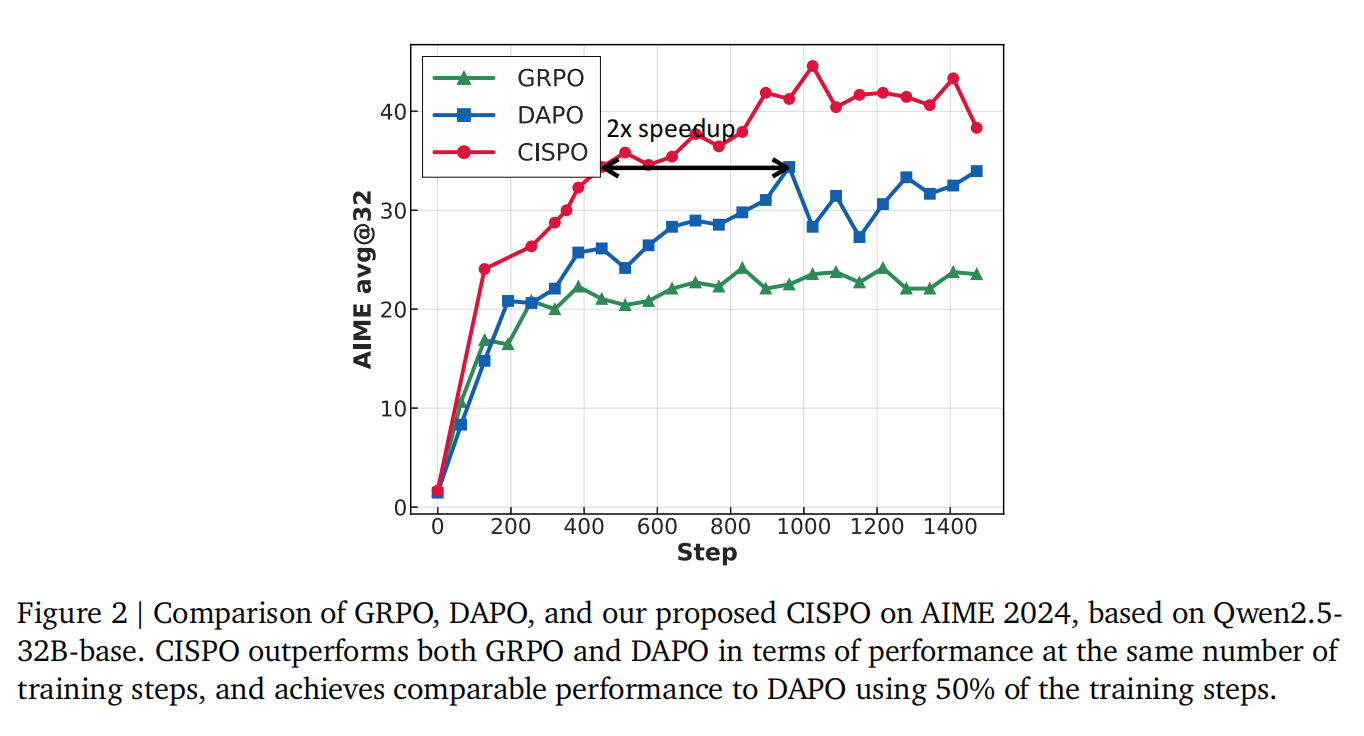
首先,他们提出了CISPO 算法来解决一个棘手的问题。在使用传统 PPO/GRPO 算法时,他们发现模型在学习过程中会“丢弃”掉一些出现概率低但对推理至关重要的“反思性”词元(如“嗯,让我想想”、“重新检查一下”),这严重影响了模型学习长链条推理的能力。CISPO 算法的巧妙之处在于,它不再像 PPO 那样通过裁剪词元的更新来稳定训练,而是转为裁剪“重要性采样权重”。这样一来,即使是罕见的词元也能持续为模型的梯度更新做出贡献,保证了所有信息的有效利用。其目标函数为:
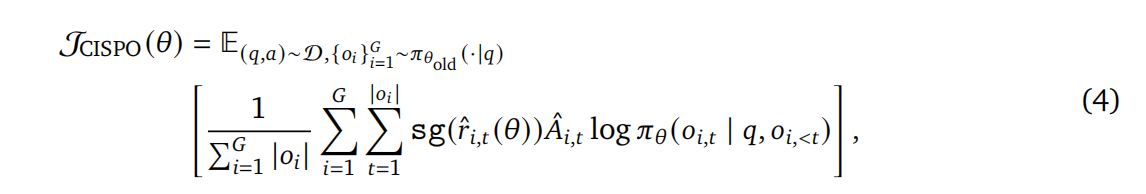
其中

是被裁剪后的重要性权重。
其次,本章还分享了在混合注意力架构上进行大规模强化学习时遇到的独有挑战和解决方案,这些都是宝贵的“踩坑”经验:
计算精度不匹配:他们发现训练和推理代码算出的词元概率有微小差异,这个差异足以导致奖励无法增长。通过逐层排查,他们定位到问题出在模型最后的输出层(LM head),并将其计算精度提升到 FP32,成功解决了问题。
优化器超参数敏感:他们发现模型的梯度值范围跨度极大,且相邻迭代的梯度相关性弱。基于这一观察,他们没有使用默认的 AdamW 优化器参数,而是手动设定了 $\beta_{1}=0.9, \beta_{2}=0.95, eps=1e-15$,从而稳定了训练。
通过重复检测进行提前截断:为了防止模型在训练中生成病态的、无限重复的超长回答,他们设计了一个巧妙的启发式规则:如果连续 3000 个词元的生成概率都高于 0.99,就提前终止本次生成。这既避免了模型崩溃,又提高了吞吐量。
用多样化数据扩展强化学习
他们将数据分为两大类,并为每一类都设计了精细的处理流程。第一类是有明确规则可验证的任务,这是模型推理能力的核心。他们为数学、逻辑推理、编程和软件工程等领域都构建了高质量的数据集。其中最具启发性的做法是:对于数学题,他们会用模型预先筛选,只保留那些有一定难度(pass@10 介于 0 和 0.9 之间)的题目;对于逻辑题,他们利用自研框架 SynLogic 合成数据,并根据模型能力动态调整难度;对于软件工程,他们搭建了一个真实的沙箱环境,让模型在模拟环境中解决 GitHub 上的真实问题,并根据代码能否成功运行来获得奖励。第二类是需要模型来提供反馈的通用任务。对于这类任务,他们训练了一个“生成式奖励模型”(GenRM)。这里最关键的洞察是,他们发现奖励模型存在“长度偏见”,即倾向于给更长的回答打高分,而不管内容质量。他们的解决方案是,在强化学习训练的全程中,持续在线监控这种偏见。一旦发现策略模型开始为了刷分而无意义地增长回答长度,他们就立刻对奖励模型进行重新校准。最后,他们还采用了课程学习的策略,先用规则验证的推理任务进行训练,然后逐步混入通用领域的任务,这确保了模型在扩展通用能力的同时,不会忘记核心的推理技能。
将强化学习扩展到更长的思考
如何将一个已经训练好的模型的能力边界进一步推向极限,即从支持 4万 词元的输出长度扩展到 8万。这个过程并非简单的继续训练,而是包含了一套精细的策略。首先,在数据策略上,他们利用已经训练好的 40K 模型来对数据进行二次筛选,剔除已经被轻松解决的样本,并增加了更难的数学和代码题的比例。一个重要的发现是,他们减少了合成推理数据的比例,因为发现这类数据在长文本生成后期会破坏模型的稳定性。其次,在长度扩展策略上,他们采用了“分阶段窗口扩展”的稳健方法,从 40K 开始,逐步增加到 48K、56K,直到 80K。只有当模型在当前长度下的困惑度收敛,且生成的文本长度开始接近当前上限时,才会进入下一阶段。最后,他们还解决了扩展过程中出现的训练不稳定问题。他们发现,在长序列生成的后半部分,模型容易出现“模式崩溃”(即输出乱码)。经过分析,根源在于负样本(回答错误的样本)的长度增长速度远快于正样本,导致在序列末端积累了过多的负梯度。他们的解决方案是三管齐下:1)利用前文提到的重复检测来提前终止;2)结合使用样本级损失和词元级归一化来平衡正负样本的影响;3)减小梯度裁剪的阈值和 CISPO 算法中的 $\epsilon_{high}^{IS}$ 参数,进一步稳定生成过程。
评估
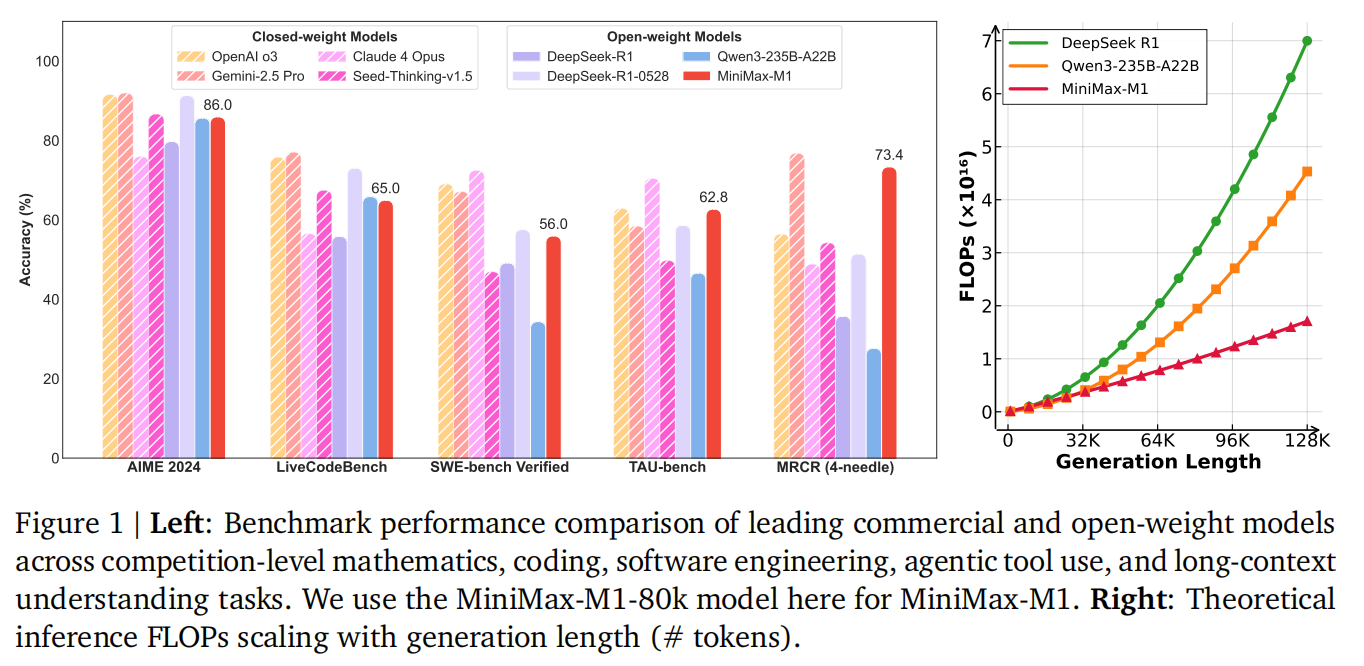
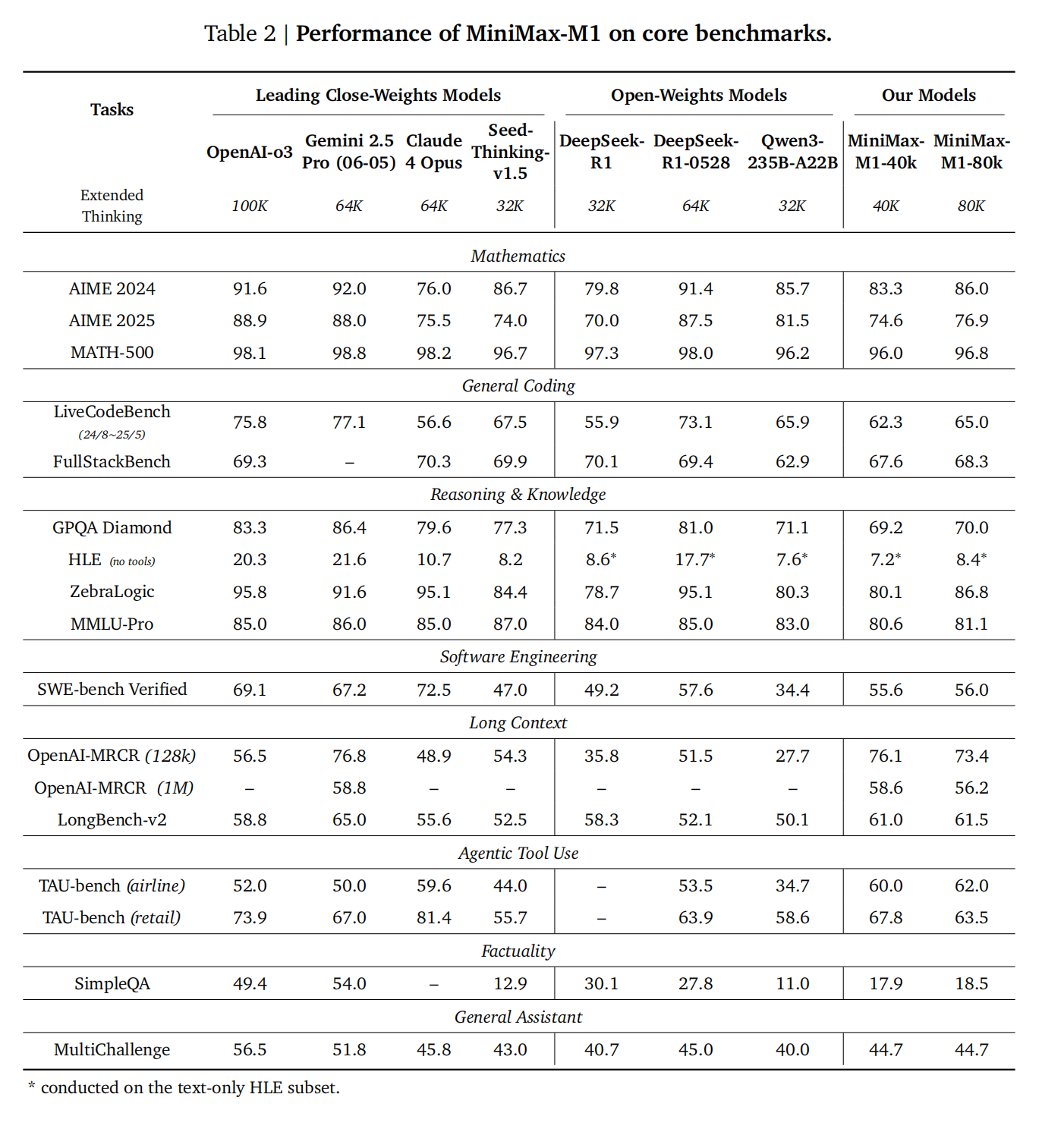
一个模型的真正实力需要通过多维度、特别是在复杂的真实场景中来检验。评估结果显示,MiniMax-M1 不仅在数学、代码等传统强项上与世界顶尖的开源模型并驾齐驱,更重要的是,在那些能真正发挥其长处(长上下文、长时程思考)的领域,它表现出了统治级的性能。例如,在软件工程(SWE-Bench)、长上下文理解(MRCR)和智能体工具使用(TAU-Bench)这三个更接近真实世界应用的复杂场景中,M1 模型显著超越了其他所有开源模型,甚至在长上下文任务上超过了 OpenAI o3 和 Claude 4 Opus 等顶尖闭源模型。此外,80K 版本的模型在绝大多数基准上都优于 40K 版本,这清晰地验证了“扩展测试时计算量(即允许模型进行更长的思考)能带来性能提升”这一核心假设。
结论与未来工作
这篇工作的核心贡献是,他们不仅发布了==世界上第一个采用Lightning注意力机制的大规模开源推理模型,还配套提供了创新的 RL 算法(CISPO)以及一整套宝贵的、经过实践检验的训练方法论==。展望未来,研究者认为,随着真实世界任务变得越来越复杂(例如自动化公司工作流、进行科学研究),对能够在多轮交互中整合长篇信息的智能体的需求会越来越大。==像 MiniMax-M1 这样在架构上为高效长序列处理而生的模型,将为此类下一代智能体的开发提供一个独特且强大的基础平台==。这为后续的研究者指明了一个充满潜力的方向:模型的价值不仅在于其知识量,更在于其高效运用知识进行复杂推理和与环境交互的能力。