
Seed1.5-VL,这是一款视觉语言基础模型,旨在提升通用的多模态理解与推理能力。Seed1.5-VL 模型包含一个 5.32 亿参数的视觉编码器和一个拥有 200 亿活跃参数的混合专家 (MoE) 大语言模型 (LLM)。尽管架构相对紧凑,该模型在一系列公开的视觉语言模型 (VLM) 基准测试及内部评估中均表现出色,在 60 项公开基准测试中的 38 项上达到了业界领先 (state-of-the-art) 水平。此外,在图形用户界面 (GUI) 控制、游戏操作等以智能体为核心的任务上,Seed1.5-VL 的表现也超越了包括 OpenAI CUA 和 Claude 3.7 在内的顶尖多模态系统。该模型不仅擅长视觉和视频理解,还展现出强大的推理能力,在应对视觉谜题等多模态推理挑战时尤为有效。
模型架构 (Architecture)
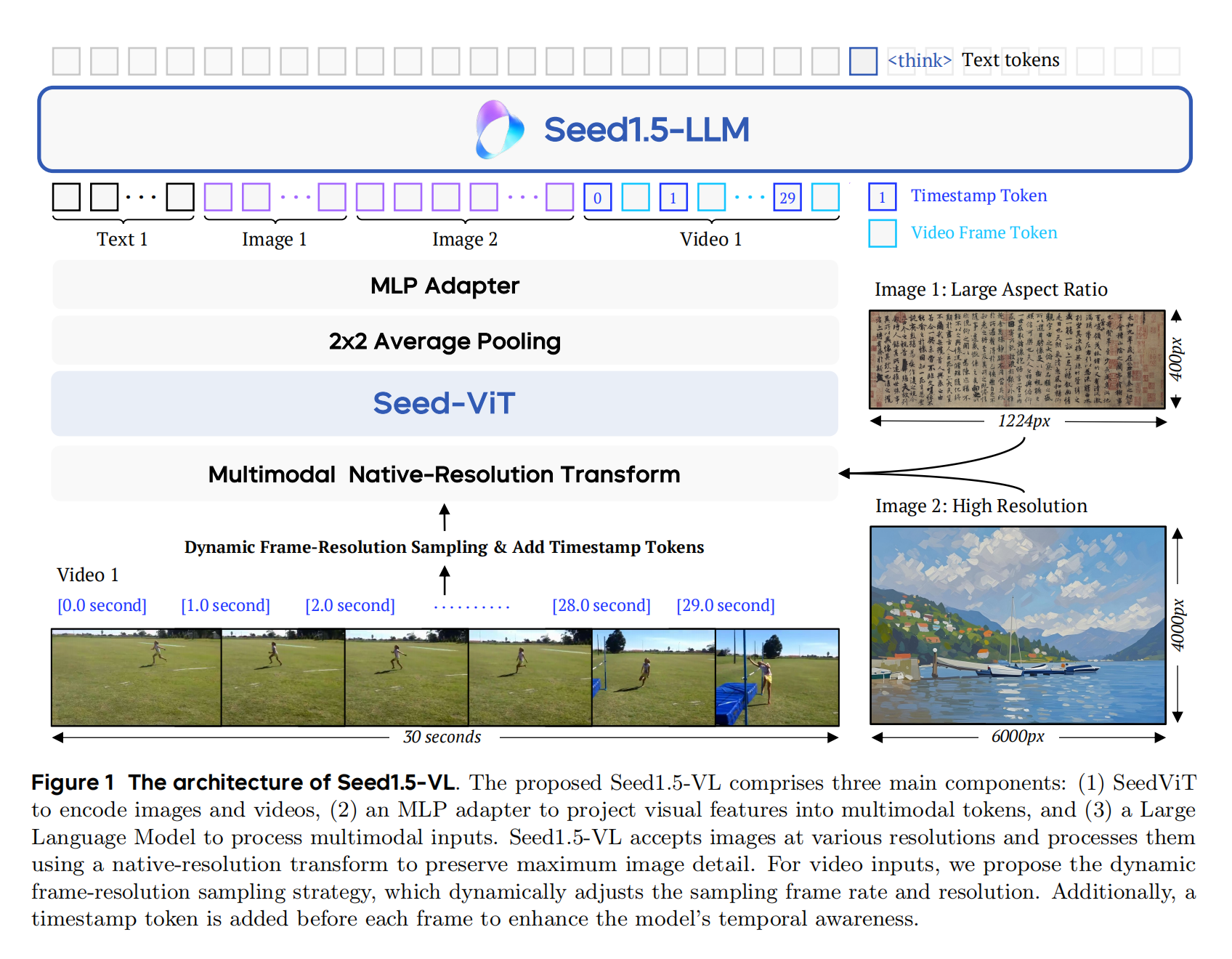
Seed1.5-VL的架构由视觉编码器、MLP适配器和大型语言模型 (LLM) 三个核心组件构成 。其视觉编码器 Seed-ViT 能够原生支持动态图像分辨率,并采用2D旋转位置编码 (2D ROPE) 以灵活适应任意尺寸的图像,这对于处理高分辨率图像、视频及OCR等需要精细细节的任务至关重要 。为了提高计算效率,架构对相邻的 $2\times2$ 特征块应用平均池化,随后通过一个两层MLP处理这些池化后的特征,再输入LLM 。报告强调,采用视觉编码器而非无编码器架构,能有效进行图像压缩,从而用更少的令牌表示高分辨率图像 。对于视频输入,模型采用了动态帧率-分辨率采样策略,并为每帧添加时间戳标记,以增强模型的时间感知能力和处理不同帧率视频的灵活性 。
视觉编码器 (Vision Encoder)
视觉编码器 Seed-ViT 是一个专为原生分辨率特征提取而设计的拥有5.32亿参数的Vision Transformer (ViT) 。它在预处理阶段将输入图像分辨率调整为 $28\times28$ 像素的最近倍数,然后分割成 $14\times14$ 像素的非重叠图像块 。这些图像块序列被投影到嵌入空间并输入Transformer模块,通过注意力掩码确保图像内的注意力机制 。
Seed-ViT 的预训练分为三个阶段:首先是采用2D ROPE的掩码图像建模 (MIM),通过重建教师模型 (EVA02-CLIP-E) 的CLIP特征来增强视觉几何和结构感知能力,即使教师模型使用可学习位置嵌入而学生模型使用2D ROPE,后者依然赋予学生模型强大的原生动态分辨率识别能力 ;其次是原生分辨率对比学习阶段,视觉编码器使用MIM训练的学生模型初始化,文本编码器使用EVA-02-CLIP-E的文本编码器初始化,通过联合优化SigLIP损失和SuperClass损失来对齐图像和文本嵌入 ;最后是全模态预训练阶段,采用MiCo框架构建包含视频帧、音频、视觉字幕和音频字幕的对齐元组,通过对齐这些嵌入使ViT学习统一的全模态表示,显著提升了ViT在图像和视频理解任务上的性能 。
视频编码 (Video Encoding)
Seed1.5-VL 通过引入动态帧率-分辨率采样 (Dynamic Frame-Resolution Sampling) 策略来有效编码视频信息,该策略在时间和空间维度上联合优化采样,以平衡语义丰富性和计算效率 。在时间维度上,模型根据内容复杂性和任务需求动态调整帧采样频率,默认为1 FPS,对于需要详细时间信息的任务可增至2 FPS或5 FPS 。为了明确每个帧在视频时间线上的位置,模型在每帧前添加时间戳令牌(如 [1.5 second]),显著增强了模型的时间感知能力和处理可变帧率的能力 。在空间维度上,模型在每个视频最多81920个令牌的预算内动态调整分配给每个选定帧的分辨率,提供六个预定义级别进行分层分配,允许在帧数和分辨率之间进行灵活权衡 。对于超长视频,模型会通过在整个视频中均匀采样来减少总帧数,以确保整个视频都能被表示 。
预训练 (Pre-training)
预训练阶段是Seed1.5-VL模型能力养成的关键环节,涵盖了精心策划的数据构建和高效的训练策略。
预训练数据 (Pre-training Data)
Seed1.5-VL的预训练语料库包含3万亿个多样化的高质量源令牌,这些数据根据目标能力进行分类和构建 。
通用图文对与知识数据:针对网络来源图文数据噪音大、类别不均衡的问题,采用了包括图文相似度评分、图像/文本标准过滤、去重和URL/域名过滤等一系列筛选技术 。为解决视觉概念长尾分布问题,通过先验VLM自动标注语义域和命名实体,识别并复制代表性不足的领域(频率低于平均领域频率50%)的文本描述,以实现更均衡的视觉概念分布,增强视觉知识学习 。
光学字符识别 (OCR):为增强模型对多语言文本、特殊符号及复杂结构文档的OCR能力,构建了超过10亿样本的内部OCR训练数据集,涵盖文档、场景文本、表格、图表和流程图 。通过收集各类文档并利用内部工具提取内容和布局信息,同时结合SynthDog和LaTeX等工具合成了超过2亿张文本密集型图像,并应用模糊、摩尔纹和图像失真等数据增强技术 。图表数据结合了开源数据集和LLM辅助生成的新合成数据(超过1亿图表示例) 。表格数据则通过从HTML、LaTeX和Markdown等格式中提取文本并渲染成超过5000万张表格图像 。此外,还构建了视觉问答 (VQA) 数据集,利用先前版本的VLM基于OCR输出、图表内容、表格文本和图像本身生成问答对,并通过内部LLM进行筛选,显著提升了模型理解图像中文本信息的能力 。
视觉定位与计数 (Visual Grounding & Counting):采用边界框和中心点两种主要定位表示。训练数据包括:1) 经过筛选和多样化任务构建的开源数据集(如Objects365, OpenImages, RefCOCO等)约4800万样本;2) 利用Grounding DINO等工具对大规模图文对进行自动标注生成的约2亿样本 。点位数据最初使用PixMo-Points的公开数据,后通过Molmo和CountGD(尤其适用于密集场景)在大量网络图像上标注物体中心点,生成约1.7亿指令 。计数数据则从上述边界框和点位数据中采样构建,包含约800万样本,分为基于框和基于点的计数 。所有坐标值均归一化到[0, 999]范围,以适应不同输入图像分辨率 。
3D空间理解 (3D Spatial Understanding):针对相对深度排序、绝对深度估计和3D定位三个任务构建数据。相对深度排序数据通过DepthAnything V2从200万互联网图像中推断物体间的深度关系(选取相对深度差距超过20%的物体平均深度)生成32亿令牌 。绝对深度估计数据来源于公开数据集,通过对应的标注深度图确定每个语义掩码实体的绝对深度,产生1800万指令对和280亿令牌 。3D定位数据利用公开数据集并将其重构为问答对形式(提示特定类别物体的3D位置),产生77万指令遵循对和13亿令牌 。
视频 (Video):数据主要分为三类以提升模型对多帧时序图像的理解。第一类是通用视频理解数据,包括视频字幕、视频问答、动作识别、动作定位和多图像理解,数据源自公开数据集和内部收集的视频-字幕对 。第二类是用于增强时间感知能力的视频时序定位和片段检索的公开数据集,模型直接预测用户提示的开始和结束时间戳 。第三类是视频流数据,用于理解动态连续内容,包括:交错字幕/问答数据(对分割的视频片段进行字幕生成或构建按时间顺序的多轮问答对)、主动推理数据(将定位的视频问答和密集字幕数据重构为逐帧响应格式)和实时评论数据(利用自然时间同步的视频评论提供细粒度的图文对齐) 。
科学、技术、工程和数学 (STEM):为增强预训练阶段的推理能力,整合了跨STEM领域的问题解决数据。图像理解数据包括320万个跨数学、物理、化学和生物等领域的高质量教育定位样本,1000万个多样化格式的结构化表格,450万个化学结构图和150万个合成坐标系图 。K12字幕数据包含10万人工标注的教育图像字幕、100万VQA对、100万机器生成字幕和数十万几何特定字幕 。问题解决数据则包含超过1亿条经过清洗和重构的K12级别练习,数千万条精选的中文成人教育问题和数百万条英文图文关联问题 。
图形用户界面 (GUI):主要使用从UI-TARS策划的数据,以支持稳健的GUI感知、定位和推理 。数据集涵盖网页、应用和桌面环境,每个截图都配有通过自动解析和人工辅助探索收集的结构化元数据(元素类型、边界框、文本和深度) 。感知任务包括元素描述、密集字幕和状态转换字幕,旨在让模型识别小型UI组件、理解整体布局并检测帧间细微视觉变化,同时叠加视觉标记 (Set-of-Mark) 以加强空间对应 。定位任务训练模型从文本描述预测元素坐标,边界框在不同分辨率间进行归一化 。推理任务则收集多步任务轨迹,每个轨迹都标注有观察、中间思考和行动,使模型能够学习逐步规划、纠正和反思 。
Training Recipe
Seed1.5-VL的VLM预训练方法分为三个阶段 。
阶段0:仅训练MLP适配器以对齐视觉编码器和语言模型,冻结其他两个模块;省略此阶段会导致损失略高和性能下降 。
阶段1:所有模型参数均可训练,通过在包含3万亿令牌的多模态语料库(主要由字幕、交错图文、视觉定位和OCR数据组成)上训练,专注于知识积累和掌握视觉定位及OCR能力;经验发现,加入少量纯文本令牌(如5%)有助于维持模型的纯语言能力,少量指令遵循数据则能带来更可靠的评估结果 。
阶段2:创建跨不同任务更均衡的数据混合,并加入新领域数据(如视频理解、编码和3D空间理解),同时将序列长度从32768增加到131072,以更好适应视频中的长依赖建模和复杂推理问题;此阶段所有模型参数均可训练 。报告还提到,其实验表明当前训练食谱(先对齐MLP,再全参数训练)优于先训练MLP和视觉编码器(冻结LLM)的策略,推测后者可能因视觉编码器试图弥补冻结LLM的不足而损害其感知能力 。所有三个阶段均使用AdamW优化器,并详细列出了各阶段的学习率、批大小等超参数 。
Scaling Laws
在预训练的阶段1,研究了固定模型参数数量情况下,训练损失 L 与训练令牌数量 D 之间的关系,发现其近似遵循幂律关系 。具体到OCR和定位相关数据集的训练损失,其与训练令牌数量的对数呈现线性关系 。此外,分析表明特定数据子类别的训练损失可以作为相关下游任务性能的预测器,两者之间呈现近似对数线性关系(例如,评估指标 simlog(损失)),尽管这种关系可能仅在性能值的局部邻域内持续,因为评估指标通常有界(如0到1之间) 。例如,ChartQA和InfographicVQA数据集上的top-1准确率与OCR训练损失的对数显示出明确的相关性,RefCOCO评估基准的性能也与模型的定位训练损失相关 。
后训练 (Post-training)
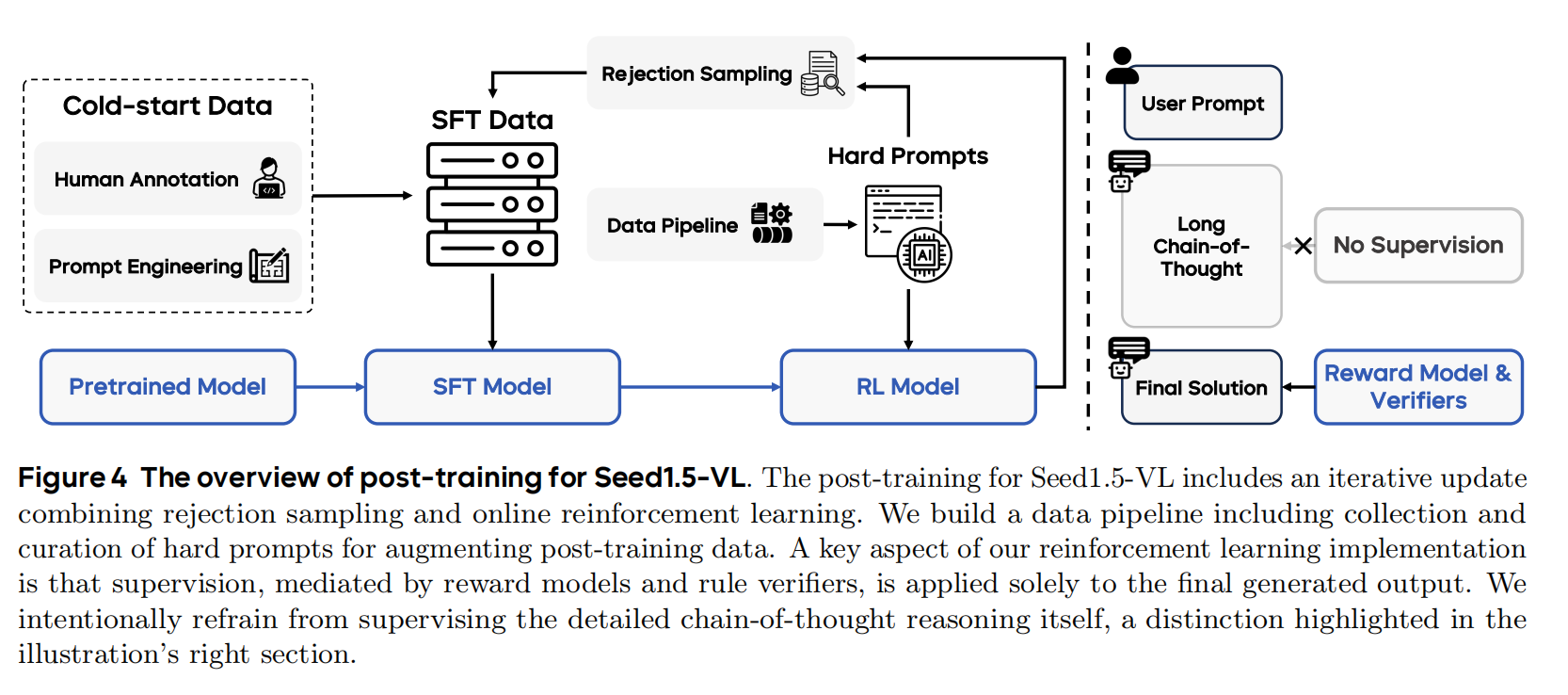
后训练阶段通过监督微调 (SFT) 和强化学习 (RL) 的结合,赋予Seed1.5-VL强大的指令遵循和推理能力 。该过程始于一个在精心策划的冷启动数据上训练的SFT模型 。一个关键组成部分是数据管线,它持续收集困难且多样的提示,这些提示既用于RL,也通过拒绝采样改进SFT数据 。后训练以迭代方式进行:SFT模型通过蒸馏RL模型在多样化提示上的学习成果而逐步增强,直至提示池耗尽且性能指标收敛 。最终产出的Seed1.5-VL能够生成简洁的快速回复以及具有长链思考 (LongCoT) 推理的深度响应 。
监督微调 (Supervised Fine-tuning, SFT)
SFT阶段为Seed1.5-VL在强化学习前构建了基础的指令遵循和推理能力 。SFT数据集包含两部分:通用指令数据,训练模型处理多样复杂指令并生成简洁准确的回复;长链思考 (LongCoT) 数据,专注于生成详细的逐步推理,这些数据主要通过对Seed1.5-VL高质量输出进行提示工程和拒绝采样产生 。SFT数据构建初期,通过众包收集了约13000条高质量指令调优数据,并结合从约150万条开源数据中精心筛选和LLM辅助过滤的30000条高质量样本 。随后,利用自指令方法 (self-instruct) 合成新的复杂提示及其模型响应,并通过人工二次验证进行修正,这种方式比直接人工标注更高效,且能排除超出模型当前能力范围的数据,减少幻觉风险 。SFT训练时,视觉编码器参数被冻结,其余参数可训练,使用了约5万样本的多模态SFT数据与内部纯文本SFT数据及LongCoT SFT数据结合,训练了两个周期,序列长度为131072,批大小为序列长度的16倍,并使用了AdamW优化器及特定的学习率调度策略 。
从人类反馈中强化学习 (Reinforcement Learning from Human Feedback, RLHF)
RLHF通过收集偏好数据、训练奖励模型和使用强化学习算法进行优化,进一步提升模型的用户评估性能和多模态理解能力 。偏好数据通过人工标注(对多个候选模型响应进行5分制评分,并要求标注员选出最少修改即可完善的回复)和启发式合成(对有明确答案的多模态提示生成多个模型响应,并使用现有VLM评估其正确性和格式依从性来建立排序)来收集 。奖励模型使用指令调优的VLM初始化,并训练其作为生成式分类器直接输出对两个响应偏好的指示符令牌,通过计算两种响应顺序的概率来减轻潜在的位置偏差,并采用迭代学习策略持续更新训练数据和标注指南以保持标准一致性 。用于RL训练的提示来源于偏好数据集,并通过一个多阶段数据精炼管线(包括打标签、分层采样、基于奖励模型评分方差的过滤和对低难度任务的降采样)来确保提示的质量和分布均衡性 。
基于可验证奖励的强化学习 (Reinforcement Learning with Verifiable Rewards, RLVR)
RLVR利用可精确验证最终解决方案的任务(如数学推理和编码)的答案匹配或约束验证来训练模型,而非依赖基于模型的奖励估计 。针对视觉STEM任务,收集了超过一百万个主要涉及数学的带图问题,将多选题转化为开放式问题,并通过拒绝采样筛选出对SFT模型有挑战性的题目(准确率在0%到75%之间),同时移除了仅靠文本或文本加字幕就能回答的问题,以避免强化对文本或肤浅视觉元素的依赖 。模型被指示用特定LaTeX标识符格式化最终答案,以便自动提取和验证 。对于视觉感知和推理任务,如定位(通过IoU计算奖励)、视觉指令遵循(通过正则表达式验证结果)以及视觉谜题和游戏(如“找不同”,模型需输出自然语言解释和定位差异区域的边界框),也收集或合成了可验证反馈的数据 。“找不同”游戏的合成数据通过随机遮蔽图像片段后用扩散模型修复,或系统地修改SVG属性来生成,以确保模型能感知细微差异 。
混合强化学习 (Hybrid Reinforcement Learning)
Seed1.5-VL采用基于PPO算法变体的混合RL框架进行训练,该框架结合了生成式奖励模型 (RM) 以及RLHF和RLVR 。具体实现包括:预定义<think>{thought}</think>{solution}的响应格式,不符合格式则奖励为零,并对不符合特定验证器格式要求的响应进行惩罚 ;训练提示分为通用提示(由RM奖励)和可验证提示(由验证器奖励),在每个批次中随机混合,RM仅关注最终解决方案的奖励,忽略CoT思考过程,以鼓励模型探索更有效的CoT思路 ;使用共享的 critic 模型(参数由预训练奖励模型初始化并经过预热)来估计对应于RM和验证器两种奖励来源的价值函数,两种奖励信号均归一化到[0, 1]范围 ;对通用提示应用较小的KL散度系数 (1times10−5) 以减轻奖励hacking,对可验证提示则不使用KL散度项以促进模型探索 。训练上下文长度为8192,最大输出长度为16384,每个episode采样4096个rollout,每个episode执行8个梯度步骤,actor和critic的学习率分别为 6times10−7 和 7.5times10−7 。
通过拒绝采样微调进行迭代更新 (Iterative Update by Rejection Sampling Fine-tuning)
采用迭代训练策略在RL阶段增强Seed1.5-VL。该过程始于一个LongCoT的冷启动SFT模型,该模型最初是在少量通过对基础模型进行上下文提示(使用少量人工标注示例)生成的低质量LongCoT样本上训练的 。由于观察到更强的冷启动SFT自然会导致LongCoT RL后更强的最终模型,因此采用拒绝采样微调方法来获得更好的起点 。具体而言,在LongCoT RL模型的每次迭代发布后,通过数据管线收集额外的挑战性提示,并评估最新的RL模型在这些提示上的表现 。然后,以拒绝采样的方式收集正确回答的响应,并将其纳入下一次SFT发布的数据中,使用RL阶段相同的验证器来确认这些响应的正确性 。此外,还实施了手动制作的基于正则表达式的过滤器,以去除不良模式,如无限重复、过度思考和其他语言缺陷 。当前的Seed1.5-VL版本已经过了四轮这样的迭代,并显示出持续的改进 。
训练基础设施 (Training Infrastructure)
为加速和稳定预训练,开发了包括混合并行、工作负载平衡、并行感知数据加载和稳健训练在内的一系列训练优化措施,并应用了高性能注意力核心、选择性激活检查点和卸载、核心融合以及细粒度通信重叠技术 。
大规模预训练 (Large-Scale Pre-training)
针对VLM数据(视觉数据和自然语言)和模型(小型视觉编码器和大型语言模型)的异构性带来的挑战,开发了一种混合并行方法 。该方法对视觉编码器和MLP适配器利用ZeRO数据并行,而对语言模型则使用标准的4D并行(结合专家并行、流水线并行、ZeRO-1数据并行和上下文并行) 。通过贪心算法重新分配视觉数据以实现视觉编码器和适配器的工作负载平衡,并采用分组平衡(如每组128-256个GPU)以减少数据重新分配开销 。并行感知数据加载器通过例如仅让流水线并行组中的一个GPU加载数据然后广播元数据,以及在将训练批次移动到GPU前过滤掉不必要的图像来减少多模态数据I/O开销和PCIe流量,并通过预取器确保I/O和计算完全重叠 。利用稳健训练框架MegaScale实现故障容忍,一旦检测到故障即触发恢复过程从上一个成功检查点继续训练,并使用ByteCheckpoint进行高效的检查点保存和恢复 。
后训练框架 (Post-Training Framework)
Seed1.5-VL的混合强化学习(RLHF和RLVF)在一个基于verl的框架上进行,该框架结合了用于管理RL角色间数据流的单控制器和用于管理RL角色内数据与模型并行的多控制器 。验证器部署在基于进程的服务中以隔离潜在故障,简化了部署和开发 。使用了与预训练阶段相同的训练系统和优化技术进行高效的actor和critic更新,并使用vLLM进行rollout的自回归生成 。具体来说,actor和critic训练采用3D并行;rollout生成和奖励/参考模型推理使用副本,每个副本配置张量并行 。后训练阶段同样利用ByteCheckpoint进行高效的检查点保存和恢复 。
评估 (Evaluation)
评估章节全面展示了Seed1.5-VL在多种基准测试和任务上的性能。
公开基准 (Public Benchmarks)
在零样本图像分类基准测试中,Seed-ViT(视觉编码器)在ImageNet-1K等多个数据集上取得了平均82.5的准确率,与参数量远大于己的InternVL-C-6B相当,并在ObjectNet和ImageNet-A等更具挑战性的数据集上表现优于DFN-5B-CLIP-H/14++,显示出其对真实世界变化的更强鲁棒性 。在视觉任务评估中,Seed1.5-VL在“思考”和“非思考”模式下均表现出色,在MathVista、V*、VLM are Blind、ZeroBench (sub) 和VisuLogic等多个复杂多模态推理任务上取得了SOTA性能 。在文档和图表理解方面,它在TextVQA、InfographicVQA和DocVQA上创造了新的SOTA基准 。特别值得一提的是,Seed1.5-VL在所有列出的定位和计数基准(如BLINK, LVIS-MG, Visual WebBench, RefCOCO-avg, Count Bench, FSC-147)上均取得了SOTA性能,显示了其在物体定位、细粒度视觉理解和计数方面的卓越能力 。在3D空间理解方面,无论是在相对深度估计 (DA-2K)、绝对深度估计 (NYU-Depth V2) 还是多视角推理 (All-Angles Bench) 上,Seed1.5-VL均显著超越了先前的VLM 。视频任务评估涵盖短视频、长视频、流视频、视频推理和视频定位五个维度,Seed1.5-VL在MotionBench、TVBench、Dream-1K、TempCompass等短视频理解任务以及所有流视频理解基准(OVBench, OVOBench, StreamBench, Streaming Bench (proactive))上均取得了SOTA性能,并在视频定位任务Charades-STA和TACOS上也表现出色 。
多模态智能体 (Multimodal Agent)
在GUI交互和游戏两大场景中,Seed1.5-VL展示了强大的能力 。GUI定位方面,在ScreenSpot Pro和ScreenSpot v2上的表现优于OpenAI CUA和Claude 3.7 Sonnet 。GUI智能体能力评估中,Seed1.5-VL在OSWorld、Windows Agent Arena、WebVoyager和Online-Mind2Web等多个基准上均超越了先前的模型,取得了SOTA成果,并在具挑战性的移动界面任务AndroidWorld上也取得了高分,整体在GUI智能体任务中表现优异 。游戏智能体基准测试中,Seed1.5-VL在多个游戏中(如2048, Hex-Frvr)的表现也超越了OpenAI CUA和Claude 3.7 Sonnet,并且在推理时间扩展性方面表现出强大的可伸缩性,即随着交互轮次的增加性能持续提升 。
内部基准 (Internal Benchmarks)
为克服公开基准中英文为主、部分已饱和以及评估方法局限等问题,团队构建了内部基准套件 。该套件遵循核心原则:关注核心能力而非用户对齐、评估范围全面(原子能力和集成能力)、采用LLM作为裁判并持续优化评估准确性(目前多选/简单答案准确率高于95%,开放式问题高于90%)、通过数据去重和定期更新任务/数据源来减轻基准过拟合,以及强调任务和输入多样性(超过100个任务,12000多个样本,并包含专门的OOD类别) 。在与业界领先模型的比较中 (Gemini 2.5 Pro, OpenAI o1, OpenAI 04-mini, Claude 3.7),Seed1.5-VL在思考模式下取得了第二高的总分,并在OOD、智能体、原子指令遵循类别中表现SOTA,在STEM和文档/图表理解方面能力强劲,主要差距体现在知识、推理、代码和字幕/反事实任务上,这部分归因于当前模型规模(约20B活动参数的LLM),但规模效应分析表明通过增加模型大小和训练计算有望缩小差距 。在OOD泛化能力方面,Seed1.5-VL表现与Gemini Pro 2.5和OpenAI o1相当,并通过内部Chatbot平台展示了其在复杂真实场景中整合多种原子能力解决非常规任务(如解Rebus谜题、从白板照片中提取并修正代码、解析新格式图表生成Mermaid代码)的能力 。