
摘要
研究者发现,无论是经过专门推理训练还是通过思维链提示的推理增强型大型语言模型(RLLM),在执行许多复杂推理任务时已达到顶尖水平。然而,一个出乎意料且此前被忽视的现象是,明确的思维链推理会显著削弱模型遵循指令的准确性 。通过在两个基准(IFEval,包含简单的、规则可验证的约束;ComplexBench,包含复杂的、组合性约束)上评估15个模型,研究一致观察到,当应用思维链提示时,性能会出现下降 。大规模案例研究和基于注意力的分析揭示了推理在何处有益(例如,格式化或词汇精度)或有害(例如,忽略简单约束或引入不必要内容)的常见模式 。
研究者提出了一个名为“约束注意力”的指标,用以量化模型在生成过程中对指令的关注程度,并表明思维链推理常常将注意力从与指令相关的标记上移开 。
为减轻这些影响,研究引入并评估了四种策略:情境学习、自我反思、自我选择性推理和分类器选择性推理 。结果表明,选择性推理策略,特别是分类器选择性推理,可以大幅恢复损失的性能 。据研究者所知,这是首次系统性揭示推理引发的指令遵循失败并提供实用缓解策略的研究 。
1. 引言
研究者提出了一个核心问题:明确的推理是否真的能帮助模型更准确地遵循指令? 本文通过实证研究得出了一个令人惊讶的结论:通过思维链进行推理会降低模型遵循指令的能力 。
为了系统评估大型语言模型的指令遵循情况,引入了IFEval和ComplexBench等基准测试 。

3. 实验
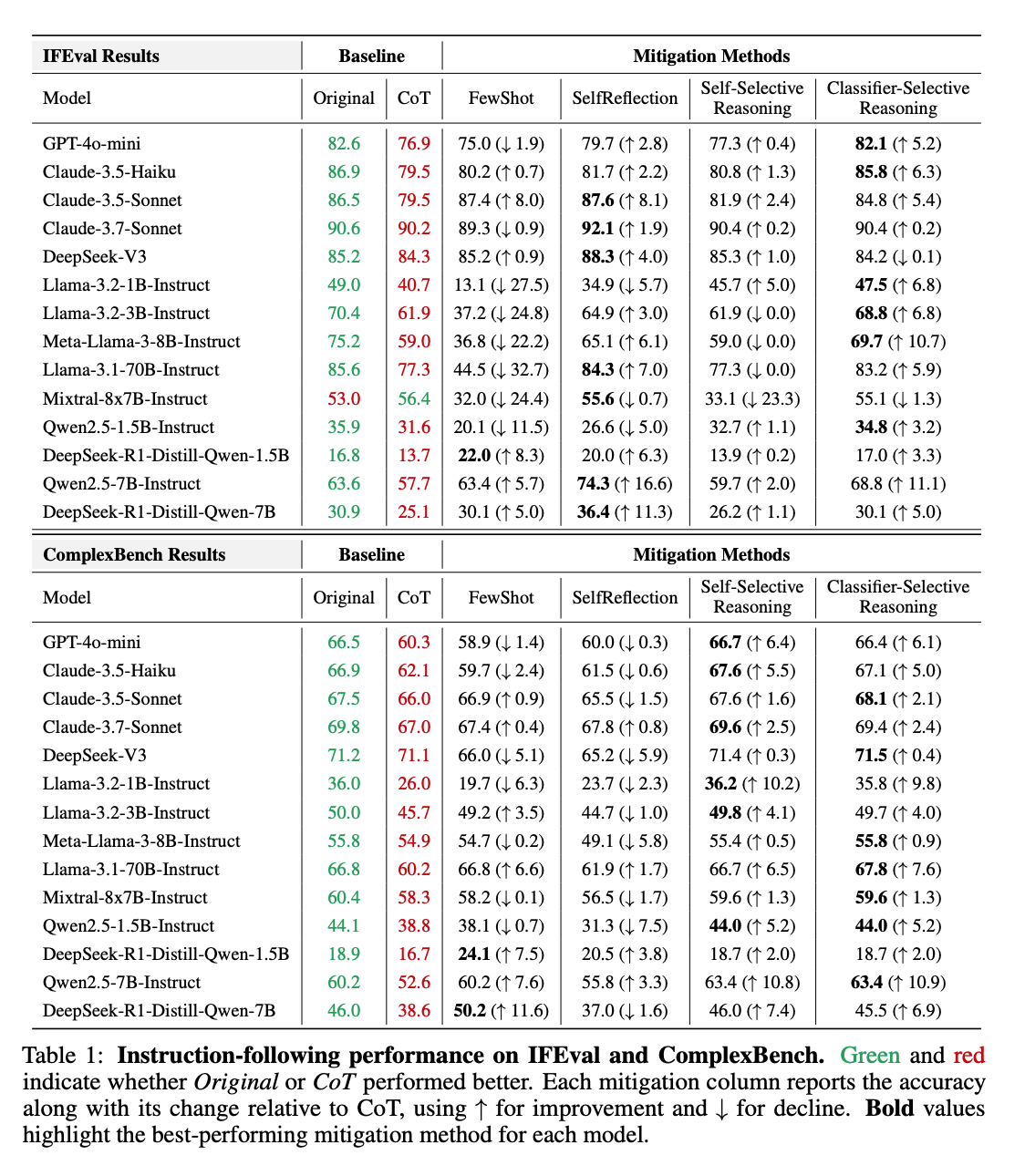
实验部分详细介绍了评估模型指令遵循能力所使用的数据集、评估指标、参与评估的模型以及思维链提示的应用方式。研究使用了IFEval和ComplexBench两个基准数据集 。IFEval包含541个提示,每个提示都与一到三个可验证的约束相关联,这些约束来自25种类型(例如,字数、格式、关键词使用) 。ComplexBench是一个手动策划的数据集,旨在评估模型在通过“与”、“链”、“选择”和“嵌套”等操作形成的复杂组合指令上的表现 。评估指标主要关注每个指令中满足的约束的比例 。研究评估了包括闭源模型(如GPT-40-mini, Claude3.7-Sonnet)和专注于推理的模型(如DeepSeek-R1, Qwen-R1-distilled变体)在内的多种模型 。实验结果一致显示,当应用思维链提示时,几乎所有模型在IFEval和ComplexBench上的性能都出现了下降 。例如,Llama3-8B-Instruct的准确率从75.2%下降到59.0%,降幅超过16个百分点 。

4. 分析 (Analysis)
为了理解推理何时以及为何会降低指令遵循能力,研究者进行了两项分析:一项手动案例研究,检查思维链在何时帮助或损害约束满足;以及一项基于注意力的分析,调查推理如何在生成过程中将模型注意力从约束上移开 。
在案例研究中,研究者发现推理在满足格式或结构要求以及强制执行覆盖默认倾向的词汇约束方面有所帮助 。然而,当多个约束存在时,推理通常会过分关注高级内容规划而忽略简单的机械约束,或者引入多余的或善意的内容,从而无意中违反约束 。在基于注意力的分析中,研究者提出了“约束注意力”指标,用于量化模型对指令中约束标记的关注程度 。分析表明,明确的推理通常会减少对提示中与约束相关部分的注意力,这种意识的减弱增加了违反指令的风险 。
5. 减轻推理引发的指令遵循失败
针对推理导致指令遵循性能下降的问题,研究者提出并评估了四种缓解策略:少样本情境学习、自我反思、自我选择性推理和分类器选择性推理 。
少样本情境学习:通过在每个指令前添加精心挑选的少样本示例来进行,这些示例源自案例研究中发现的代表性失败案例,并经过手动修改以完全满足所有约束。然而,由于令牌长度限制和每个示例的巨大体量,该方法改进效果有限。
自我反思:模型首先生成带有思考过程的初始响应,然后在第二次推理中反思其自身的推理和答案。如果模型认为初始响应满意,则保留它作为最终输出;否则,它会修改响应并输出更新后的版本。自我反思在IFEval上产生了显著的改进,但在较弱的模型和包含更具挑战性指令的ComplexBench上效果较差,并且计算成本较高。
自我选择性推理:允许模型动态决定是否执行明确的推理。模型根据指令自行评估是否需要思维链推理。此方法在IFEval上取得了适度的收益,在ComplexBench上表现更强。分析发现,模型倾向于高召回率(正确识别大多数推理有益的情况),但精确率较低,即使在不必要时也经常应用推理。
分类器选择性推理:使用外部二进制分类器来确定是否应应用思维链推理。研究者为每个目标模型训练一个单独的分类器,以预测使用思维链是否会导致指令遵循性能的提高。该方法被证明非常有效,几乎在所有模型的两个基准测试中都提高了性能。然而,其主要缺点是需要针对每个模型进行特定的训练。
研究者基于这些发现提出了一个决策流程:首先,通过简单启发式或训练好的分类器估计指令的复杂性 。对于较简单的任务,推荐自我反思或分类器选择性推理;对于更复杂或组合性的任务,自我选择性推理或分类器选择性推理更有效 。总体而言,分类器选择性推理在两个基准测试中始终提供最佳的整体性能,尽管需要针对模型进行特定训练 。
6. 结论
研究确定并系统地探讨了一个出乎意料的现象:通过思维链提示进行的明确推理会对大型语言模型的指令遵循能力产生负面影响 。通过在IFEval和ComplexBench两个综合基准上的广泛评估,研究证明了当模型采用明确推理时,性能会持续下降 。详细的分析,包括手动案例研究和基于注意力的检查,揭示了推理如何分散模型对与约束相关的标记的注意力,从而导致指令被忽略或违反 。提出的四种缓解策略,特别是分类器选择性推理,可以大幅恢复损失的性能 。研究者希望这些发现能激发对推理权衡的进一步研究,并有助于构建更具选择性和有效性的推理模型 。