
《Seed-Coder: Let the Code Model Curate Data for Itself》
这篇论文的核心启发在于提出了一种最小化人工参与、以模型为中心的数据构建管线pipeline来生产大语言模型(LLM)的代码预训练数据。关键做法是利用LLM本身进行代码数据的评分和筛选,而不是依赖大量人工制定的、针对特定语言的过滤规则或人工标注数据。基于此,他们推出了Seed-Coder系列8B模型(基础、指令、推理),并通过监督微调、偏好优化(DPO)以及长链思维(LongCoT)强化学习来进一步提升指令遵循和多步代码推理能力,展示了这种数据策略在提升模型代码相关任务(生成、补全、编辑、推理、软件工程)上的卓越表现。
引言部分强调了现有开源代码LLM在预训练数据构建上对人工的重度依赖(如手工规则过滤)所带来的局限性,包括可扩展性差、主观偏见和维护成本高。最具启发性的一点是作者引用“The Bitter Lesson”来说明AI领域的发展趋势:依赖大规模计算和数据的通用方法最终会胜过依赖人类知识的复杂方法。Seed-Coder正是基于这一理念,倡导使用LLM来自动化代码数据的筛选和评估,从而克服人工方法的瓶颈,并构建了一个包含6万亿token的预训练语料库。
预训练:
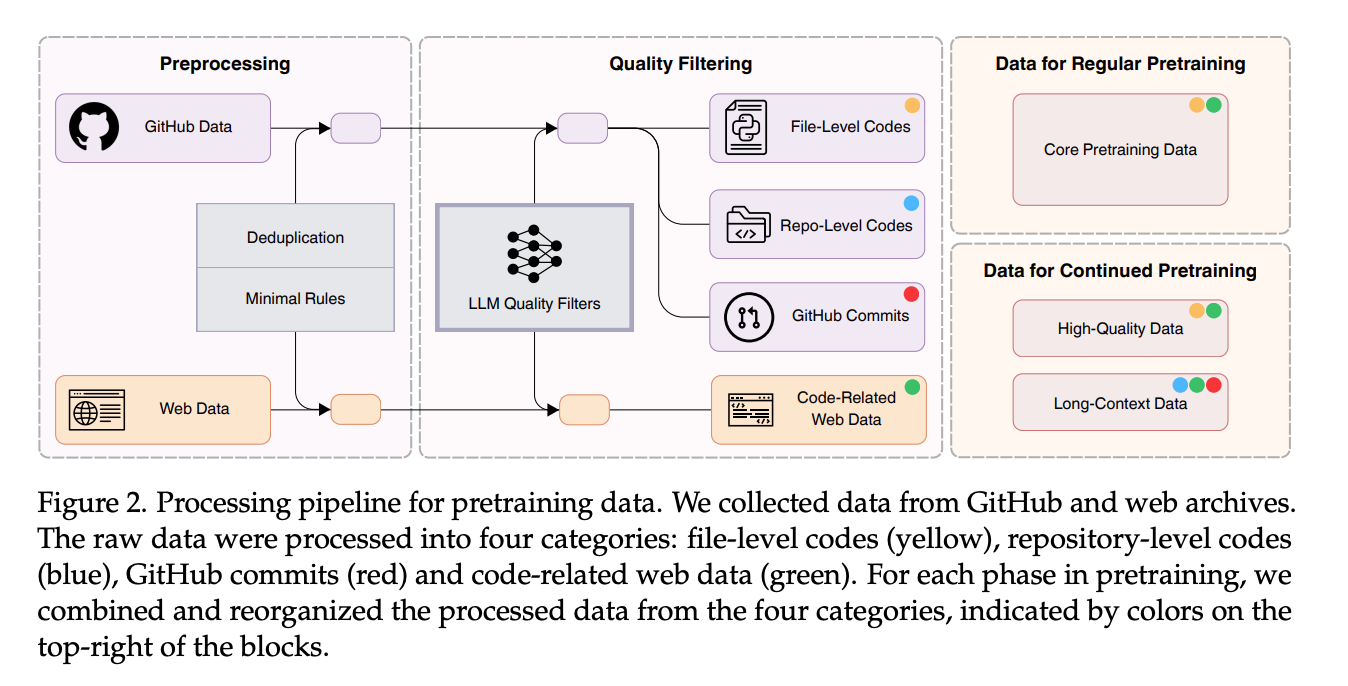
数据管线 (Data Pipeline): 启发性在于其解耦的并行设计,允许各个处理模块(如去重、基础过滤、LLM高级质量过滤)独立运行,便于增量扩展和灵活调整,避免了重新运行整个冗长流程。数据被分为文件级代码、仓库级代码、提交记录和代码相关的网页数据四类,并针对不同预训练阶段(常规预训练和持续预训练)进行组合。
数据成分 (Data Ingredients):
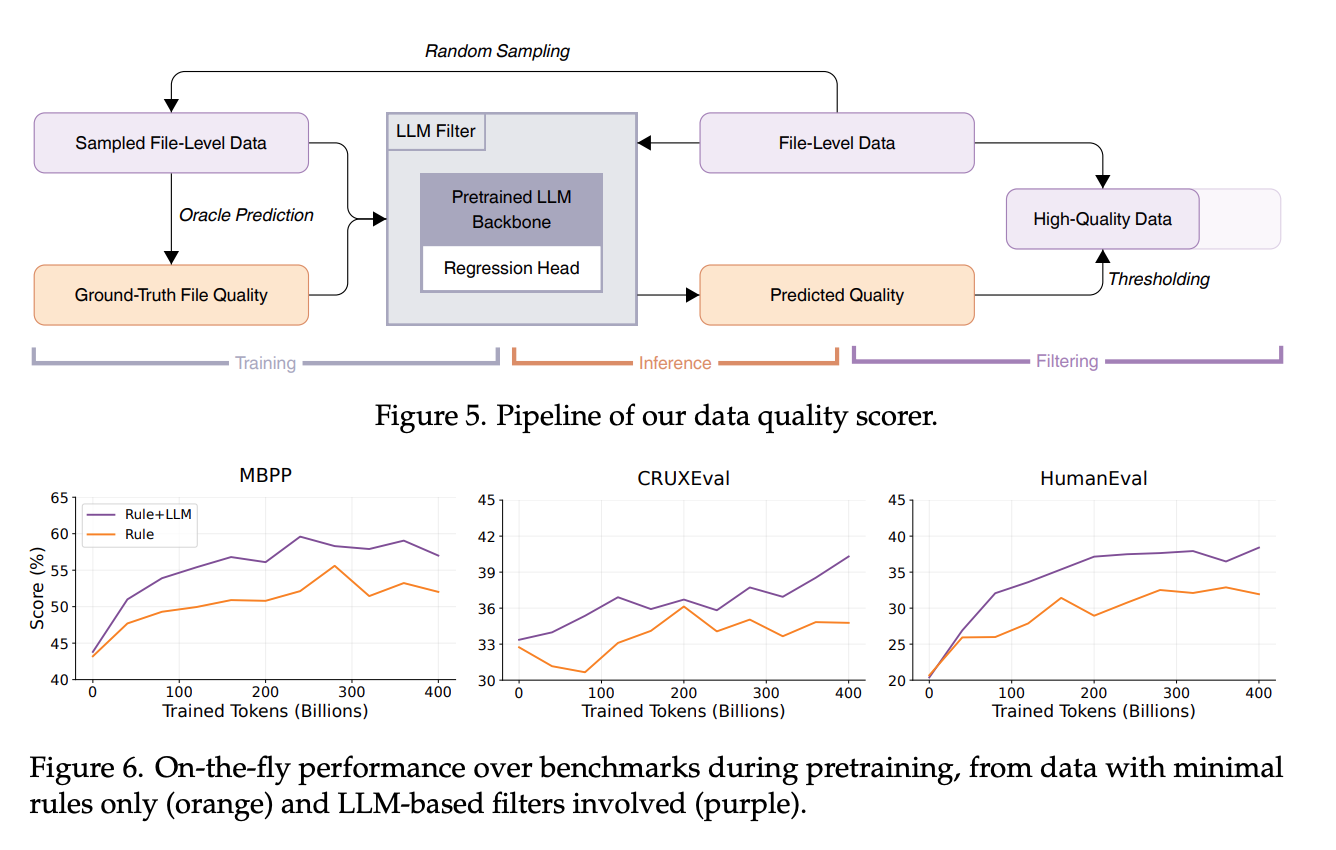
GitHub数据: 关键做法是构建一个LLM驱动的文件级质量评分模型。他们随机抽取代码文件,让一个“神谕”模型(DeepSeek-V2-Chat)从可读性、模块化、清晰度和可复用性四个维度打分,然后用这些评分数据微调一个13B的Llama 2模型作为高效的质量评估器,过滤掉低质量文件。这比传统基于规则的过滤更能捕捉代码质量的细微差别且可扩展性强。
提交数据 (Commits Data): 做法是将GitHub提交记录格式化为代码变更预测任务,利用提交信息和上下文(包括README、目录结构和BM25检索的相关文件)预测修改的文件和代码补丁,从而让模型学习真实世界的代码演化模式。
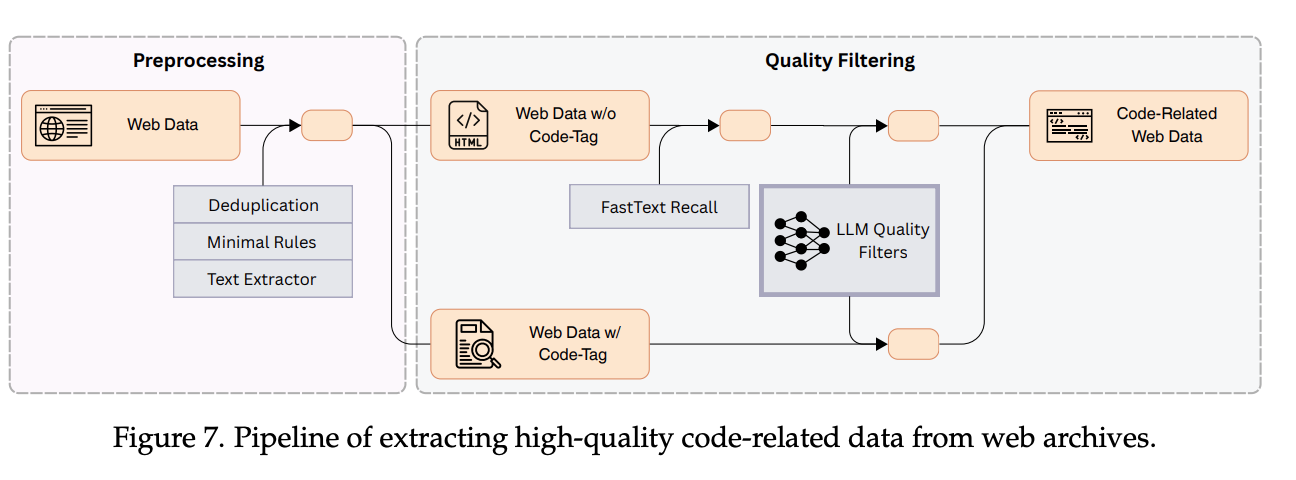
代码相关的网页数据: 亮点在于一个优化的两阶段提取框架:首先通过规则提取和fastText模型进行大规模召回(在标注数据上训练,实现高召回率),初步筛选出代码相关内容;然后使用LLM质量过滤器进行精细评估和筛选,并特别注意缓解不同网站类型(如电商、文档、论坛)带来的打分偏见。
用于持续预训练的高质量数据: 关键在于迭代训练fastText模型。先基于特定特征(如质量分、语言、注释率)构建小的种子数据集作为正样本,并精心设计难负样本(如高分但无注释的代码,或第一轮fastText召回但质量分低的数据),以提升fastText模型的判别能力,通过2-3轮迭代扩展高质量数据集。
用于持续预训练的长上下文数据: 通过支持高达32K的序列长度进行长上下文训练。文件级数据通过LLM过滤,而仓库级数据则针对主流语言(Python, Java, C)实施了基于文件依赖关系的拓扑拼接,对于HTML, SQL, Shell等则使用随机拼接,大型仓库则分解为子图,以在保持逻辑连贯性的同时适应上下文窗口。
Fill-in-the-Middle (FIM): 实践中发现SPM(Suffix-Prefix-Middle)模式比PSM模式略好,可能与注意力机制的位置偏见有关。采用字符级随机分割,并在常规和持续预训练阶段设置不同FIM比例。
预训练策略 (Pretraining Policy): 采用了Llama 3架构,82亿参数,分阶段进行预训练,从混合数据开始,然后是大量代码数据,最后在持续预训练阶段转向高质量和长上下文数据,并相应调整学习率。
后训练:
后训练部分展示了如何从预训练好的基础模型进一步打造出强大的指令模型和推理模型。
指令模型 (Instruct Model):
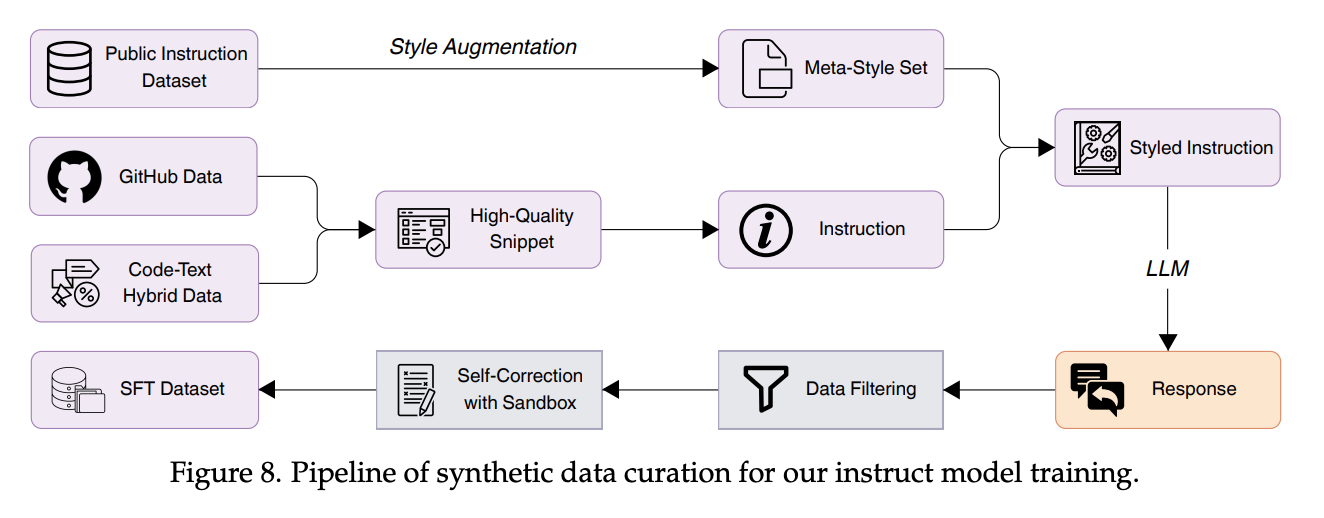
数据构建:多样性 (Data Construction: Diversity): 核心是合成数据生成,强调种子片段多样性(来自高质量GitHub、OSS-Instruct、Markdown/Jupyter/StackExchange等代码-文本混合数据以模拟真实交互)和风格多样性(构建元风格集并随机混合风格,再结合WildChat数据)。
数据过滤:质量与难度 (Data Filtering: Quality and Difficulty): 结合规则(Tree-sitter去语法错误)和模型(LLM评估正确性)进行质量过滤;通过主题分类和模型评估难度来筛选出过于简单的实例。
沙盒验证的自我修正 (Self-Correction with Sandbox Verification): 这是一个非常实用的做法。为了保留高难度样本(它们通常错误率也高),模型被提示生成解决方案和单元测试,在沙盒中评估,并对失败的方案进行迭代修正,直到测试通过或达到最大尝试次数。
直接偏好优化 (Direct Preference Optimization - DPO): 为了增强代码生成和推理能力,构建了基于策略的偏好数据。选取任务相关提示,采样多个候选回复,在沙盒中用生成的代码和单元测试进行评估,然后形成偏好对进行DPO训练。
指令模型训练秘诀 (Training Recipe for Instruct Model): SFT阶段使用约300万高质量指令对,并采用难度感知采样优先训练高难度样本;DPO阶段使用约2万个专注于挑战性任务的偏好对。
推理模型 (Reasoning Model):
数据 (Data): 收集具挑战性的真实世界代码问题(CodeContests, ICPC)和模型生成的解(DeepSeek-R1),以及开源CoT数据集。关键在于对CodeContests/ICPC数据进行基于沙盒的拒绝采样,只保留正确生成,为预热提供强监督。RL训练数据则结合了LiveCodeBench等。
预热步骤 (Warmup Step): 从基础模型(而非指令模型,因后者在RL中易崩溃)开始,在数千个收集到的LongCoT样本上进行微调。重要的是,作者没有过度扩大蒸馏数据量,以保留模型自身的探索空间,为后续RL自提升留有余地。
推理模型训练秘诀 (Training Recipe for Reasoning Model): 使用GRPO进行RL训练,并进行了两项关键优化:1)优化的课程学习:不仅过滤完全正确或错误的样本,还进一步过滤掉简单问题(正确率>87.5%)中思维过程冗余的样本,以及那些因格式奖励而未被GRPO过滤掉的“简单”正例(含格式错误),以鼓励更高效地利用思维token;2)渐进式探索策略:逐步扩大序列长度和每个提示的rollout数量(例如,先16K序列/16样本,后32K序列/32样本),这在早期训练阶段显著提高了效率。
去污染 :
本章的关键做法是采用了广泛应用的10-gram词重叠过滤方法,对所有预训练和后训练数据,针对关键基准测试集(如HumanEval, MBPP等)进行了严格的去污染处理,以确保评估的公正性。
结果:
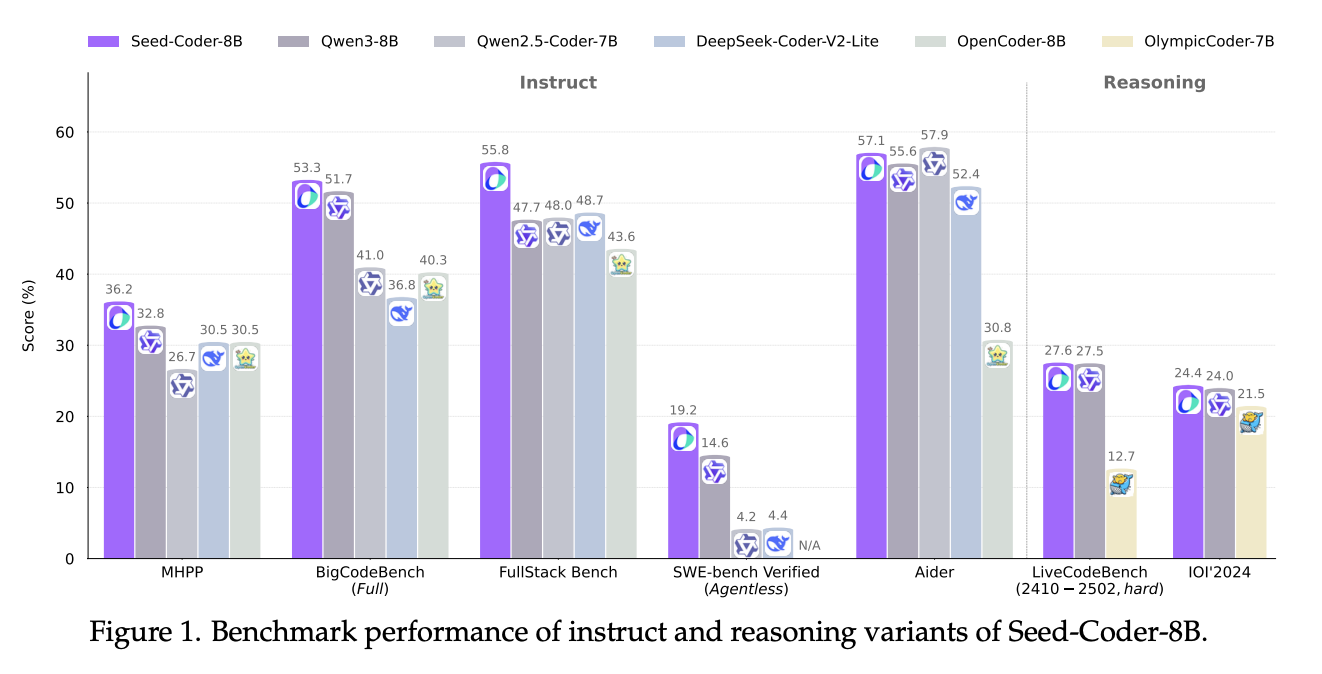
结果部分通过在大量基准测试上的表现,验证了Seed-Coder系列模型的性能。对于启发性而言,除了展示其模型(基础、指令、推理)在各个代码任务(生成、补全、推理、长上下文、编辑、软件工程)上的SOTA或有竞争力的表现外,还有以下几点值得注意:
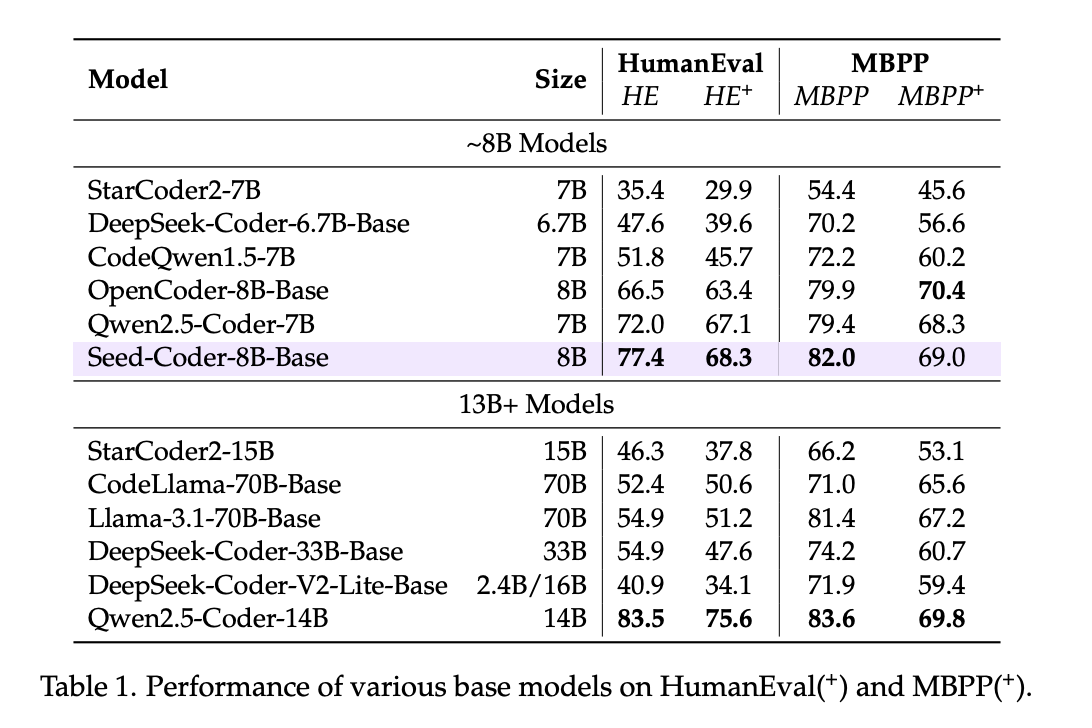
在评估基础模型时,他们注意到某些“基础”模型在使用聊天模板后性能显著提升,这提醒我们在评估时需注意统一设置或明确说明。
指令模型在更难的基准(如MHPP, FullStack Bench, NaturalCodeBench)上表现出色,显示了模型中心数据策略和精心后训练的有效性。特别是在软件工程任务(SWE-bench)中,Seed-Coder-8B-Instruct在需要自主规划的OpenHands框架下表现突出,这归功于其强大的指令遵循能力(通过LLM过滤器保证训练数据格式一致)和通过训练中加入命令数据增强的软件工程技能。
推理模型通过RL训练在LiveCodeBench等竞赛级任务上获得显著提升,尤其是在中高难度问题上,显示了RL在挖掘模型潜力上的作用。但也指出了在顶级竞赛难题上与最高水平仍有差距,且当前序列长度限制可能影响了模型上限。
结论:
结论重申了模型中心的数据管线在构建高质量代码LLM方面的有效性,并强调了8B规模模型取得的优异成果。尽管未明确列出,但从全文讨论中可以推断出局限性可能包括LLM评分的成本与潜在偏见、评估真实推理能力的挑战、现有基准的覆盖面以及RL训练的计算开销等。未来工作可能涉及进一步优化和扩展模型中心的数据管理方法,提升LLM评估器的能力,开发更好的推理基准,以及探索更高效的RL技术。