《Reinforcement Pre-Training》
传统的大模型预训练虽然可靠,但可能只是在学习表面的文本关联性,而用于对齐的强化学习(RL)又面临数据昂贵、难以规模化的问题。这篇论文最具启发性的做法是,从根本上“重塑”了预训练任务。它不再将“预测下一个词”看作一个简单的分类任务,而是将其提升为一个需要“推理”的过程。模型被激励去思考为什么下一个词是这个,而不是那个,并且只要预测正确,就能从训练数据本身获得一个可验证的奖励。这种方法巧妙地将海量的无标注文本数据,转变成了强化学习的训练场,既解决了RL的规模化问题,又可能让模型学到更深层次的推理能力,而不仅仅是记忆。论文用“樱桃蛋糕”的比喻(将RL融入预训练蛋糕本身)来对比传统的“蛋糕上的樱桃”(RL作为后续微调),生动地说明了这一范式的根本性转变。
现代语言模型的基础——标准的“下一个词预测”(NTP)任务,其目标函数是最大化文本序列的对数似然概率,即

“带可验证奖励的强化学习”(RLVR),其目标函数是最大化从环境中获得的期望奖励 。

通过并列这两种方法,读者可以清晰地看到:一个依赖于庞大的数据进行自监督学习,另一个则依赖于带有明确答案的标注数据和奖励信号进行学习。这个对比凸显了一个核心矛盾:规模化与强反馈之间的差距,而RPT正是在试图弥合这个差距。
强化学习预训练

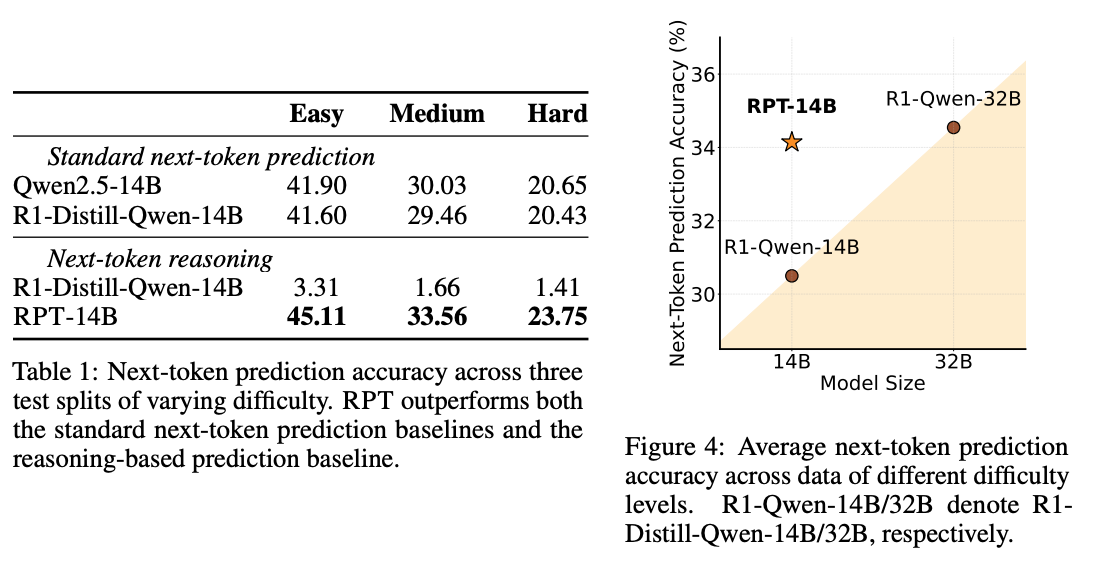
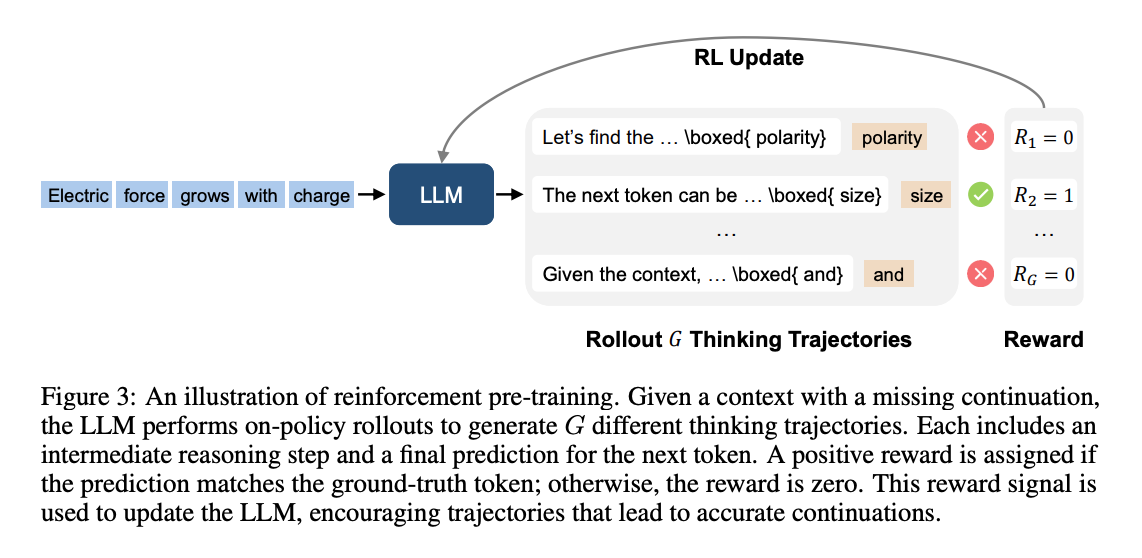
首先,在任务定义上,创造性地提出了“下一词元推理”(Next-Token Reasoning)任务。模型在预测下一个词 $y_t$ 之前,必须先生成一段“思考链”(chain-of-thought)$c_t$ 。这种做法,如图2所示,强迫模型在输出最终答案前进行一系列的头脑风暴、自我批判和修正,从而将庞大的预训练语料库转变为一个巨大的推理问题集。其次,在训练机制上,它采用了在线强化学习(on-policy RL)。模型会针对一个上下文,生成多条(实验中为8条)不同的“思考轨迹” ,然后根据最终预测的词是否与真实答案一致来给予奖励。这里的奖励函数设计也很巧妙,采用“前缀匹配奖励”,即预测的字节序列只要是真实答案的有效前缀就给予奖励,这优雅地处理了预测可能跨越多个词元的情况 。最后,在预训练设置中,一个非常实用的关键做法是“数据过滤” 。研究者用一个较小的代理模型计算每个词元的预测熵,并过滤掉那些熵很低(即很容易预测)的词元。这使得计算成本高昂的强化学习过程可以专注于那些真正需要复杂推理才能解决的“硬骨头”,极大地提升了训练效率。
实验
本章通过一系列详实的实验,验证了RPT范式的有效性,其中几个发现尤其具有启发意义。
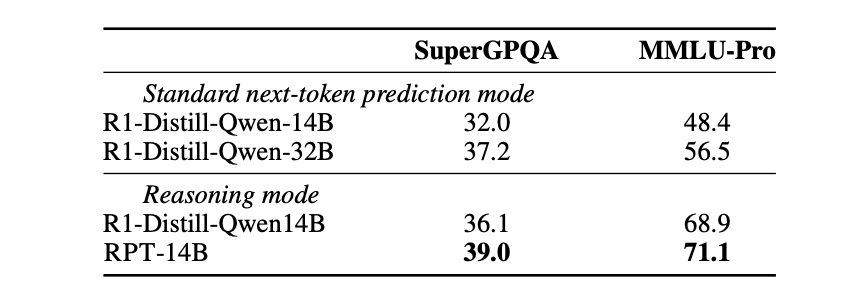
第一,在语言建模能力上,经过RPT训练的14B(140亿参数)模型,其预测下一个词的准确率,不仅远超同等规模的基线模型,甚至能媲美一个大得多的32B模型。这强烈暗示了RPT可能是通往更强模型能力的一条“捷径”,用更少的参数实现了更强的性能。
第二,RPT展现了优秀的“规模化特性”(Scaling Properties)。实验数据显示,其性能随着RL计算量的增加,呈现出非常平滑且可预测的幂律增长(公式为 $P(C)=\frac{A}{C^{\alpha}}+P^{*}$)。这是一个至关重要的结论,因为它表明RPT是一个可靠的、可持续的提升模型能力的方法,只要投入更多计算,就能获得更好的模型。
第三,RPT预训练过的模型是更好的“强化学习起点” 。在后续针对下游任务的RL微调中,RPT模型能达到更高的性能上限,而如果对基线模型继续做传统的预训练,其推理能力反而会下降 。
最后,通过对模型“思考过程”的分析,发现RPT诱导出的推理模式与常规解决问题的模式不同,它更多地使用“假设”和“演绎”等探索性思维。案例分析也表明,模型并非在简单地套用模板,而是在进行真正的审议,包括分析上下文、生成多种可能性并进行权衡,这证实了RPT确实在培养更深层次的理解能力。