《Interleaved Reasoning for Large Language Models via Reinforcement Learning》
这篇论文的核心思想是解决大型语言模型在进行长链式思考(CoT)时响应速度慢(即“首个token时间”TTFT过长)和容易中途出错的问题。研究者提出了一种名为“交错推理”(Interleaved Reasoning)的全新训练模式,通过强化学习(RL)来引导模型在“思考”和“回答”之间来回切换。这种方法不仅能将用户的等待时间(TTFT)平均减少超过80%,还能将解题的正确率(Pass@1)提升高达19.3%。最关键的是,这种方法不依赖任何外部工具,并且在仅用问答和逻辑推理数据集训练后,模型能在数学(MATH)、物理(GPQA)等它从未见过的复杂推理任务上表现出色,展现了强大的泛化能力。
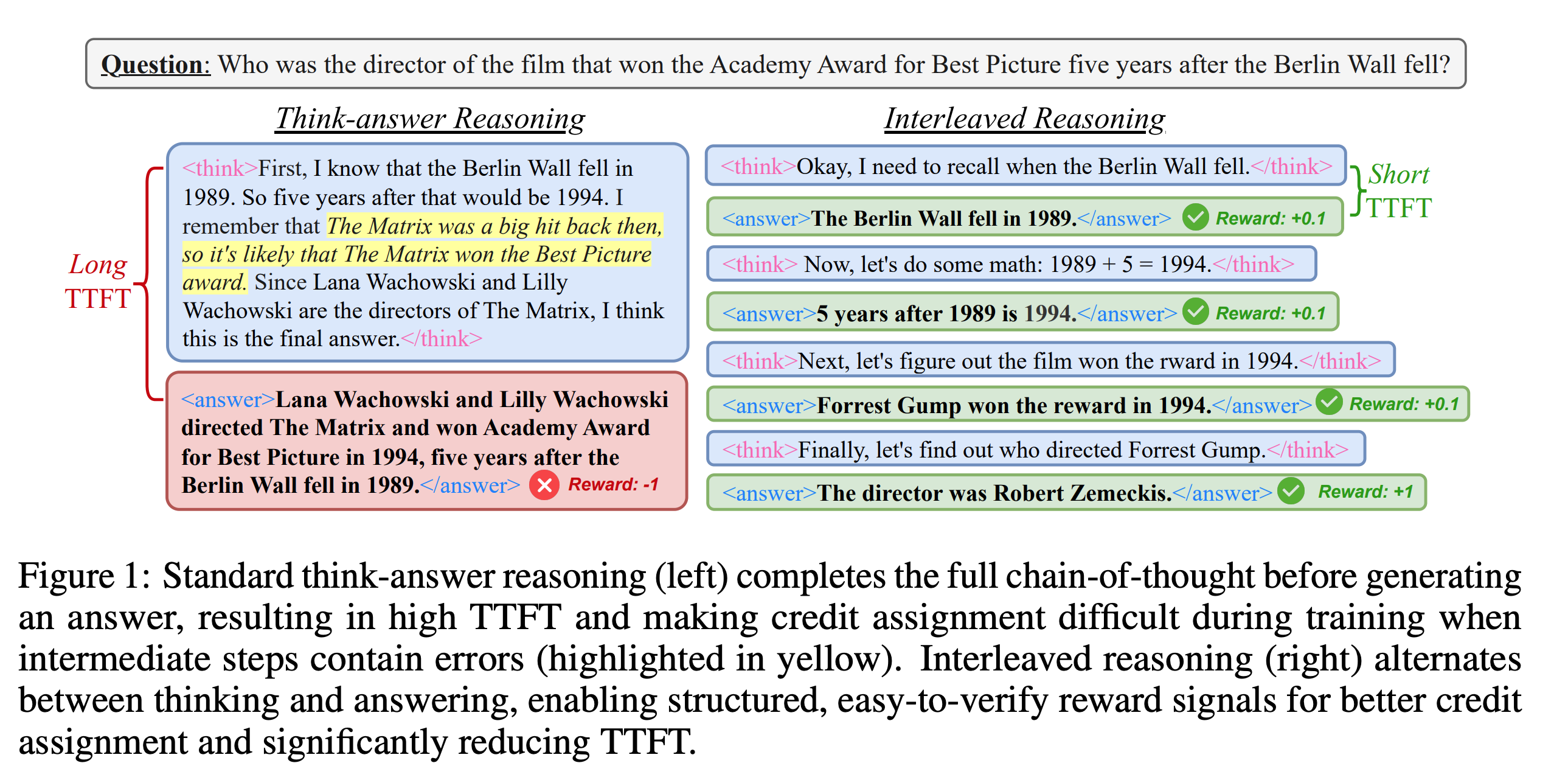
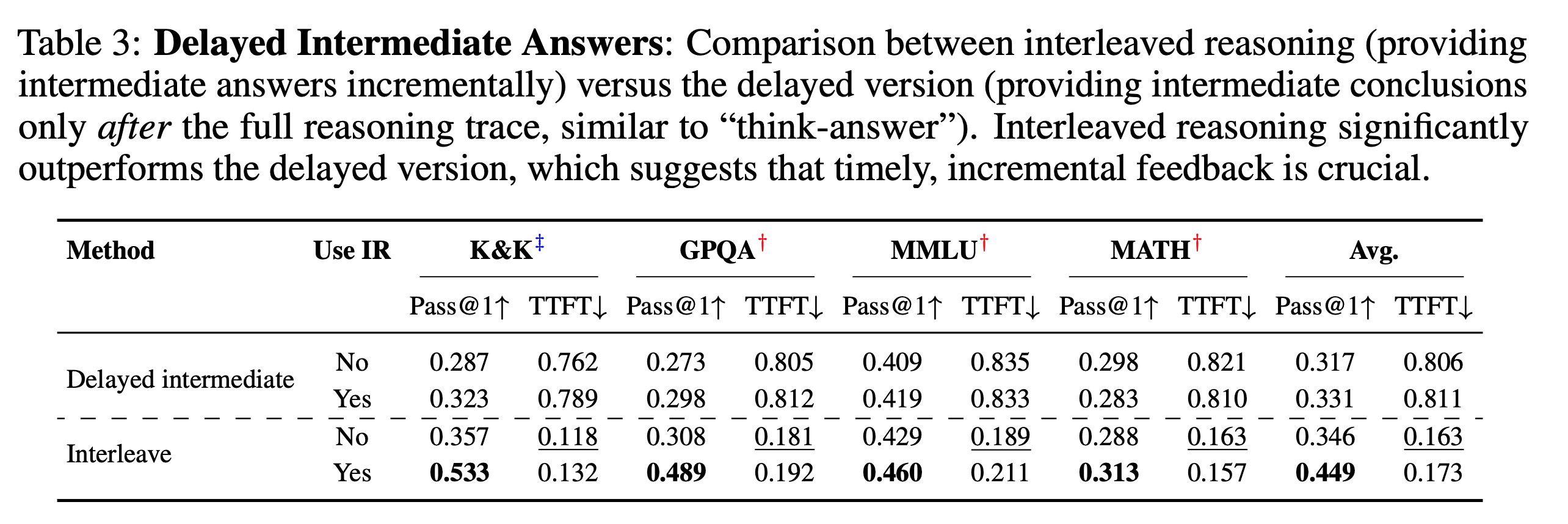
“先思考后回答”(think-answer)模式存在两个主要弊端。首先,模型需要生成一长串完整的思考过程后才能给出第一个字的答案,这在对话式应用中会造成明显的延迟,影响用户体验。其次,由于奖励信号只在最终答案产生后才出现,如果模型在思考的早期步骤就犯了错,这个错误会一直延续下去,导致最终结果不准确,造成所谓的“过度思考”或“思考不足”。作者们从人类交谈中获得启发,我们通常会给出阶段性的反馈来表示理解。因此,他们提出“交错推理”,让模型把复杂问题分解成小步骤,每完成一步就给出一个小结(sub-answer),这样不仅能立即给用户反馈,还能利用这些中间答案作为更密集的监督信号来指导后续的推理,从而让训练更有效。
目前,利用强化学习提升模型推理能力主要依赖两种奖励模型:结果奖励模型(ORM)只看最终答案对错,过程奖励模型(PRM)则对思考过程中的每一步进行打分。PRM虽然能提供更密集的反馈,但往往需要大量人工标注或训练一个额外的复杂模型,实施起来很困难。本文提出的方法巧妙地结合了两者的优点:它像PRM一样关注中间步骤,但实现上却像ORM一样简单,仅使用基于规则的奖励来给正确的中间答案“记功”,而无需一个专门的奖励模型。这与其他工作要么依赖外部工具(如搜索引擎),要么只关注缩短推理长度不同,本文更侧重于激发和利用模型自身生成可验证的中间答案的能力。
为交错推理训练大语言模型

如何训练模型学会“交错推理”。其关键步骤如下:首先,他们定义了一种新的交互模式,通过在<think>和<answer>这两个特殊标签中引导模型进行思考和回答,形成一种<think>...<answer>...<think>...<answer>...的交错生成格式。其次,他们将这个过程构建为一个强化学习问题,其目标函数为:
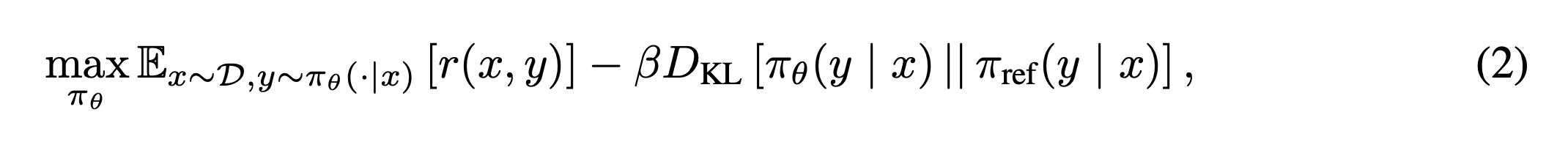
即在最大化奖励的同时,通过KL散度惩罚项防止模型偏离原始模型太远。最关键的创新在于其奖励设计,特别是“条件性中间准确率奖励”。研究发现,如果一开始就对不成熟的中间步骤给予奖励,模型可能会为了局部正确而牺牲最终的全局正确性。因此,他们设计了一个巧妙的条件机制:只有当模型的最终答案正确、输出格式合规、且在当前批次的学习中表现出进步时,才会对正确的中间步骤给予额外奖励。其奖励函数可以表示为:
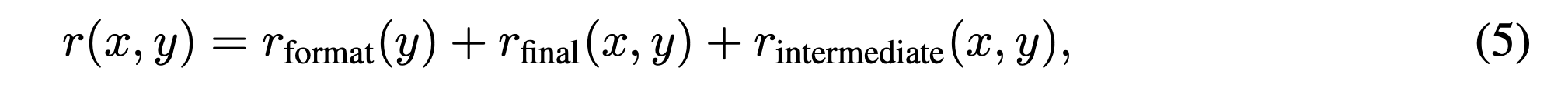
其中中间奖励$r_{intermcdiate}$是有条件触发的。
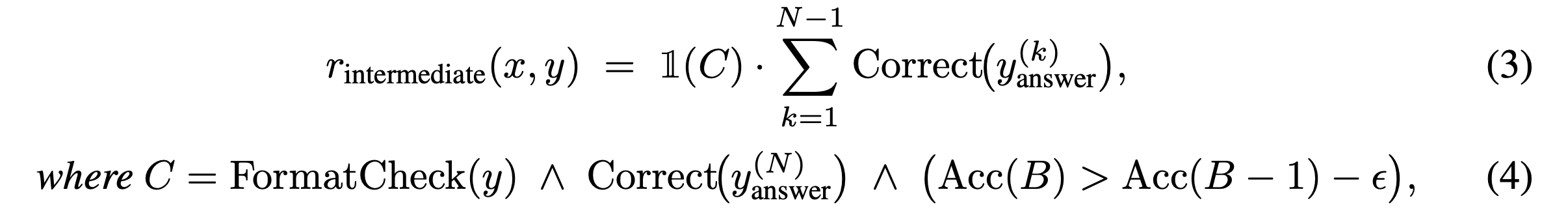
这种“扶优扶强”的策略确保了模型首先学会走对路,然后再学习如何把路走得更漂亮、更高效。
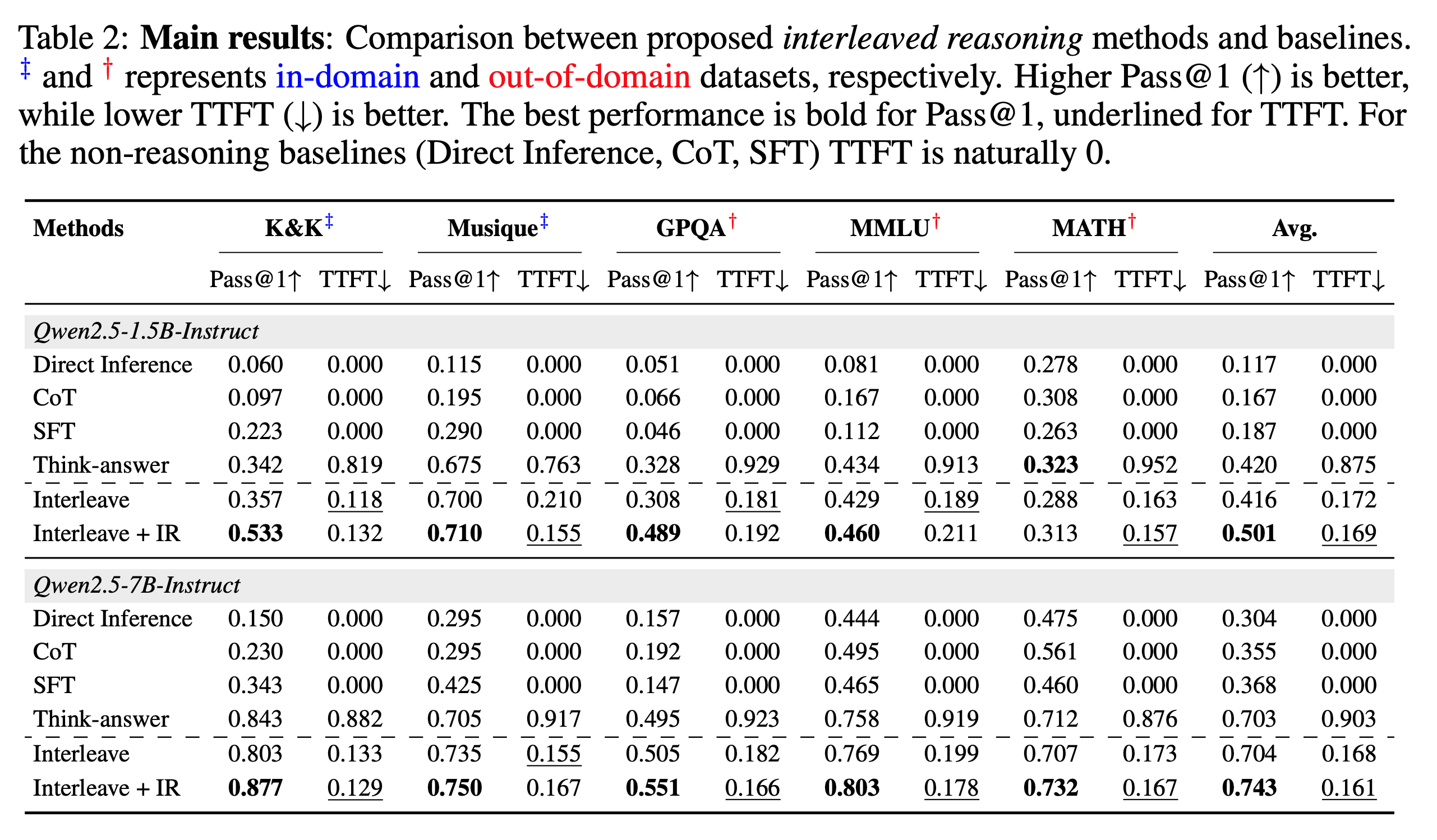
主要实验
实验部分验证了“交错推理”方法的有效性。研究者们使用了15亿和70亿参数的Qwen2.5模型,并在两类数据集上进行了测试:一类是用于训练的“域内”数据集(如逻辑题K&K和多跳问答Musique),另一类是模型从未见过的“域外”数据集(如GPQA、MMLU和MATH)来检验其泛化能力。他们将自己的方法(Interleave + IR,即带中间奖励的交错推理)与多种基线方法(如直接回答、标准链式思考CoT、以及标准的“先思考后回答”式强化学习)进行对比。结果非常显著:与“先思考后回答”的基线相比,他们的方法在所有数据集上都实现了超过80%的TTFT(首个token时间)降低,这意味着用户能快大约五倍得到有用的信息。同时,Pass@1准确率也得到了显著提升,尤其是在15亿参数的模型上相对提升了19.3%。这证明了“交错推理”不仅大幅提升了模型的响应速度和互动性,还实实在在地增强了其推理的准确性。