
《Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning》
本文中,作者从信息论的视角研究了大型推理模型的推理轨迹。通过追踪大型推理模型在推理过程中,其中间表征与正确答案之间互信息(MI)的演变,作者观察到一个有趣的“互信息峰值”现象:在特定的生成步骤中,互信息在模型的推理过程中会出现突然且显著的增加。作者从理论上分析了这种现象,并证明了随着互信息的增加,模型的预测错误概率会降低。此外,这些互信息峰值通常对应着表达反思或转折的词元,例如“Hmm”、“Wait”和“Therefore”,作者将其称为“思考词元”。作者接着证明了,这些思考词元对大型推理模型的推理性能至关重要,而其他词元的影响则微乎其微。基于这些分析,作者通过巧妙地利用这些思考词元,提出了两种简单而有效的方法来提升大型推理模型的推理性能。总的来说,作者的工作为大型推理模型的推理机制提供了新颖的见解,并为其推理能力的提升提供了实用的方法。
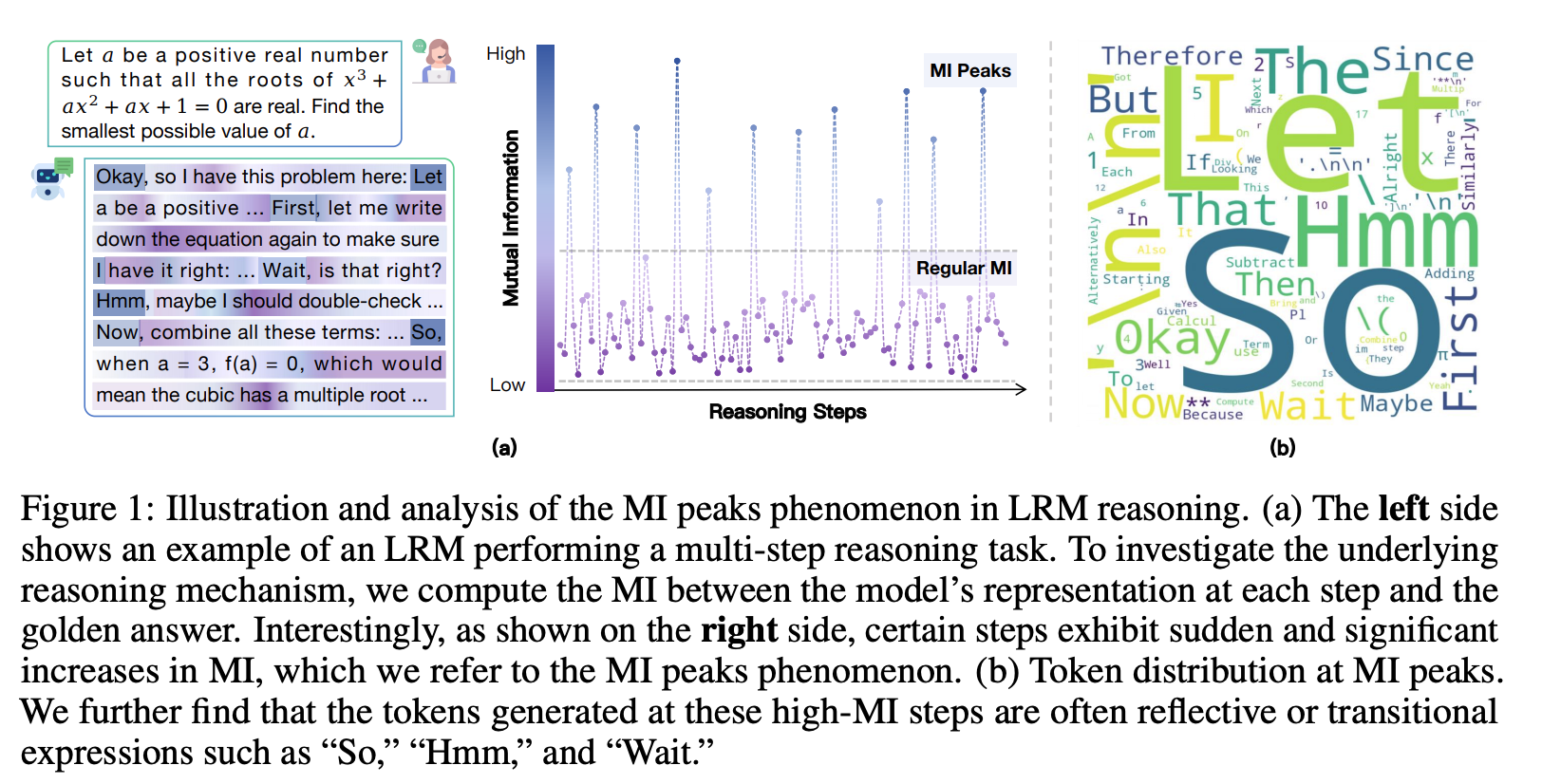
大型推理模型推理轨迹中互信息峰值的涌现
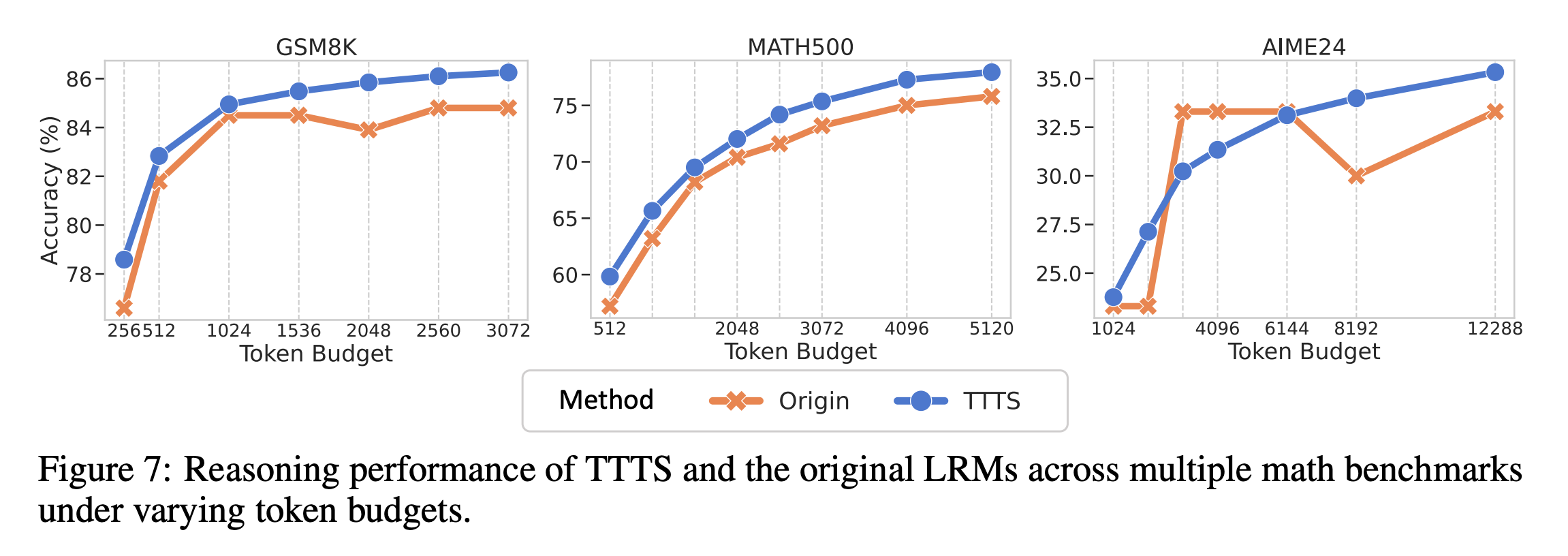
首先,在模型进行一步步推理生成答案的过程中,研究者会提取每一步生成的词元所对应的内部隐藏状态(hidden representation),记为$h_t$。同时,他们也将最终的正确答案(golden answer)输入模型,得到一个代表正确答案的隐藏状态$h_y$。接着,本文最核心的操作是利用一种名为“希尔伯特-施密特独立性准则”(HSIC)的工具来估计每一步的$h_t$与最终答案$h_y$之间的互信息(MI)值,因为直接计算高维空间中的MI非常困难,而HSIC是一个有效的替代估计方法。通过对多个大型推理模型(如DeepSeek-R1系列)进行实验,他们一致地观察到,MI值在大部分推理步骤中都比较平稳和低,但在某些稀疏且不规律的节点上会突然出现显著的峰值。为了解释这一现象为何重要,论文从理论上给出了两个不等式(定理1和定理2),证明了模型在推理过程中积累的互信息总量($\sum_{j=1}^{T}I(y;h_{j}|h_{ “互信息峰值”在语义层面到底代表了什么,以及这些节点为何如此重要?其关键做法是“解码-验证”两步法。 第一步是解码:研究者将那些处于互信息峰值(MI peaks)的内部隐藏状态$h_t$拿出来,然后将它们送入模型的输出层(通常是一个线性映射$W_{out}$加上Softmax激活函数),通过贪心策略选出概率最高的词元,即 这个过程相当于“反向翻译”,看看模型在信息量最高的“思考节点”上,最想说的是哪个词。极具启发性的发现是,解码出的词元高度集中于一些引导思考、反思、转折或总结的词,如“所以(So)”、“嗯(Hmm)”、“等等(Wait)”,论文因此将它们称为“思考词元”。 第二步是验证:为了证明这些思考词元不仅仅是相关,而是对推理能力至关重要,作者设计了一个巧妙的干预实验。他们在模型进行推理时,人为地“压制”这些思考词元的生成(比如将其生成概率设为0)。结果显示,一旦压制了这些思考词元,模型在多个数学推理基准测试(如GSM8K)上的表现就出现显著下降;而作为对照,如果随机压制同等数量的其它普通词元,模型的性能则几乎不受影响。这一强有力的对比实验,清晰地证明了这些思考词元确实是模型推理能力的关键支点。 将前面的理论发现转化为两种非常实用的、无需重新训练的推理增强技术。 第一种技术叫做**“表征回收”(Representation Recycling, RR)**。它的核心思想是,既然MI峰值处的隐藏状态信息量大,那就让模型对其进行“精加工”。具体做法是,在模型推理时,一旦检测到它生成了一个“思考词元”(作为MI峰值的代理),就改变其正常的计算流程。通常,模型某一层的输出$h_{l}$会直接传递给下一层,但在RR中,这个高信息量的$\boldsymbol{h}_{\ell *}$会被“回收”,再送入当前层(${\ell *}$)的Transformer模块计算一次,即$h_{_{\ell *}}^{\prime}=TF_{_{\ell *}}(h_{\ell *})$,然后再将这个“精加工”后的结果传递给下一层。这相当于让模型在关键节点上“多想一遍”,从而更充分地利用这些宝贵信息。 第二种技术叫做**“基于思考词元的测试时扩展”**。这种方法利用了思考词元的语义功能。具体操作非常简单:当模型完成一轮初步的推理后,人为地在它输出的末尾添加一个“思考词元”(如“所以”),然后让模型从这个词元开始继续生成更多的推理步骤。这相当于在模型“卡壳”或“以为自己想完了”的时候,给它一个“然后呢?”的提示,激励它进行更深层次的思考。实验证明,这两种方法都能有效提升模型在数学推理任务上的准确率,尤其是在给予更多计算时间的情况下,TTTS能持续带来性能提升。 本章总结了整篇论文的贡献。研究团队系统性地运用信息论的视角,成功揭示了大型推理模型(LRMs)内部推理机制的一个重要侧面。他们首先发现了“互信息峰值”(MI peaks)这一有趣的现象,即在推理过程中的特定时刻,模型的内部表征会与正确答案高度相关。接着,他们发现这些峰值点主要对应着表达自我反思、逻辑转换或修正的“思考词元”(如“Hmm”、“Wait”、“Therefore”)。从理论上,论文也证明了更高的累积互信息量有助于降低模型的预测错误率,为MI峰值现象的重要性提供了理论依据。基于这些分析,论文最终提出了两种简单而有效的无训练增强方法——“表征回收”(RR)和“基于思考词元的测试时扩展”(TTTS),并验证了它们能切实提升模型的推理表现。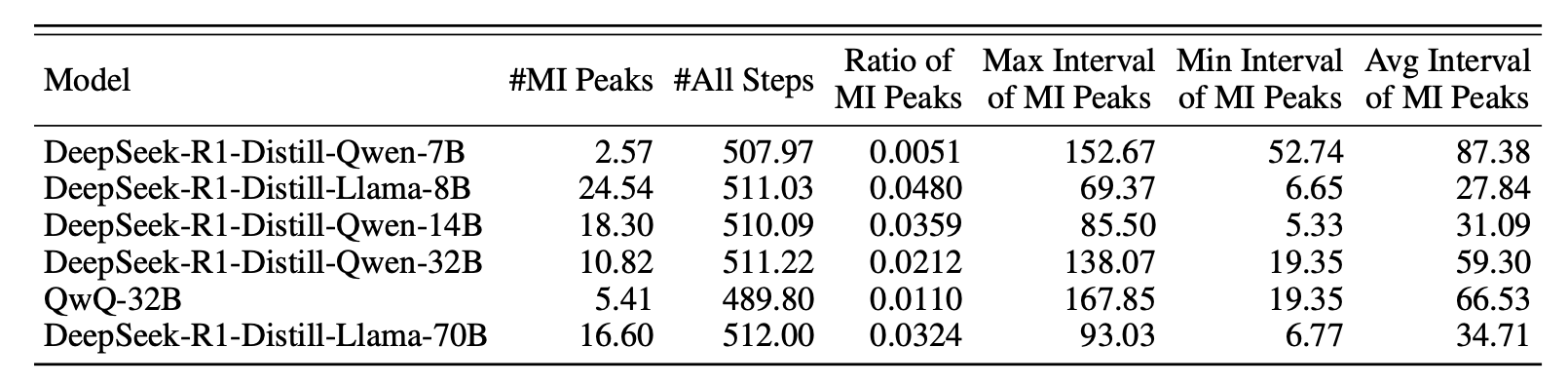
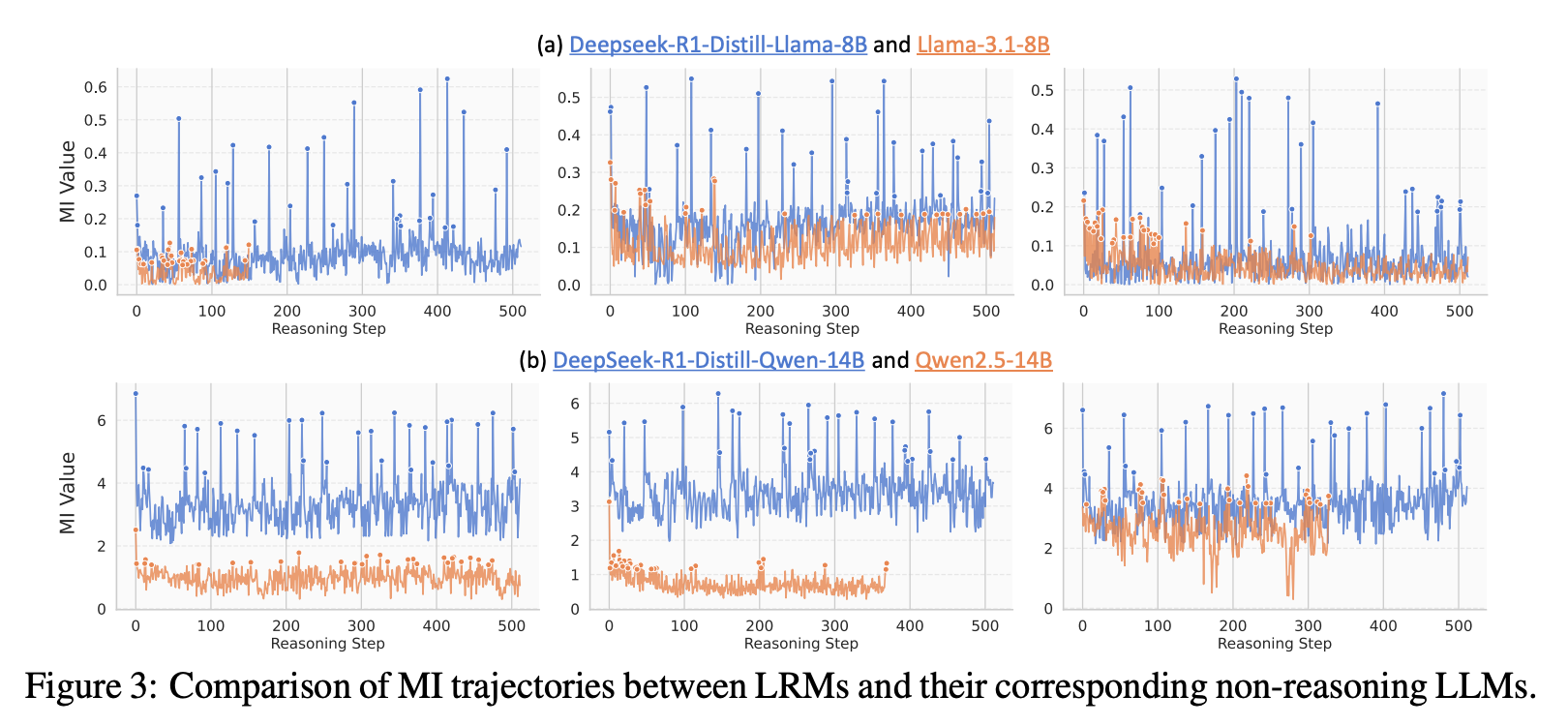
思考词元即为大型模型推理中的信息峰值

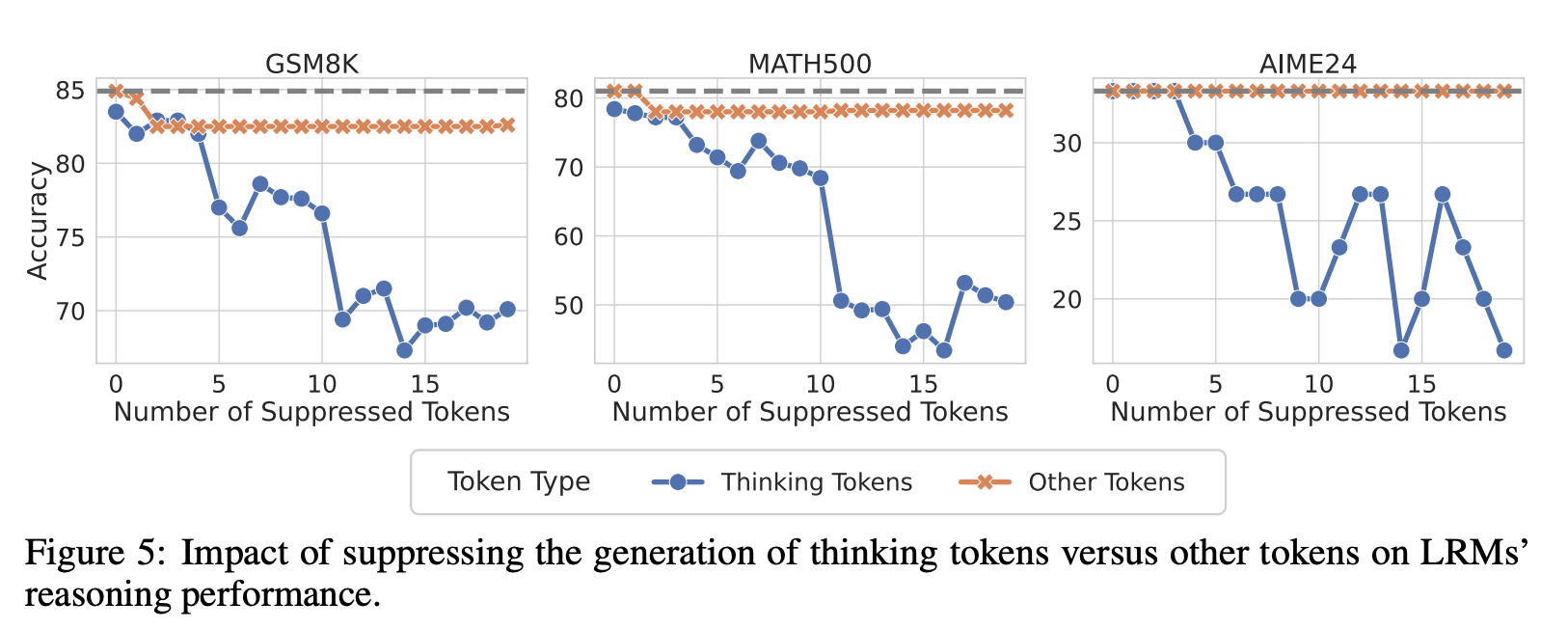
应用:利用互信息峰值提升大型推理模型的推理能力

结论