摘要
该论文挑战了自回归模型 (ARM) 作为大型语言模型 (LLM) 基石的普遍看法,引入了一种从头开始训练的扩散模型 LLaDA 。LLaDA 通过前向数据掩码过程和由标准 Transformer 参数化的反向过程(用于预测被掩码的词元)来建模数据分布 。通过优化似然边界,它为概率推断提供了一种有原则的生成方法 。论文表明 LLaDA 具有强大的可扩展性,在上下文学习方面 LLaDA 8B 能与 LLaMA3 8B 等强LLM相媲美,并在监督微调 (SFT) 后展现出令人印象深刻的指令遵循能力,例如在多轮对话中 。此外,LLaDA 解决了“逆转诅咒”问题,在逆转诗歌补全任务中超越了 GPT-4o 。这些发现确立了扩散模型作为 ARM 的一种可行且有前景的替代方案 。
引言
引言首先指出大型语言模型 (LLM) 完全属于生成模型的范畴,其目标是通过优化模型分布 $p_θ(⋅)$ 来捕捉真实但未知的数据分布 $p_{data}(⋅)$,通常通过最大化对数似然或最小化KL散度实现

当前主流方法依赖自回归模型 (ARM),即下一词元预测范式

自回归范式是否是实现 LLM 智能的唯一路径?
他们认为,LLM 的基本特性(如可扩展性、指令遵循、上下文学习)源于通用的生成模型原理(公式1),而非自回归结构本身 。ARM 自身存在固有限制,如序列化生成计算成本高,以及在逆向推理任务中效果不佳 。受此启发,论文引入 LLaDA(Large Language Diffusion with mAsking),一种基于掩码扩散模型 (MDM) 的方法,通过离散随机掩码过程及其逆过程来构建模型,旨在探索超越 ARM 的生成模型路径 。LLaDA 的贡献主要体现在:证明了扩散模型的可扩展性,展示了其强大的上下文学习能力、指令遵循能力以及解决逆转推理问题的潜力 。
方法
本章详细介绍了 LLaDA 的概率公式、预训练、监督微调 (SFT) 和推理过程。其核心思想是通过一个前向的掩码过程和一个反向的去噪(预测掩码)过程来定义模型分布 $p_θ(x_0)$ 。
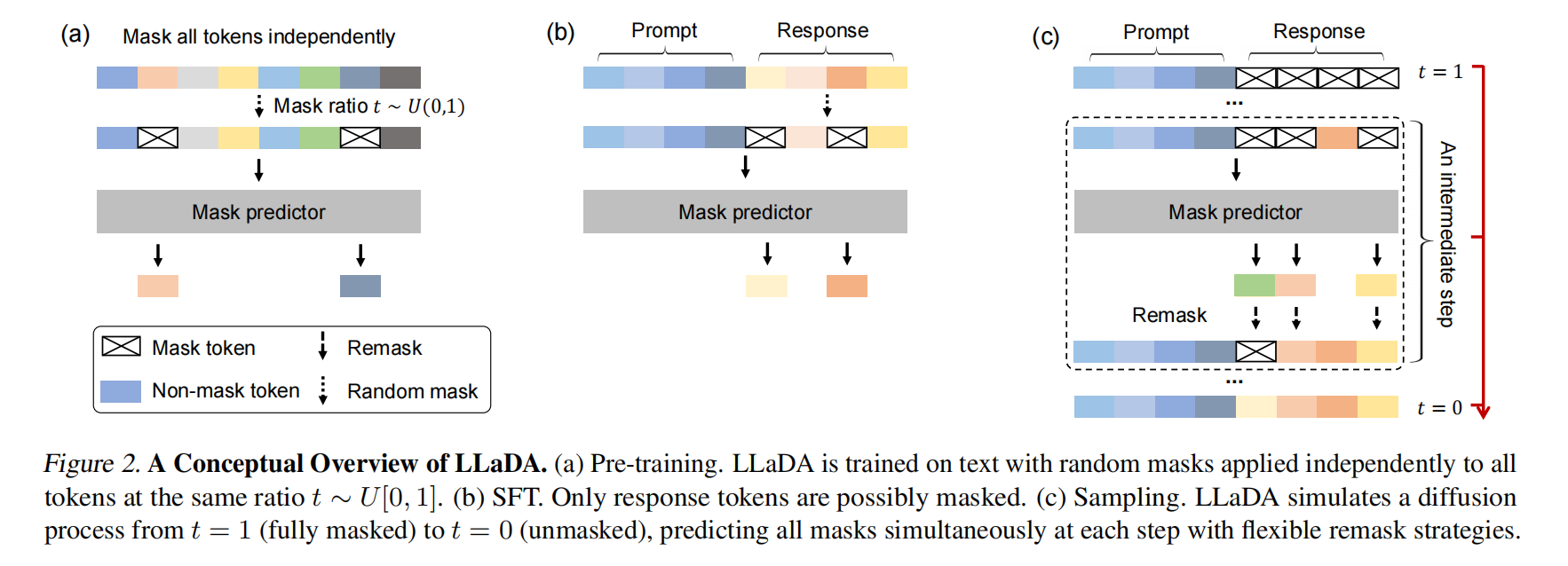
在概率公式部分,LLaDA 的核心是一个掩码预测器 $p_θ(⋅∣x_t)$,它接收部分被掩码的序列 $x_t$ 作为输入,并同时预测所有被掩码的词元 (M) 。训练目标是优化:

其中 $x_0$ 从训练数据中采样,$t$ 从 [0,1] 均匀采样,$x_t$ 根据 $t$ 和 $x_0$ 生成(每个词元以概率 $t$ 被掩码) 。该损失函数被证明是模型负对数似然的一个上界

这使其成为一个有原则的生成模型优化目标 。与使用固定掩码率的BERT不同,LLaDA的掩码率 t 在0到1之间随机变化,这对于其作为生成模型并进行上下文学习至关重要 。
预训练阶段,LLaDA 使用标准的 Transformer 架构作为掩码预测器,但不使用因果掩码,允许模型看到整个输入进行预测 。LLaDA 8B 模型在包含2.3万亿词元的多样化数据集上从头预训练,序列长度为4096,使用了约0.13百万H800 GPU小时的计算资源 。训练过程中,对每个训练序列 $x_0$,随机采样 $t∈[0,1]$,独立地以概率 $t$ 掩码每个词元得到 $x_t$,然后通过蒙特卡洛方法估计公式3进行梯度下降训练 。学习率调度采用Warmup-Stable-Decay策略,优化器为AdamW 。
监督微调阶段,LLaDA 通过在成对数据 $(p_0,r_0)$(提示和回复)上进行微调来增强其指令遵循能力 。SFT 的实现与预训练类似:保持提示 $p_0$ 不变,对回复 $r_0$ 中的词元进行独立掩码得到 $r_t$,然后将 $p_0$ 和 $r_t$ 输入预训练的掩码预测器计算损失

LLaDA 8B 在450万对数据上进行SFT,涵盖代码、数学、指令遵循等领域 。一个关键做法是在短对话后附加EOS词元进行填充,并在训练目标中包含这些EOS词元,使得模型能自动控制回复长度 。
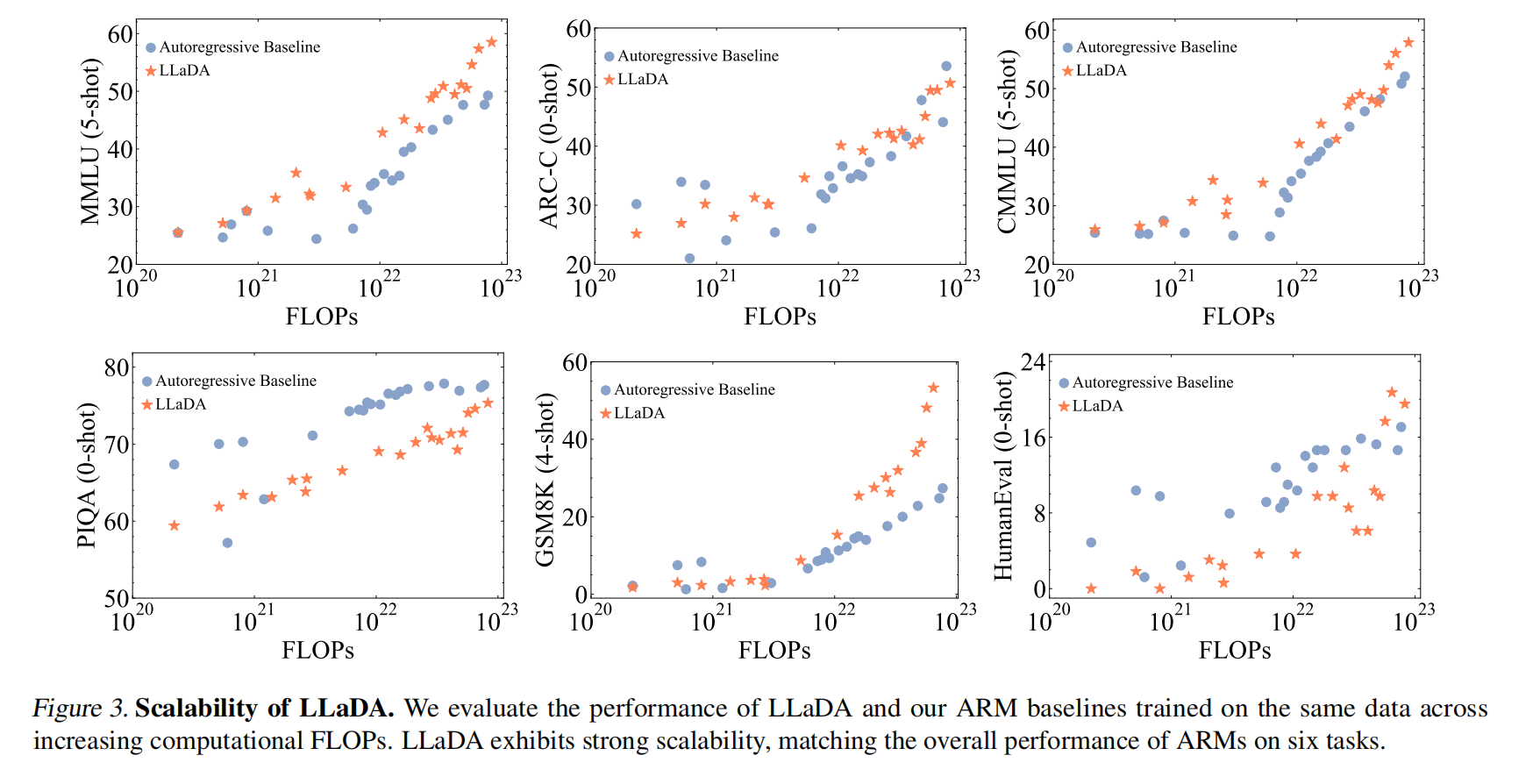
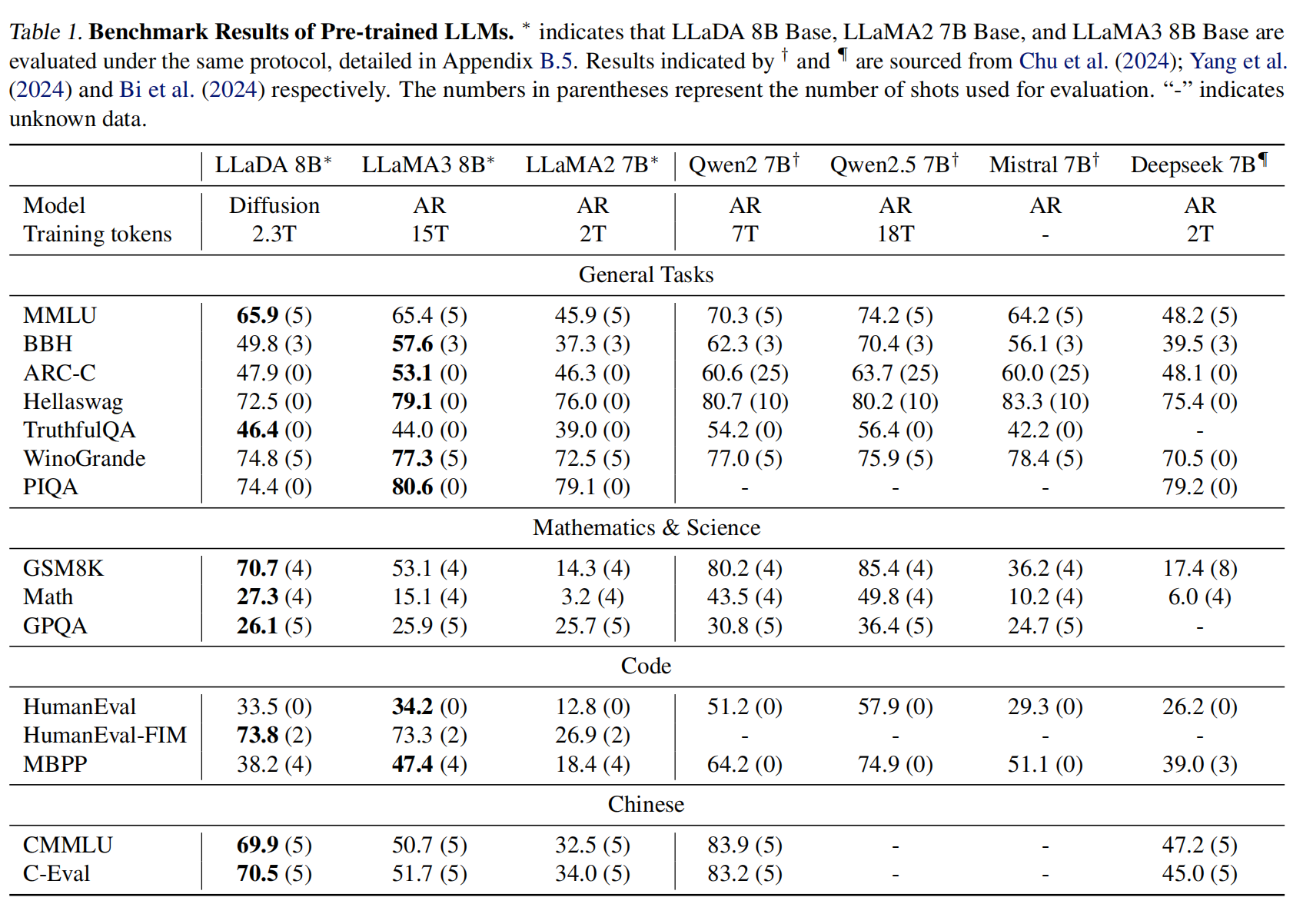
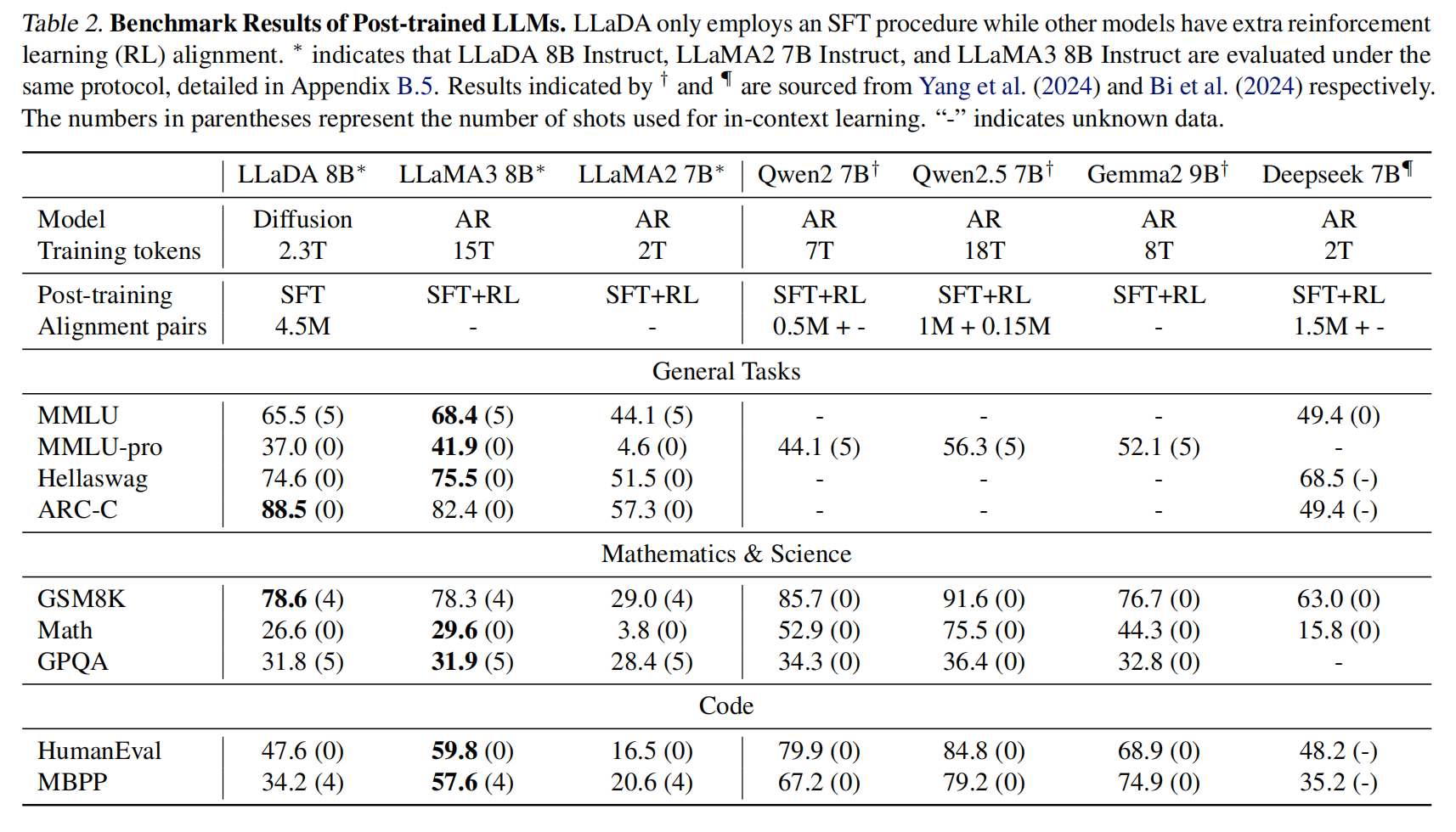
推理阶段,对于文本生成,LLaDA 从一个完全被掩码的回复开始,通过离散化的反向过程逐步去噪(即预测并填充被掩码的词元) 。在从时间 $t$ 到 $s (s 其中 $l$ 是从 ${1,...,L}$ 中均匀采样的掩码数量 。 实验 LLaDA的可扩展性 (Scalability of LLaDA on Language Tasks) 部分(图3),通过在MMLU、ARC-C、CMMLU、PIQA、GSM8K和HumanEval等六个任务上比较LLaDA和自建ARM基线(在相同数据上训练),展示了LLaDA随着计算FLOPs从 1020 增加到 1023 时的强大扩展能力,其整体趋势与ARM相当,甚至在MMLU和GSM8K等任务上表现出更强的扩展性 。 基准测试结果,预训练的LLaDA 8B(表1)在15个流行的通用、数学、代码和中文基准测试中,几乎全面超越了LLaMA2 7B,并与LLaMA3 8B表现相当,尤其在数学和中文任务上显示出优势 。经过SFT的LLaDA 8B Instruct(表2)在多数下游任务上性能得到提升,尽管未使用基于强化学习的对齐,其结果与LLaMA3 8B Instruct相比差距不大,显示了良好的指令遵循能力 。 逆向推理及分析 (Reversal Reasoning and Analyses) 部分(表3),在一个包含496对著名中国古诗句的特定任务中评估了模型的逆向推理能力(即给出后一句生成前一句) 。LLaDA 在前向和逆向任务上表现一致,有效解决了“逆转诅咒”问题,并在逆向任务中显著优于GPT-40和Qwen 2.5 。这归因于LLaDA对词元的统一处理方式,没有自回归模型的从左到右的归纳偏见 。 案例研究 (Case Studies) 部分(表4),展示了LLaDA 8B Instruct 生成连贯、流畅、扩展文本的能力,以及在多轮对话中保持上下文并产生恰当回复的能力 。