
《Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning》Qwen团队和清华LeapLab团队出品 👍
这篇论文的核心观点是,在通过强化学习(RL)提升大语言模型(LLM)的推理能力时,并非所有词元(token)都同等重要。研究者发现,在模型的推理过程中,只有一小部分“高熵”的少数词元(大约20%)扮演着关键的“岔路口”角色,引导着推理的方向,而大部分“低熵”词元只是在已确定的路径上进行填充 。基于此,他们提出了一种创新的训练方法:在强化学习中,只针对这20%的“岔路口词元”(forking tokens)进行策略更新。实验结果惊人地发现,这种方法不仅没有降低性能,反而在Qwen3-32B等大模型上取得了远超于使用全部词元进行训练的效果(例如在AIME'25测试上提升了11.04分)。相反,如果只训练那80%的低熵词元,模型性能会急剧下降。这揭示了强化学习之所以能有效提升推理能力,其根本原因在于优化了那些决定推理方向的高熵关键少数词元。

目前在带可验证奖励的强化学习(RLVR)训练时存在一个认知盲区。现有方法通常对生成的所有词元一视同仁地进行训练,没有区分它们在推理过程中扮演的不同功能角色,这可能限制了模型性能的进一步提升。为此,本研究提出了一个全新的视角:通过分析“词元熵”的模式来理解RLVR的内部机制。作者预告了他们的核心发现:推理过程中的词元可以被分为两类,一类是少数高熵的“岔路口词元”(forking tokens),它们负责引导推理走向不同路径;另一类是多数低熵的“跟随者词元”,负责沿着路径填充内容。论文的主要贡献就是验证了只对前者进行强化学习训练,可以在更大型的模型上取得远超传统方法的性能,这揭示了高熵少数词元在推理能力提升中的决定性作用。
预备知识
“词元熵”的计算,其公式为 $H_{t}:=-\sum_{j=1}^{V}p_{t,j}\log p_{t,j}$ 。需要明确的是,这里的熵衡量的是在生成某个词元时,模型对于词汇表中所有可能词元的概率分布的不确定性,而不是针对某个被采样出的特定词元。简单来说,熵越高,代表模型在这一步的选择越不确定,面临的可能路径越多。其次,文章介绍了作为实验基础的RLVR算法,特别是DAPO算法。DAPO是一种先进的、无需价值网络的强化学习算法,它通过比较一批生成回复的最终奖励好坏来估算优势,并结合了“clip-higher”等机制来稳定和优化训练过程,是目前效果最好的RLVR算法之一。
分析思维链推理中的词元熵
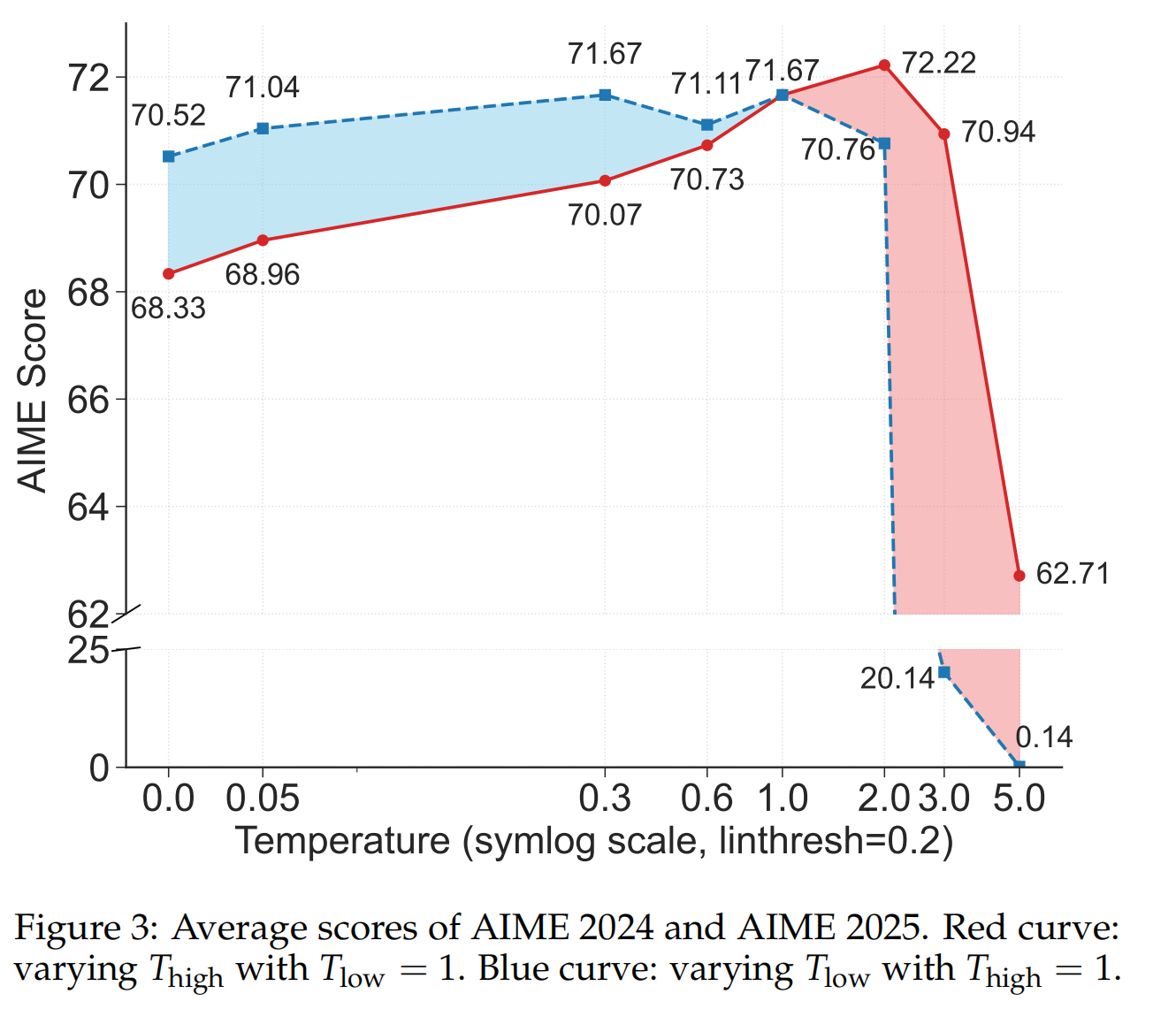
研究者让Qwen3-8B模型解答数学问题,并收集了超过一百万个词元的熵数据进行分析。第一个模式是,词元熵的分布极不均匀:超过一半的词元熵值极低(接近于0),而只有20%的词元拥有较高的熵值。第二个模式是,高熵词元和低熵词元在功能上泾渭分明。通过分析具体词语发现,高熵词元通常是那些引导逻辑、引入假设或做出转折的词,如“然而(however)”、“假设(suppose)”、“因此(thus)”等,它们如同推理路径上的“岔路口” 。而低熵词元则多为单词后缀或固定的数学符号,负责完成句子结构,具有很高的确定性。为了验证“岔路口词元”的重要性,研究者还做了一个巧妙的实验:在生成回答时,只提高岔路口词元的解码温度(即增加随机性),结果模型性能显著提升;反之则性能下降,这定量地证实了在这些关键决策点上保持较高的不确定性是有益的。
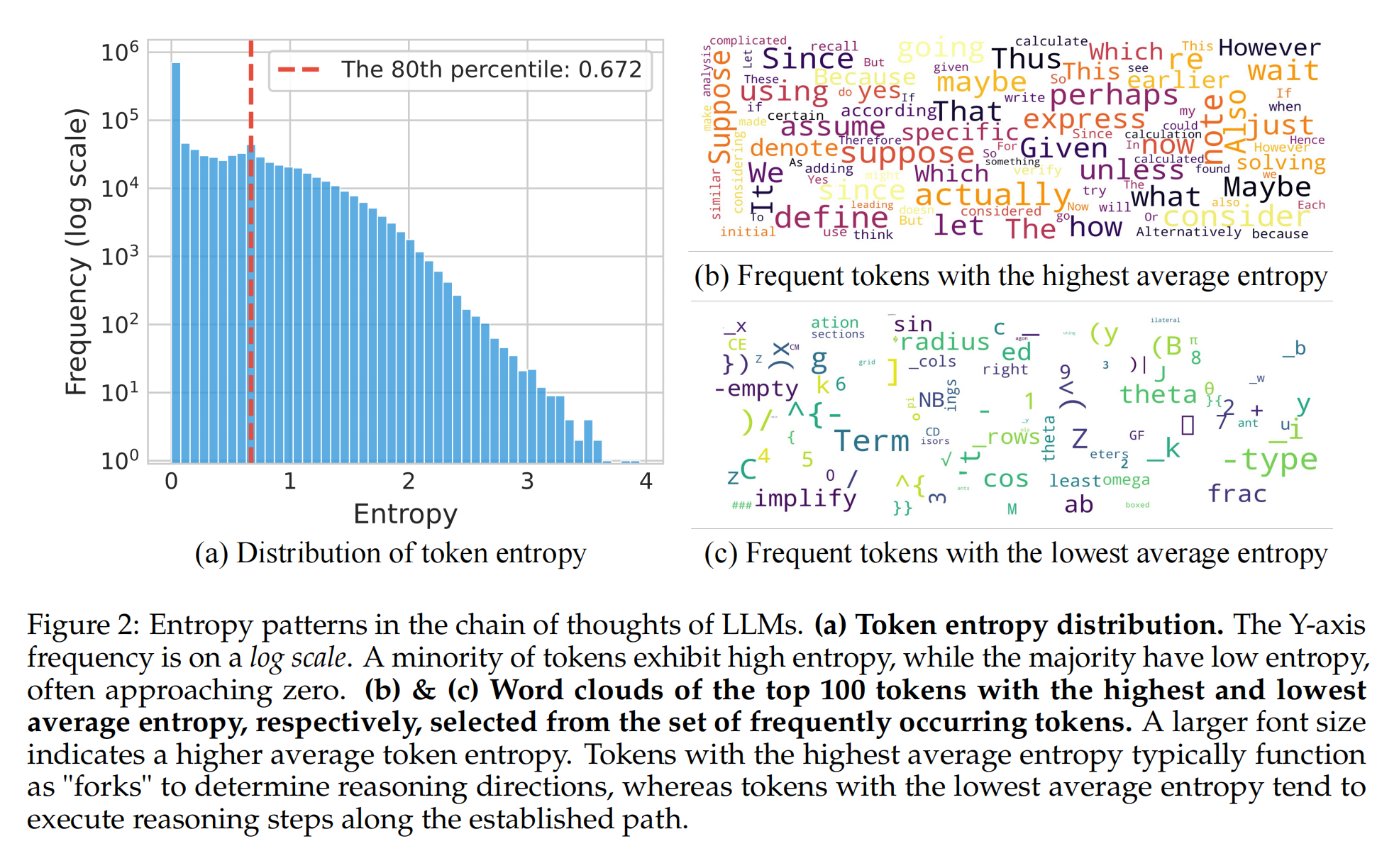
RLVR保留并强化基础模型的熵模式
在RLVR训练过程中,有两个核心发现。
第一,RLVR在很大程度上保留了原始基础模型的熵模式 。通过对比训练过程中不同阶段模型的高熵词元位置,发现即便是训练完成后的模型,其高熵词元的位置与初始模型相比仍有超过86%的重叠度。这说明,哪些位置应该是不确定的“岔路口”,在模型预训练后就基本定型了,强化学习并未大规模改变它。
第二,RLVR的训练效果主要体现在对高熵词元的熵值进行调整 。数据显示,初始熵越高的词元,在RLVR训练后其熵值的变化也越大;而那些低熵词元的熵值在整个训练过程中则基本保持稳定,波动很小。这表明,强化学习的优化过程,是聚焦于那些关键的“岔路口”,去调整在这些点上的选择倾向,而不是去改变整个推理路径的结构。

高熵少数词元驱动有效的RLVR
研究者修改了DAPO强化学习算法的目标函数,加入了一个指示函数$\mathbb{I}[H_{t}^{i}\ge\tau_{\rho}^{B}]$ 。这个函数的作用相当于一个“开关”,它只允许每批数据中熵值排名前$\rho$(实验中主要设为20%)的词元参与策略梯度的计算和模型更新,而忽略掉其余80%的低熵词元 。
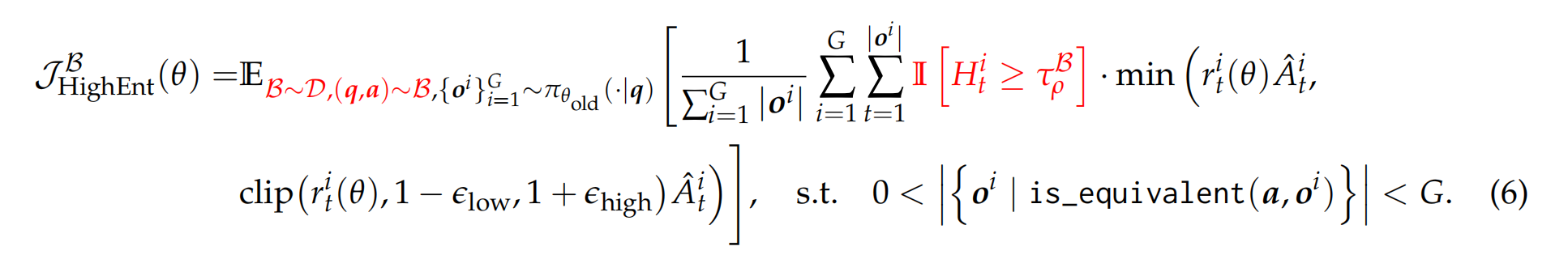
实验结果非常有力:在Qwen3-14B和Qwen3-32B这样的大模型上,这种“只训练20%关键少数”的方法,其性能显著超过了使用100%全部词元进行训练的传统方法 。反之,如果只用那80%的低熵词元来训练,模型性能会严重下降。作者认为,这背后的原因是高熵词元对于强化学习中的“探索”至关重要,而只保留约20%的最高熵词元,恰好在探索和训练稳定性之间取得了最佳平衡。并且,这种性能增益随着模型规模的增大而越发明显,显示出良好的扩展趋势。
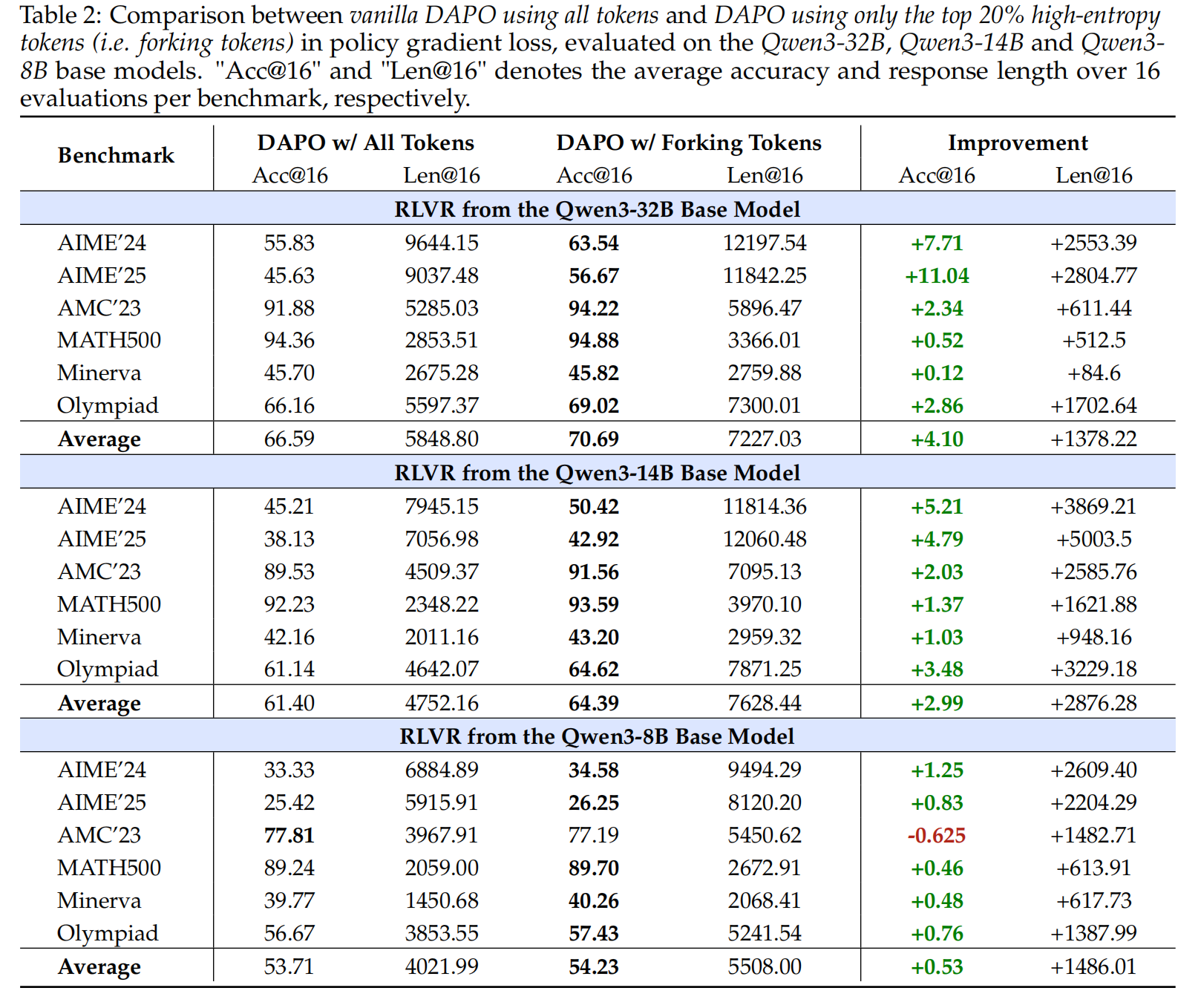
讨论
第一,它为“为什么强化学习(RL)能泛化而监督微调(SFT)易于记忆”这一问题提供了新解释。作者推测,RL之所以泛化能力强,可能是因为它在训练中保持甚至增加了“岔路口词元”的熵,从而保留了推理路径的灵活性;而SFT倾向于将模型输出推向确定性的答案,降低了这些词元的熵,导致推理路径变得僵化。
第二,它解释了为何LLM的推理过程与传统RL任务不同。传统RL任务的动作熵可以很均匀,而LLM因为经过海量文本预训练,大部分语言都遵循固定模式(低熵),只有少数地方需要做真正的决策(高熵),这种独特的熵分布是由其语言模型的本质决定的。
第三,它指出了在LLM中直接使用“熵奖励”来鼓励探索可能并非最佳选择。因为这会错误地增加那些本应确定的低熵词元的不确定性,破坏语言的流畅性。相比之下,DAPO算法中的“clip-higher”机制则更优越,因为它能间接地、更精准地作用于高熵词元,在需要探索的地方进行探索。
刚好近期看到了一个类似的大模型比赛,阿里天池上的AFAC大赛:赛题三《金融领域中的长思维链压缩》,关注“长思维链”处理问题,任务目标——“构建高效的推理链压缩方法”、“保留关键推理逻辑,剔除冗余内容”。有三个大模型方向的赛题,感兴趣的同学可以一试,7.19前截止。奖励也不错,百万奖金+校招直通!