
《Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data》清华刘知远团队出品
摘要
模型驱动的数据过滤仍然面临两大挑战:(1)缺乏有效的数据验证策略,难以对数据质量提供及时的反馈;(2)用于训练分类器的种子数据选择缺乏明确标准,且过度依赖人工经验,引入了一定的主观性。针对第一个挑战,我们提出了一种高效的验证策略,能够以极低的计算成本快速评估数据对 LLM 训练的影响。针对第二个挑战,我们基于高质量种子数据有利于 LLM 训练的假设,结合提出的验证策略,优化了正负样本的选择,并提出了一种高效的数据过滤流程。该流程不仅提升了过滤效率、分类器质量和鲁棒性,还显著降低了实验和推理的成本。此外,为了高效过滤高质量数据,我们采用了一种基于 fastText 的轻量级分类器,并将该过滤流程成功应用于两个广泛使用的预训练语料库,即 FineWeb 和 Chinese FineWeb 数据集,从而创建了更高质量的 Ultra-FineWeb 数据集。Ultra-FineWeb 包含约 $1$ 万亿个英语 Token 和 $1200$ 亿个中文 Token。实验结果表明,在 Ultra-FineWeb 上训练的 LLM 在多个基准测试任务中表现出显著的性能提升,验证了我们的流程在提升数据质量和训练效率方面的有效性。
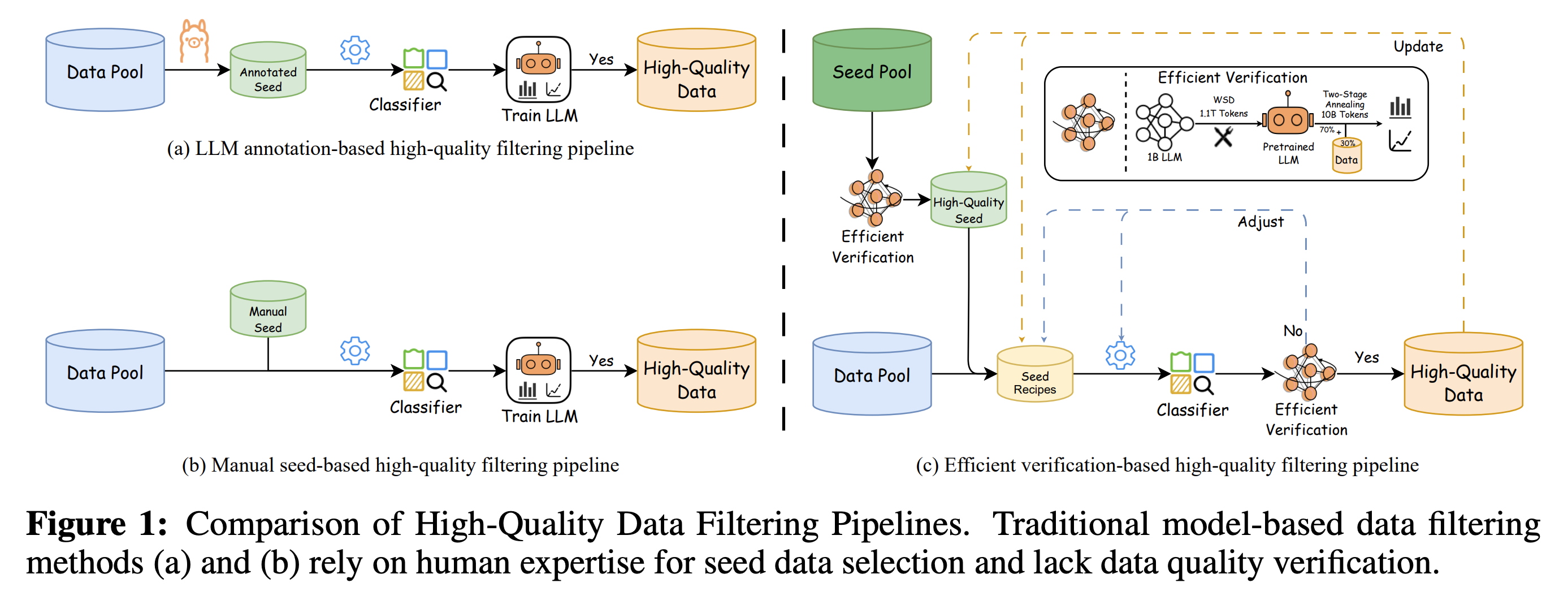
总体工作流
所提出的基于高效验证的高质量过滤管道的总体工作流程如图1(c)所示。我们首先构建一个初始候选种子池,并应用我们的高效验证策略来识别能够显著提高训练性能的高质量样本。这些经过验证的样本作为正样本种子,用于训练分类器,而负样本则从原始数据池中随机选择,以创建一个平衡的训练集。在分类器过滤阶段,我们从原始数据池中抽取一个小样本子集,并使用我们的高效验证策略来验证分类器的选择,以评估其有效性。基于验证结果,我们迭代更新高质量种子池,调整正样本和负样本的比例,并微调分类器训练超参数,以优化数据选择策略。只有在高效验证中表现出稳定可靠性能的分类器才会被部署用于全尺度数据选择和后续模型训练,从而在保持高数据质量的同时,显著降低计算成本。
高效验证策略
验证训练数据的有效性通常需要大量的计算资源。例如,在一个包含1000亿 (B) 个 Token 的数据集上训练一个 10 亿参数的大语言模型 (LLM),大约需要 1200 个 H100 GPU 小时(相当于 64 个 GPU 连续运行近 19 小时)。当迭代开发高质量的数据分类器时,这种计算负担变得尤其令人望而却步。此外,大规模的训练验证对于较小的数据集来说是不切实际的,因为使用有限的 Token 数量训练的模型无法表现出具有统计意义的性能差异,而训练的不稳定性进一步损害了结果的可靠性。这种限制在我们对 FineWeb 和 FineWeb-edu 的比较分析中很明显。当从头开始使用 80 亿个 Token 进行训练时,FineWeb-edu 在 HellaSwag 上取得了优异的性能,而在 3800 亿个 Token 时,FineWeb 在包括 Winogrande、HellaSwag 和 PIQA 在内的多个基准测试中表现更好,这突出了基于训练规模的评估结果的不一致性[^1]。

受到 Llama 3.1 的启发,我们设计了一种高效验证策略。我们首先使用 WSD 调度器(包括在 1 万亿个 Token 上进行稳定训练,然后在 0.1 万亿个 Token 上进行衰减训练)在一个 10 亿参数的大语言模型上训练 1.1 万亿 (T) 个 Token。基于这个预训练的大语言模型,我们然后使用 100 亿个 Token 实施一个两阶段退火过程,将 30% 的权重分配给验证数据,同时保持剩余 70% 用于默认混合数据比例。如表1所示,这种优化策略将计算成本从 1200 个 H100 GPU 小时降低到大约 110 个 H100 GPU 小时(相当于在 32 个 GPU 上不到 3.5 小时),从而显著降低了训练成本,并有效地提高了过滤过程的效率和可迭代性,其中使用原始混合数据比例的两阶段退火结果作为基线。这种策略允许有效评估验证数据在各种评估维度上的影响。为了验证该策略的可靠性,我们比较了分别使用 FineWeb 和 FineWeb-edu 在 10 亿参数的大语言模型上从头开始训练 1000 亿个 Token 的结果。
分类器训练Seeds
高质量数据分类器的有效性从根本上取决于优质正样本的选择。如图1(a)所示,诸如FineWeb-edu、Chinese-FineWeb-edu和CCI3-HQ等数据集采用基于大语言模型 (LLM) 注释的框架来部分标记源一致的数据,从而生成“种子数据”。相比之下,图1(b)展示了基于人工筛选种子的过滤(DCLM)流程,该流程依赖于人工筛选来选择正样本,特别关注指令格式的数据,并结合了来自OpenHermes 2.5 (OH-2.5) 和 r/ExplainLikeImFive (ELI5) subreddit 的高质量帖子。
虽然这两种流程在选择正样本方面都表现出明显的优势,但它们也伴随着固有的局限性。基于大语言模型 (LLM) 注释的流程可以有效地从源一致的数据中过滤高质量样本,但其性能受到大语言模型 (LLM) 评分标准的限制,可能会引入系统性偏差和注释噪声。此外,仅在源一致的数据上训练的分类器通常表现出有限的泛化能力和较差的鲁棒性。相反,人工筛选面临着重大的方法论挑战:种子数据的有效性在分类器训练之前很难评估,并且其验证在很大程度上依赖于在大语言模型 (LLM) 使用过滤后的数据进行训练后的性能。这些限制导致高计算成本和降低了跨不同任务的适应性。
基于这些考虑,我们提出了一个关键假设:能够提高大语言模型 (LLM) 性能的高质量种子数据将产生能够识别类似有益训练数据的分类器。如图1 (c) 所示,我们实施了高效验证策略,以快速评估和验证候选池中种子数据的质量,从而确保选择能够改善大语言模型 (LLM) 训练结果的样本。该流程不仅确保了卓越的数据质量,还优化了过滤效率,从而为分类器训练生成更可靠的正样本。此外,为了提高分类器的鲁棒性,我们将负样本的选择范围扩大到源一致的数据之外。实验结果进一步表明,结合多样化的数据源作为负样本可以提高分类器的泛化能力。
分类器训练配方
我们评估了大量的候选种子数据,并最终选择了那些具有明显有效性的作为正样本。正样本包括:(1)AI 智能体标注的得分高于4[^2]^,^[^3]的数据;(2)指令格式的数据集,如OH-2.5和ELI5;(3)真实的教科书数据;(4)AI 智能体合成的教育数据;以及(5)通过有针对性的爬取获得的高质量网络内容。对于负样本,我们在初始迭代中纳入了来自不同来源的原始数据,包括英语语料库(FineWeb、C4、Dolma、Pile和RedPajama)和中文数据集(IndustryCorpus2、MiChao、WuDao、SkyPile、WanJuan、ChineseWebText、TeleChat和CCI3)。为了保持数据集的多样性和平衡,我们实施了均匀分布策略,代表性不足的类别会进行3-5轮的战略性重采样。
随后,我们进行了一次分类器的迭代,利用其当前的预测作为下一轮的训练数据。然而,经验结果表明,迭代过程仅在第一轮中做出了有意义的贡献,因为随后的更新并没有产生进一步的性能改进,在某些情况下,甚至导致了大语言模型(LLM)性能的下降。我们的分析表明,分类器的改进主要取决于种子数据的选择,而不是使用推断样本进行迭代改进。有趣的是,我们发现通过多个分类器过滤的高质量数据的交集始终可以提高大语言模型(LLM)的性能。
基于 FastText 的质量过滤
目前高质量数据分类器主要分为基于大语言模型 (LLM) 和基于 fastText 的方法。虽然基于大语言模型的分类器效果很好,但它们需要显著更高的推理成本。为了解决这个问题,我们采用了一种基于 fastText 的分类器,它在保持一定条件下具有竞争力的性能的同时,显著降低了推理成本。这种方法不仅最大限度地减少了资源消耗,而且加快了数据过滤实验。例如,如表[2所示,使用基于大语言模型的分类器处理 15T Token 大约需要 6,000 个 H100 GPU 小时,而 fastText 可以在非 GPU 机器上仅用 80 个 CPU 在 1,000 小时内完成相同的任务,从而显著提高了效率。值得注意的是,我们的大多数大规模实验都是使用 Spark[^4] 集群以分布式方式进行的。

对于数据预处理,我们实现了几个关键步骤,包括删除冗余的空行和多余的空格,去除变音符号,并将所有英文文本转换为小写。此外,我们采用了 DeepSeek-V2 Tokenizers,它优于传统的 Tokenization 方法(例如,基于空格的英文 Tokenization 和 Jieba[^5] 中文 Tokenization)。同时,我们保留了诸如 \n、\t 和 \r 之类的结构信息。为了确保数据集的完整性和平衡性,最终的训练集包含 60 万个样本,正例和负例各占一半。
关于训练细节,我们训练了一个 fastText 分类器,其向量维度为 256,学习率为 0.1,最大单词 n-gram 长度为 3,最小单词出现阈值为 5,总共进行了 3 个训练轮次。此外,在推理过程中,我们保持默认阈值 0.5 以简化操作并确保实验一致性,避免了额外的调整步骤。
实验




