
《Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities》
本报告介绍了Gemini 2.X模型家族,包括Gemini 2.5 Pro和Gemini 2.5 Flash,以及早期版本Gemini 2.0 Flash和Flash-Lite。这一代模型原生支持多模态,具备先进的思维推理、长上下文处理和工具使用能力,能够处理超过100万个token的文本、音频、图像、视频甚至整个代码库。Gemini 2.5 Pro是目前最强大的模型,在编码和推理基准测试中达到了SOTA(State-of-the-Art)性能,并擅长多模态理解,能够处理长达3小时的视频内容。Gemini 2.5 Flash则在计算和延迟要求较低的情况下提供出色的推理能力。Gemini 2.0 Flash和Flash-Lite则在高性价比和低延迟方面表现优异。这些模型共同覆盖了模型能力与成本的帕累托前沿,使用户能够探索复杂Agent问题解决的边界。
模型架构
Gemini 2.5模型采用了稀疏混合专家(MoE)Transformer架构,原生支持文本、视觉和音频输入。MoE模型通过动态路由token到参数子集(专家)来激活部分模型参数,从而在计算和token服务成本上解耦了总模型容量。架构的改进显著提升了Gemini 2.5的性能。Gemini 2.5系列在提升大规模训练稳定性、信号传播和优化动态方面取得了重大进展,从而在预训练阶段就显著提升了性能。Gemini 2.5模型在处理长上下文查询方面也取得了进展,Gemini 2.5 Pro在处理长达1M token的输入序列上超越了Gemini 1.5 Pro。此外,Gemini 2.5在视觉处理方面的架构改进显著提升了图像和视频理解能力,包括能够处理3小时长的视频,并将演示视频转化为交互式编码应用。小型模型(Flash及以下)利用了蒸馏技术,通过近似k稀疏分布来降低教师模型下一代token预测分布的存储成本,从而在质量和降低服务成本之间取得了平衡。
数据集
Gemini 2.0和2.5的预训练数据集是一个大规模、多样化的数据集合,涵盖了广泛的领域和模态,包括公开可用的网络文档、代码(各种编程语言)、图像、音频(包括语音和其他音频类型)和视频。Gemini 2.0的数据截止日期是2024年6月,Gemini 2.5是2025年1月。相较于Gemini 1.5的预训练数据集,2.0和2.5采用了新的方法来改进数据过滤和去重,以提高数据质量。后训练数据集与Gemini 1.5类似,包含经过精心收集和审查的指令调优数据,以及多模态数据、配对的指令和响应,此外还有人类偏好和工具使用数据。
训练基础设施
Gemini 2.X模型家族是首个在TPUv5p架构上训练的模型,采用了跨多个数据中心的Google TPUv5p加速器上的同步数据并行训练。与Gemini 1.5相比,主要的软件预训练基础设施改进在于弹性和SDC(静默数据损坏)错误缓解。Slice-Granularity Elasticity(切片粒度弹性)允许系统在局部故障时自动以较少数量的TPU芯片“切片”继续训练,每次中断只损失几十秒的训练时间,而无需等待机器重新调度。Split-Phase SDC Detection(分阶段SDC检测)利用轻量级确定性重放立即重复任何可疑指标的步骤,并通过比较每个设备的中间校验和来定位数据损坏的根本原因,从而在几分钟内识别并排除有间歇性SDC的加速器,显著减少了调试停机时间和训练步骤回滚。这些技术的实现得益于Pathways系统单一控制器的设计,该设计允许所有加速器通过一个具有全局系统视图的Python程序进行协调。
后训练
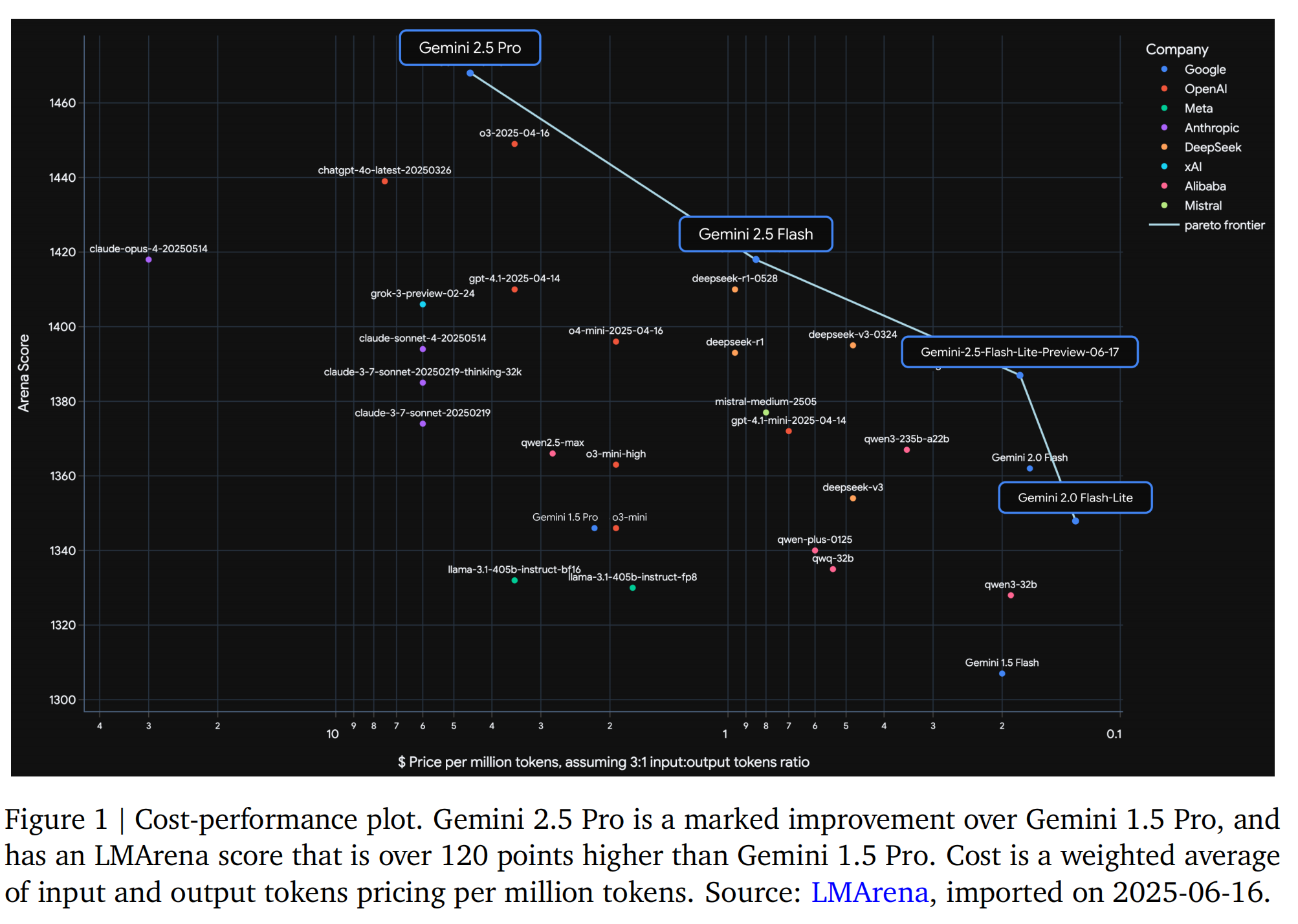
Gemini 1.5发布以来,后训练方法取得了显著进展,主要集中在监督微调(SFT)、奖励建模(RM)和强化学习(RL)阶段的数据质量。关键做法是利用模型本身辅助这些过程,实现更高效和精细的质量控制。此外,报告增加了RL的训练计算资源,实现了模型行为的更深层次探索和完善。这与对可验证奖励和基于模型的生成奖励的关注相结合,提供了更复杂和可扩展的反馈信号。RL流程的算法变化也提高了长时间训练的稳定性。这些进展使Gemini 2.5能够从更多样化和复杂的RL环境中学习,包括那些需要多步动作和工具使用的环境,从而实现了全面性能提升,Gemini 2.5 Flash和Pro在LMArena ELO分数上比Gemini 1.5对应模型提高了120多分,并在其他前沿基准测试中取得了显著进步。
思维 (Thinking)
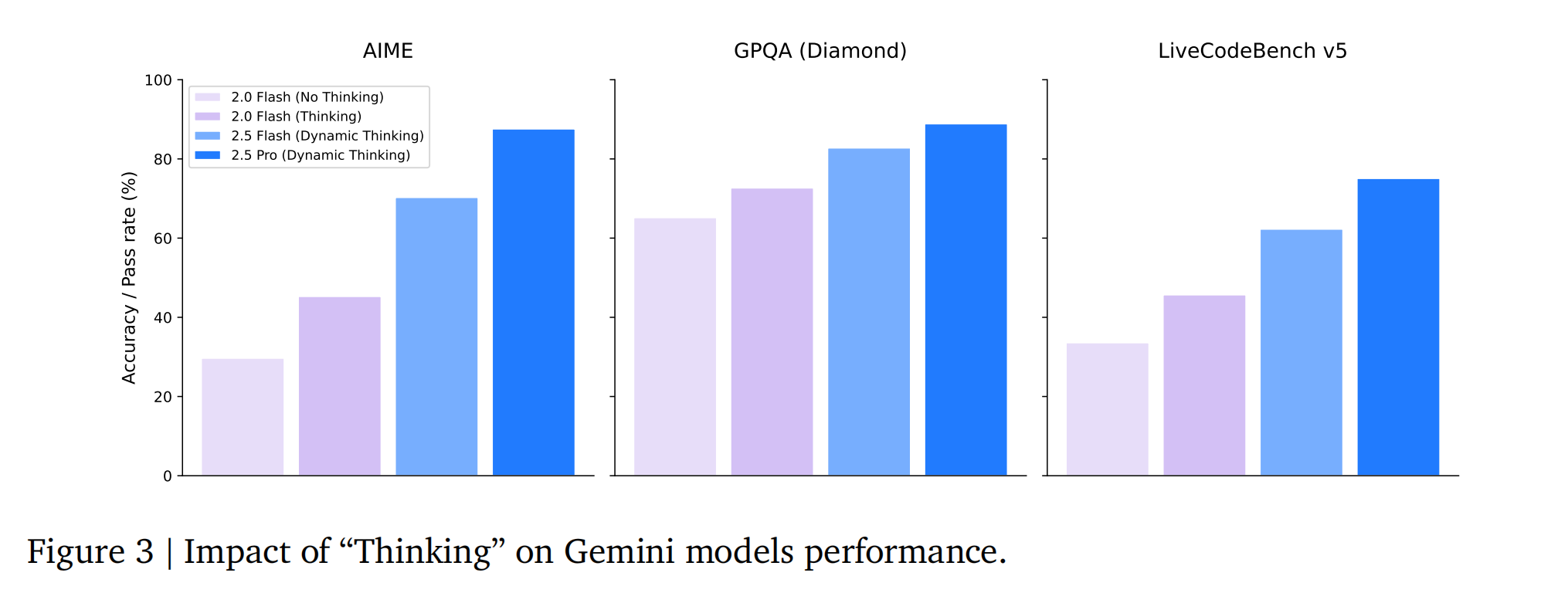
过去的Gemini模型在用户查询后立即生成答案,这限制了模型在推理问题上花费的推理时间(思维)。Gemini Thinking模型通过强化学习进行训练,在推理时利用额外的计算资源以获得更准确的答案。最终模型能够在回答问题或查询之前进行数万次前向传递的“思考”阶段。训练方案从最初的实验性思考模型Gemini 2.0 Flash Thinking(2024年12月发布)演变为Gemini 2.5 Thinking系列,后者在所有领域原生集成了思考能力,实现了全面的更强推理性能,并能随着推理时间的增加进一步提升性能。Gemini 2.5 Thinking模型将思维能力与原生多模态输入(图像、文本、视频、音频)和长上下文(1M+ token)等其他Gemini能力相结合。模型可以自行决定思考时长,用户也可以设置思考预算来平衡性能和成本。
特定能力改进
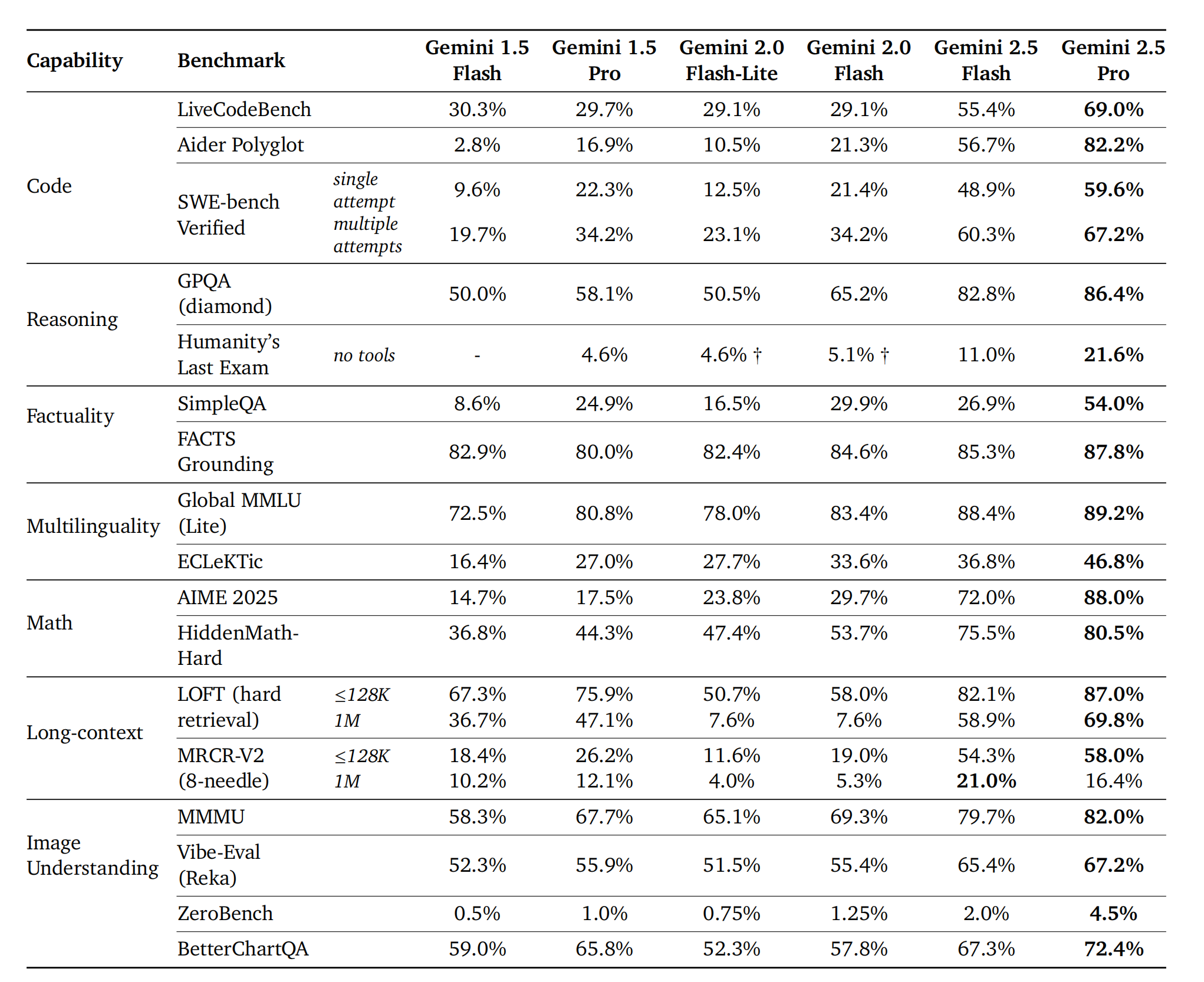
代码 (Code):Gemini 2.0和2.5在开发优先级上转向提供实际价值,赋能用户在复杂、多模态软件环境中解决实际挑战和实现开发目标。预训练阶段,Google DeepMind增加了代码数据(来自代码库和网络)的数量和多样性,扩展了覆盖范围并提高了计算效率。同时,大幅增强了评估代码能力的指标体系,以更好地预测模型在实际应用中的表现。后训练阶段,开发了新的训练技术,融入了推理能力,并精心策划了多样化的工程任务数据集。这些努力使Gemini在IDE功能、复杂多步操作的代码Agent用例以及端到端Web和移动应用开发等多模态交互场景中取得了显著进步。Gemini在LiveCodeBench和Aider Polyglot等基准测试中表现优异,并在LMArena WebDev Arena上取得了大幅提升,显著增强了UI和Web应用开发及复杂Agent工作流的实际应用。
事实性 (Factuality):确保模型对信息查询的回答具有事实性是Gemini模型开发的核心支柱。Gemini 1.5专注于增强模型的世界知识和忠实于上下文的能力。Gemini 2.0和2.5扩展了范围,解决了多模态输入、长上下文推理和模型检索信息。通过原生调用Google搜索等工具,Gemini 2.0和2.5能够制定精确查询并合成带有来源的新信息,并通过高级推理将搜索能力与内部思维过程结合,回答复杂的多跳查询和执行长周期任务,并验证事实准确性。这些模型现在为Google的AI概览和Gemini应用程序中的超过15亿月活跃用户提供支持,并在事实性基准测试中展现了最先进的性能。
长上下文 (Long context):建模和数据方面的进步提升了百万长度上下文的质量,并重新设计了内部评估,使其更具挑战性,以指导建模研究。通过针对LOFT、MRCR-V2等挑战性检索任务、长上下文推理任务以及VideoMME等多模态任务进行优化,Gemini 2.5模型在所有这些任务上都比以前的Gemini 1.5模型有了显著改进,并实现了最先进的质量。例如,Gemini 2.5 Pro能够持续从长达46分钟的视频中回忆起1秒的视觉事件。
多语言 (Multilinguality):Gemini的多语言能力自1.5版本(已涵盖400多种语言)以来经历了深刻演变。这种转变源于一个整体战略,该战略精心改进了预训练和后训练数据质量,推进了分词技术,创新了核心建模,并执行了有针对性的能力提升。在印度语、中文、日语和韩语等语言中影响尤为显著,通过数据质量和评估的专门优化,这些语言的质量和解码速度都得到了显著提升。因此,用户受益于显著增强的语言依从性、忠实于所请求输出语言的响应以及生成质量和跨语言事实性的显著改进,从而巩固了Gemini在不同语言环境中的可靠性。
音频 (Audio):Gemini 1.5专注于原生音频理解任务,如转录、翻译、摘要和问答。Gemini 2.5除了理解外,还训练执行音频生成任务,如文本转语音或原生视听转音频对话。为实现低延迟流式对话,模型引入了因果音频表示,允许音频流进出Gemini 2.5。这些能力源于增加了200多种语言的预训练数据,并开发了改进的后训练配方。通过改进的后训练配方,模型将高级能力(如思维、情感对话、上下文感知和工具使用)集成到Gemini的原生音频模型中。
视频 (Video):报告显著扩展了预训练和后训练视频理解数据,提升了模型的视听和时间理解能力。模型经过训练,在每帧66个视觉token(而非258个)的情况下仍能保持竞争力,从而可以在1M token的上下文窗口内处理约3小时的视频,而非1小时。这些变化解锁了两个以前无法实现的新应用:从视频创建交互式应用程序(例如测试学生对视频内容理解的测验),以及创建p5.js动画以展示视频中的关键概念。
作为Agent的Gemini:深度研究 (Gemini as an Agent: Deep Research):Gemini深度研究是一个基于Gemini 2.5 Pro模型构建的Agent,旨在战略性地浏览网页,并为即使是最小众的用户查询提供知情答案。该Agent经过优化,可执行任务优先级划分,并能识别何时在浏览时遇到死胡同。自2024年12月首次发布以来,Gemini深度研究的功能得到了大规模提升。例如,其在《人类的最后一次考试》基准测试中的表现从2024年12月的7.95%提升至2025年6月的SOTA分数26.9%(更高计算量下达到32.4%)。
Gemini 2.5之路
在通往Gemini 2.5 Pro的道路上,Google DeepMind通过实验性模型与用户进行测试,以改进训练方案。报告简要讨论了其他模型,包括Gemini 2.0 Pro(2025年2月发布,具有最强的编码性能和理解能力,以及最大的200万token上下文窗口)和Gemini 2.0 Flash原生图像生成模型(2025年3月发布,通过与图像生成能力的深度集成,解锁了图像生成和编辑的新体验,支持多步对话编辑和文本-图像交错生成)。Gemini 2.5音频生成模型(2025年6月推出)提供可控的TTS和原生音频对话功能,支持80多种语言的语音风格控制和多说话人生成,并支持工具使用和函数调用。Gemini 2.5 Flash-Lite(2025年6月发布)作为经济高效的模型,提供了超低延迟和高吞吐量,并具备Gemini 2.5的核心能力,如思维预算控制、Google搜索和代码执行工具连接、多模态输入和100万token上下文长度。Gemini 2.5 Pro Deep Think则通过“深度思考”这一新颖推理方法,在响应生成过程中自然融合并行思考技术,在奥林匹克数学、竞技编码和多模态理解等挑战性基准测试中取得了最先进的性能。
后续是一些评估,案例,安全方面的操作