
《Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding》
作者揭示了一个有悖常理的现象:在注意力机制中,极端数值异常地聚集于 Query (Q) 与 Key (K) 的表征区域,而 Value (V) 中则无此现象。值得注意的是,未使用 RoPE(旋转位置编码,如 GPT-2 模型)的模型中并未观察到这一特性。
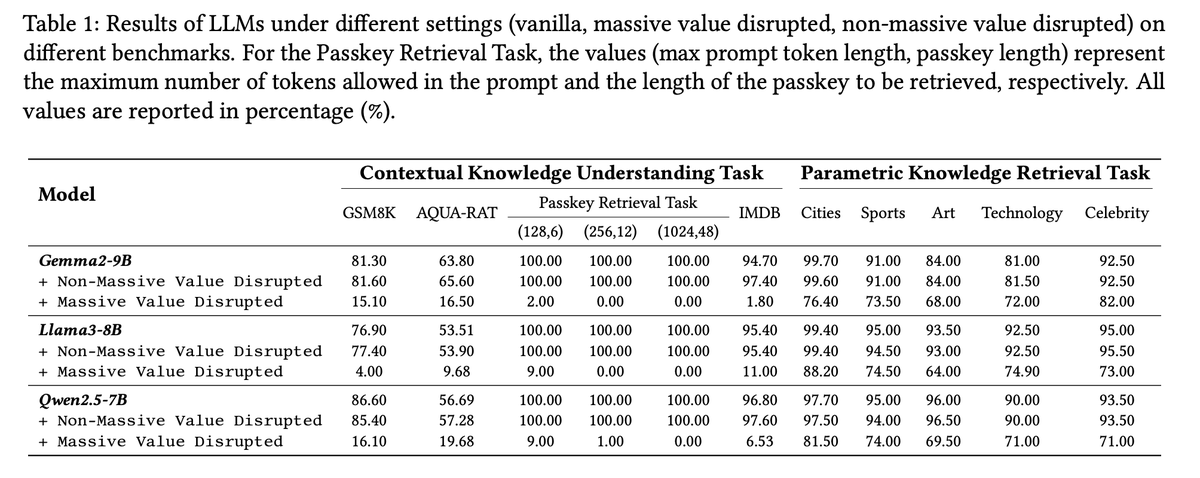
此类极端数值对模型的上下文理解能力至关重要,相较之下,其对于参数化知识的倚重程度则较低。实验显示,若此类数值受到干扰,模型仍能回忆既有事实(例如,回答“中国首都是哪里?”),但在需要依赖上下文的任务中(如 GSM8K 数学推理测试),其表现则会显著下滑。
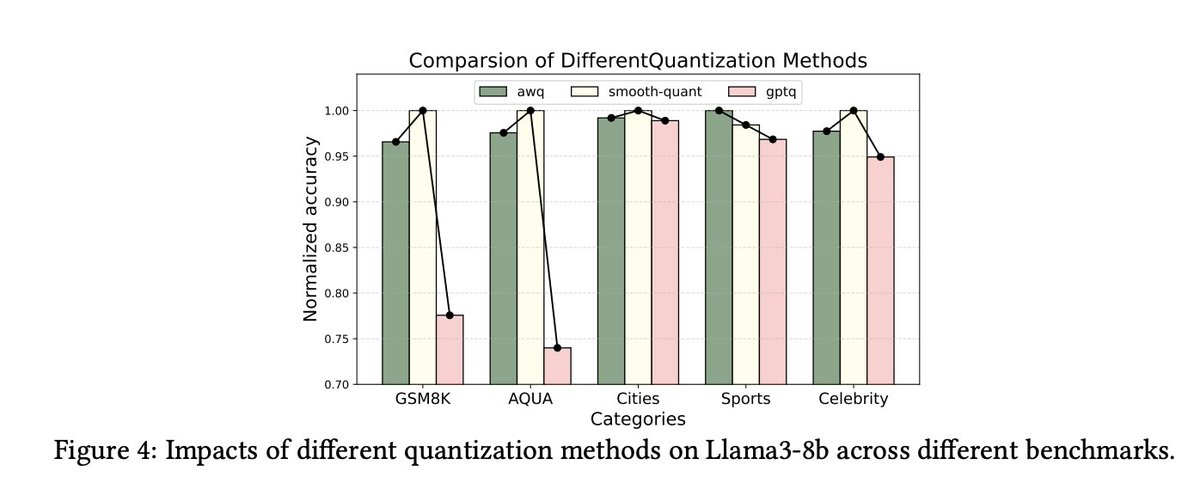
那些特意保留这些极端数值的量化技术(例如 AWQ 和 SmoothQuant)能够维持模型的原有性能;反之,若采用未能保留这些数值的方法(例如 GPTQ),模型的上下文推理能力将遭受重创。
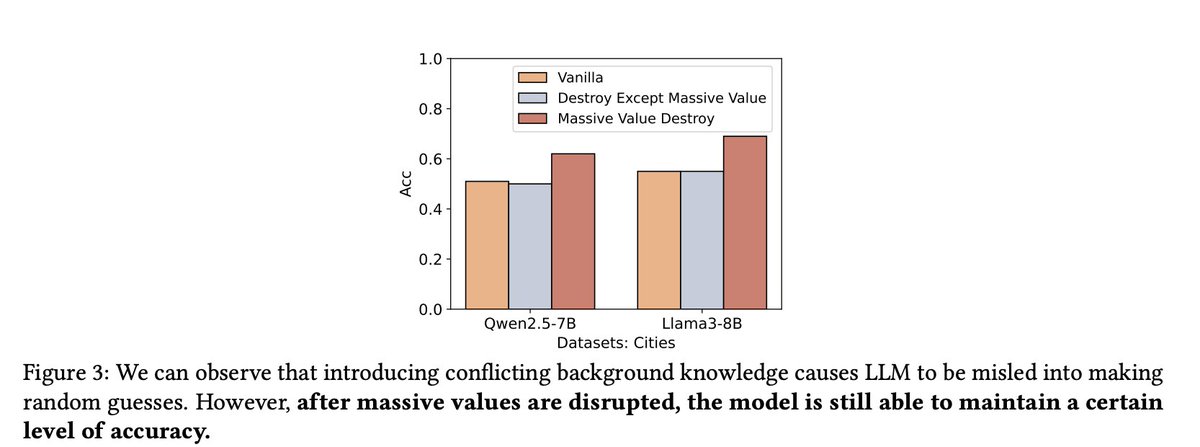
当作者刻意让上下文信息与模型的内在知识产生冲突时,发现 LLMs (大语言模型) 的表现与随机猜测无异。然而,有选择地扰动那些“巨大值”反而提升了模型的准确率,这暗示 LLMs (大语言模型) 在默认情况下更倾向于依赖其内部知识,而这些“巨大值”则在引导模型理解上下文方面扮演着关键角色。
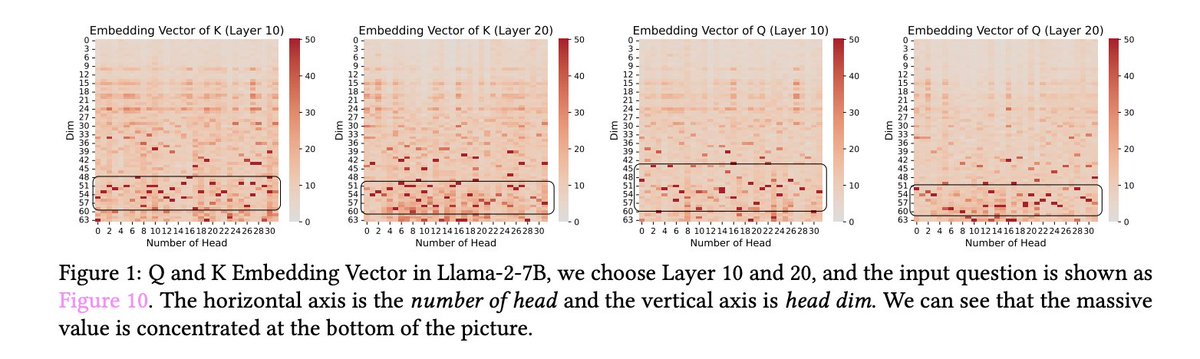
这种“巨大值”高度集中的现象,其根源直接指向 Rotary Position Encoding (RoPE) 技术。具体来说,RoPE 技术仅选择性地作用于 Query (Q) 和 Key (K) 向量,而将 Value (V) 排除在外,从而导致了极端数值在 Q 和 K 表征中的独特聚集。
在涵盖自回归 LLM (大语言模型) 及多模态模型等多种 Transformer 架构中,作者均一致地观察到了这种“巨大值”集中的现象。这进一步印证了作者的假说,即 RoPE 是驱动 QK 表征中结构化“巨大值”出现的根本原因。
本研究为理解 LLMs (大语言模型) 中“巨大值”的角色及其成因开启了新的视角。作者发现,这些“巨大值”对于需要依赖上下文的任务——例如密钥信息检索、文本情感分析以及逻辑推理——具有不可或缺的作用,而对于参数化知识的直接调取,其影响则相对有限。
RoPE 机制促使“巨大值”在 Q 和 K 的表征中(尤其是在低频通道内)形成集中模式,这种模式在未采用 RoPE 的 LLMs (大语言模型) 中则付之阙如。这些发现不仅揭示了为保证推理能力而保留这些“巨大值”的重要性,也阐明了其与 RoPE 技术之间的内在联系。