《Youku Dense Caption: A Large-scale Chinese Video Dense Caption Dataset and Benchmarks》
数据集地址:https://www.modelscope.cn/datasets/os_ai/Youku_Dense_Caption
摘要
随着视频内容的爆炸式增长,视频字幕已成为视频理解的关键工具,显著增强了从视频中理解和检索信息的能力。然而,大多数公开可用的密集视频字幕数据集都是英文的,导致大规模、高质量的中文密集视频字幕数据集稀缺。为了弥补中文社区内的这一差距并推动中文多模态模型的发展,我们开发了首个大规模、高质量的中文密集视频字幕数据集,名为优酷密集字幕(Youku Dense Caption)。该数据集来源于中国著名的视频分享网站优酷。优酷密集字幕包含 31,466 个完整的短视频,由 311,921 条中文字幕标注。据我们所知,它是目前公开可用的最大的细粒度中文视频描述数据集。此外,我们基于优酷密集字幕建立了多个中文视频-语言任务的基准,包括检索、定位和生成任务。我们在现有的最先进的多模态模型上进行了广泛的实验和评估,证明了该数据集的实用性和进一步研究的潜力。
1 引言
目前,大多数公开可用的密集视频字幕数据集主要是英文的,导致非英语语言,特别是中文的资源显著匮乏。这种语言差距不仅限制了中文用户的体验,也阻碍了针对中文视频内容的多模态模型的开发和优化 (Li et al. 2019; Singh et al. 2020)。
为了解决这一关键差距并促进中文多模态模型的进步,我们引入了优酷密集字幕数据集,这是第一个大规模、高质量的中文密集视频字幕数据集,精心设计以满足中文视频内容理解和信息检索的需求。该数据集来源于中国领先的视频分享平台之一优酷,包含 31,466 个完整的短视频,标注了 311,921 条中文字幕。这使其成为公开可用的、用于中文视频内容细粒度描述的最大、最详细的数据集,从而为中文视频-语言处理研究提供了重要的资源。
除了提供全面的数据集外,我们还基于优酷密集字幕数据集为中文视频-语言任务建立了几个基准。这些任务包括视频检索、定位和字幕生成。这些基准不仅为现有多模态模型的客观评估提供了严格的设置流程,也为该领域的未来研究和发展方向提供了指导。
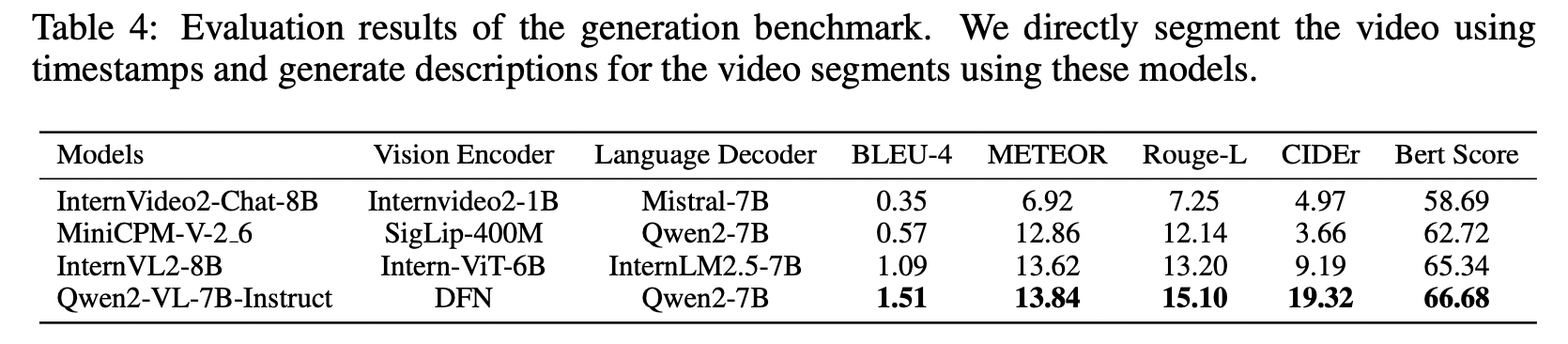
为了验证优酷密集字幕数据集的效用,我们使用最先进的多模态模型进行了广泛的实验和评估。这些实验的结果证明了该数据集在提高模型性能方面的显著影响,包括视频检索和字幕生成。通过这项研究,我们强调了优酷密集字幕数据集在推动中文视频-语言发展领域的潜力。
我们的主要贡献如下:
- 我们介绍了优酷密集字幕数据集,这是最大且完全由人工标注的中文视频密集字幕数据集,包含 31,466 个短视频和 311,921 条中文字幕。
- 我们为中文视频-语言任务建立了几个基准,包括视频检索、定位和字幕生成,为多模态模型提供了标准的评估指标。
- 我们通过广泛的实验验证了该数据集的有效性,证明了其在增强多模态模型生成和检索性能方面的显著影响。
3 优酷密集视频描述数据集
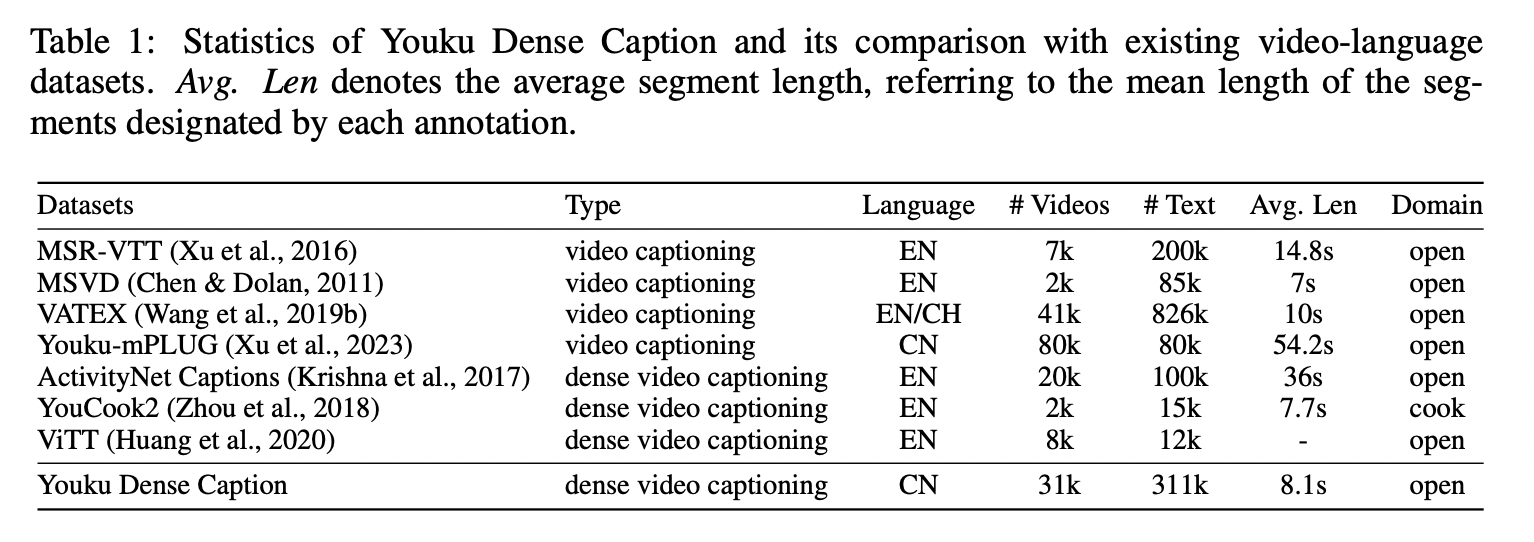
为了填补中文社区在细粒度标注数据集方面的空白,我们推出了首个带有详细中文标注的大规模密集视频描述数据集。该数据集共包含 31,406 个视频,分割为 311,921 个片段,累计时长达 748.96 小时。每个视频的平均时长为 85.68 秒,平均片段长度为 8.1 秒。每个视频平均包含 9.9 条标注,每条标注平均包含 17.9 个字。从数据清理到中文标注的生成,整个过程均由人工精心完成,以确保最高的数据质量。
3.1 数据来源
该数据集的构建旨在满足以下要求:1)应涵盖最常见的视频主题;2)视频时长不应少于一分钟,以确保内容有意义。基于这些要求,密集字幕数据集中的原始视频是根据 11 个主要类别和 84 个子类别从优酷-mPLUG 数据集中均匀抽样的。
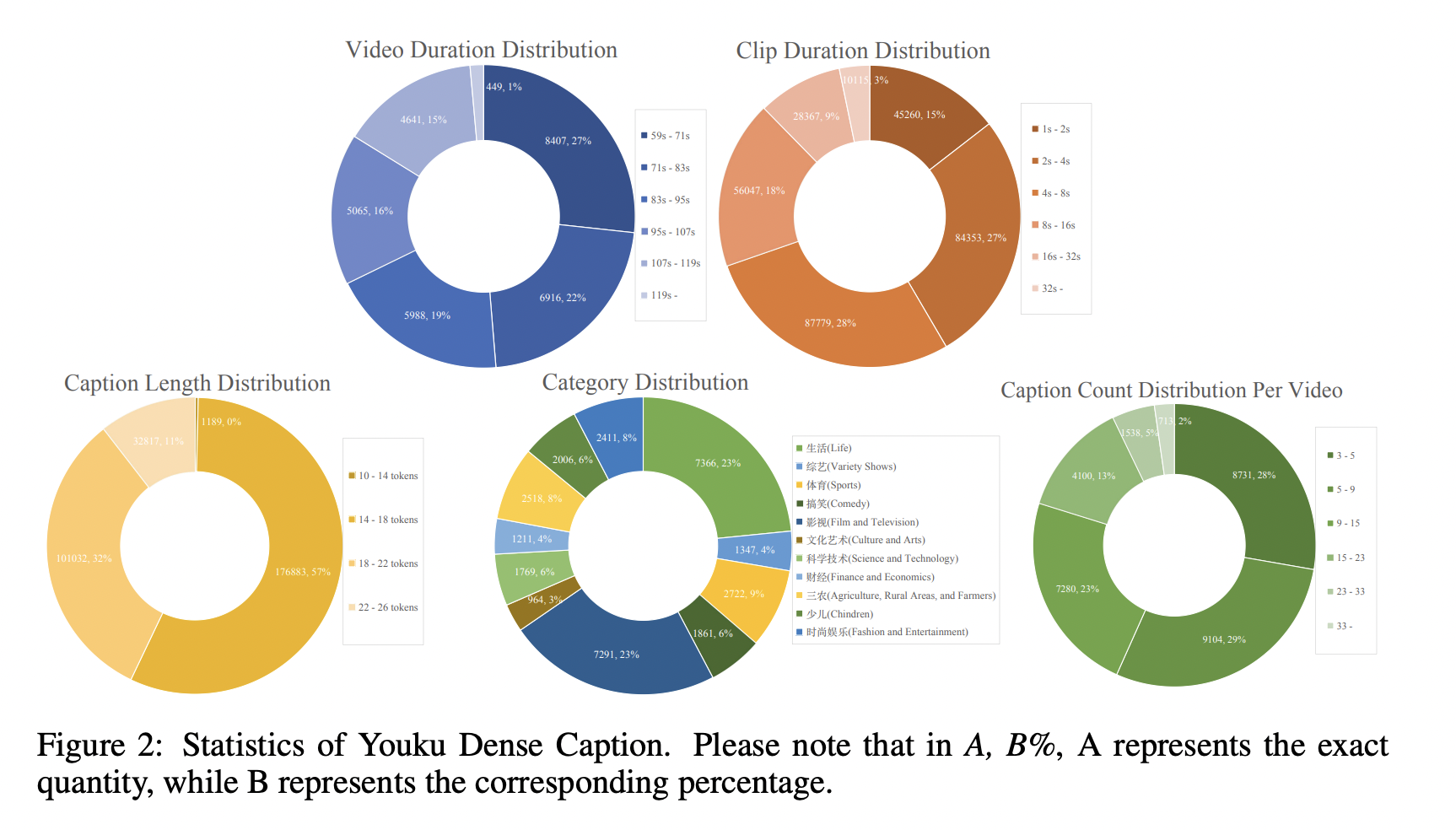
3.2 统计数据和特征
我们现在展示优酷密集字幕数据集的统计数据,并将其与其他类似数据集进行比较。图 2 总结了优酷密集字幕数据集在视觉和语言内容方面最显著的方面。
3.2.1 基本统计数据

优酷密集字幕数据集以其多样性和丰富性为特点,使其成为视频理解、字幕生成和自然语言处理研究的宝贵资源。
- 广泛的类别覆盖。 该数据集包括 11 个粗粒度类别(例如,生活、综艺、财经、农业、儿童、时尚娱乐)和 84 个细粒度子类别(例如,影视包括电影、电视剧、动漫等)。这种广泛的范围确保了对开放领域视频类型的全面覆盖。
- 均衡的视频时长。 99% 的视频时长在 1 到 2 分钟之间,既确保了内容的丰富性,也保证了细粒度标注的可行性。时长段相对均衡,每个时长段约占数据集的 20%,为不同视频长度提供了良好的代表性。
- 短片段聚焦。 数据集主要包含 2 到 32 秒的片段,非常适合短视频内容分析和处理。片段时长的均匀分布有助于模型在不同片段长度上的泛化能力。
- 一致的字幕长度。 字幕主要在 10 到 26 个 Token 之间,大部分在 18 到 22 个 Token 范围内。这种一致性支持密集字幕生成和短文本生成任务,有助于在训练期间保持稳定的模型性能。
- 丰富的字幕信息。 每个视频包含 3 到 33 个字幕,为密集字幕生成和视频内容理解研究提供了充足的数据。这种分层分布有助于研究不同字幕密度下的视频理解和生成。
3.2.2 中国特色
首先,中文和英文社区在文化背景和语境理解上存在显著差异。中国文化的独特元素,例如茶道、中秋赏月和春节问候(如拜年),在公开的英文数据集中很少见,但在中文语境中却很普遍。这种文化差异不仅体现在标注文本的分布上,也体现在视频内容中。
正如广泛使用的 Chinese CLIP (Yang et al., 2022) 所强调的那样,通过突出这些独特的文化元素来弥合标注上的鸿沟,对于准确的翻译和内容表征至关重要。通过弥合这些文化差异,我们的数据集不仅能更好地反映中国用户的实际需求,而且在标注分布和视频内容方面也提供了更高的准确性和文化相关性。
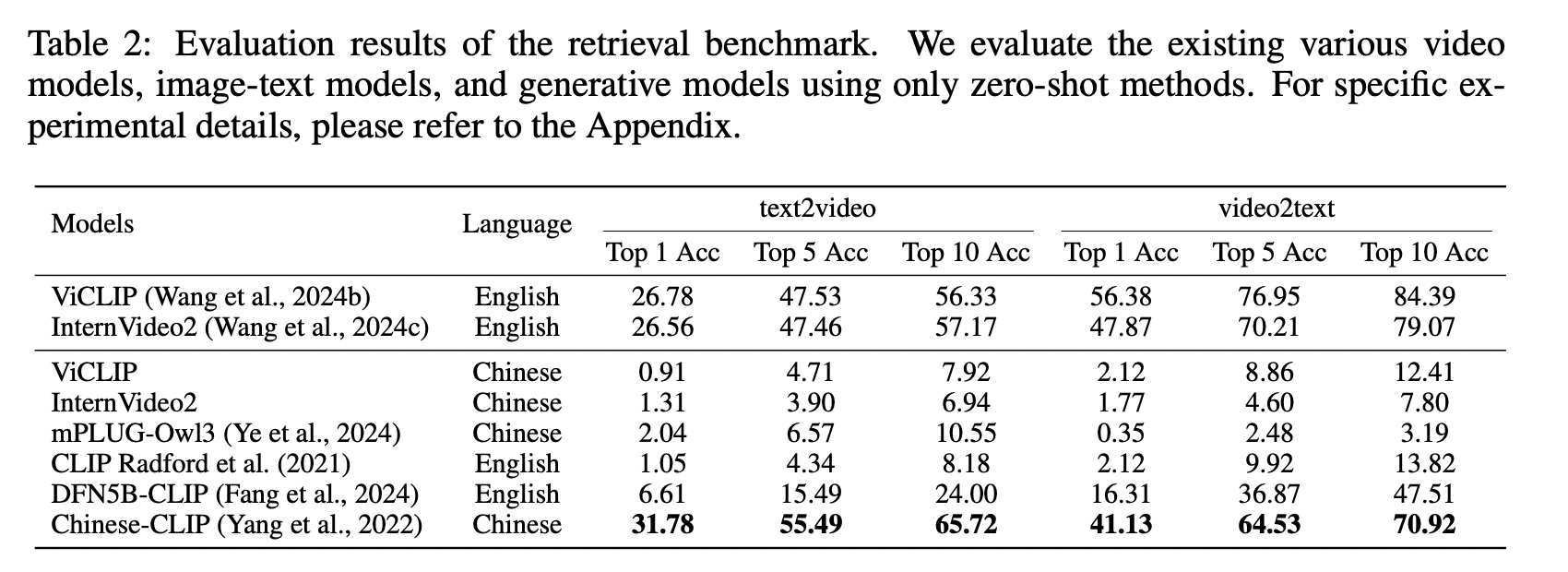
4.1 部分相关视频检索
如果一个未剪辑的视频包含与给定文本查询相关的片段,则认为该视频与该查询部分相关。部分相关视频检索(Partially Relevant Video Retrieval, PRVR)(Dong et al., 2022a)旨在从海量的未剪辑视频集合中识别并检索出这些部分相关的视频。现有的英文基准数据集,例如 TV Show Retrieval(Lei et al., 2020)、ActivityNet Captions 以及 Charades-STA(Gao et al., 2017),直接利用带有片段级标注的视频在视频内部进行搜索。这种方法忽略了相似片段和标注可能存在于不同视频中的情况,导致这些相似的标注会匹配到多个视频,而非特定于单个视频。此外,这些相似的标注在评估时引发了近乎重复的检索过程,从而加剧了基准评估中的偏差。为解决此问题,我们对数据进行了后处理,以构建一个中文 PRVR 基准。该基准确保单个查询对应多个视频,同时避免重复的查询检索,进而能够进行偏差更小的评估。 首先,我们提取片段级别的标注和视频 ID 对,构成 (ti, Vi) 对。接着,我们利用 xiaobu-embedding 模型来聚合相似的文本,该模型已在多项中文检索任务中达到当前最佳水平。对于每一个标注文本 ti,我们计算其嵌入表示,然后识别出所有嵌入相似度超过 90% 的其他标注文本,并将与这些相似文本相关联的所有视频 ID 聚合起来,形成一个视频 ID 集合 Vi。这样,对于每个标注文本 ti,就存在一个对应的集合 Vi,表示集合 Vi 中的所有视频均包含与 ti 相关的片段。
在第二步中,我们着重于移除重复的标注文本,以避免冗余。我们采用了一种类似于物体检测任务中常用的非极大值抑制(Non-Maximum Suppression, NMS)的方法。

首先,我们计算每对集合 $V_i$ 和 $V_j$ 之间的交并比 (IoU)。IoU 定义为两个集合交集的大小除以并集的大小。 如果 $V_i$ 和 $V_j$ 之间的 IoU 超过 0.7,我们认为 $t_i$ 和 $t_j$ 的检索过程是冗余的。为了解决这种冗余,我们比较集合 $V_i$ 和 $V_j$ 的大小。如果 $\text{len}(V_j) > \text{len}(V_i)$ ,我们保留较大的集合 $V_j$ 并移除标注 $t_i$ 及其对应的集合 $V_i$ 。【注意:此处根据算法步骤12修正了描述,原文描述中此处有误,误将 $V_i$ 写为 $V_j$。修正后的逻辑是:保留较大的集合,移除与较小集合关联的标注及其集合】。这个迭代过程确保我们保留最具代表性和信息最丰富的标注集,从而减少冗余。
通过这些步骤,我们基于优酷密集捕获 (Youku Dense Capture) 构建了一个中文 PRVR 基准,该基准包含 28,988 个查询和 3,185 个目标视频,每个查询平均有 4.96 对相关视频。我们设定了两个评估指标:一个是 Top-k 准确率,即在前 k 个结果中检索到任何一个相关视频即视为命中;另一个是平均精度均值 (Mean Average Precision),用于衡量前 $\text{len}(V_i)$ 个结果中相关视频的比例。
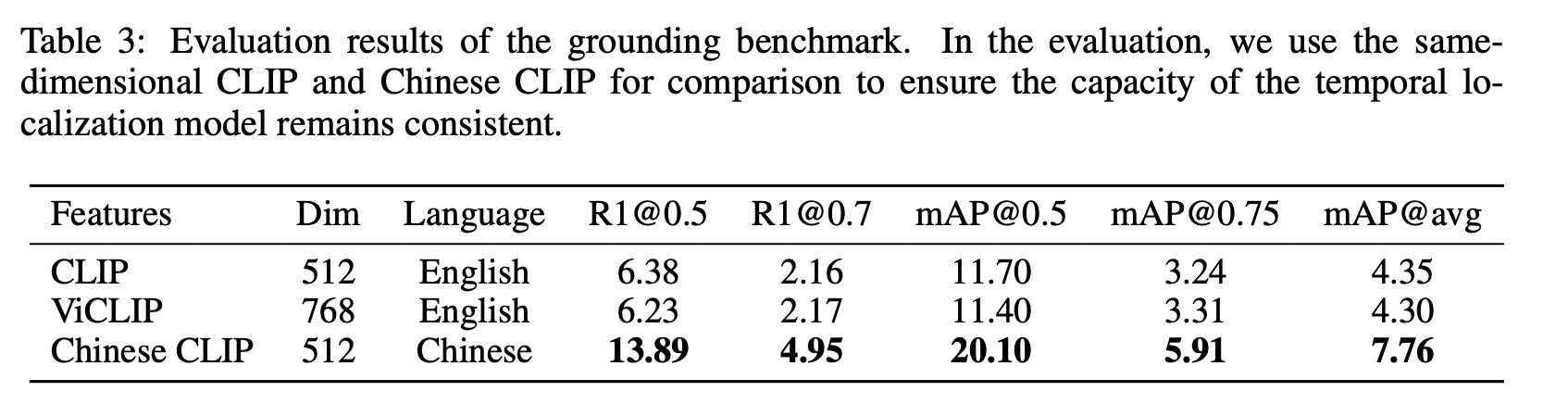
4.2 定位与生成
在时间定位和描述生成的任务中,现有的文本和视频片段标注面临两个主要问题。首先,由于缺乏事件变化,某些视频的标注文本可能包含大量重复信息。这类标注通常意义模糊,未能提供关于视频片段的有效信息描述。其次,视频片段内的场景变化可能不显著。即使视频被划分为不同的时间戳,片段内部的场景变化也很小,导致标注重复单调。这种单调性降低了评估的多样性和客观性,使得这些视频片段不适合用作时间定位和描述生成等任务的评估数据。
为了解决这些问题,我们提出了两种策略来提高基准数据集的质量:首先,我们计算标注文本的内部一致性。具体来说,我们计算每个视频内所有标注文本的 self-BLEU (Zhu et al., 2018) 值。如果一个视频的 self-BLEU 值超过 0.15,则认为标注文本的内部一致性过高,该视频随后被过滤掉。
标注文本 $s_i$ 的 self-BLEU 值计算如下:
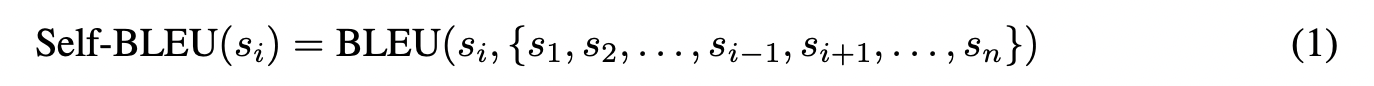
其中 $s_i$ 是正在评估的标注文本,而 $\{s_1,s_2,\ldots,s_{i-1},s_{i+1},\ldots,s_n\}$ 表示同一视频内除 $s_i$ 之外的所有其他标注文本的集合。
然后,一个视频的整体 self-BLEU 计算为该视频中所有标注文本 $s_i$ 的 self-BLEU 值的平均值:
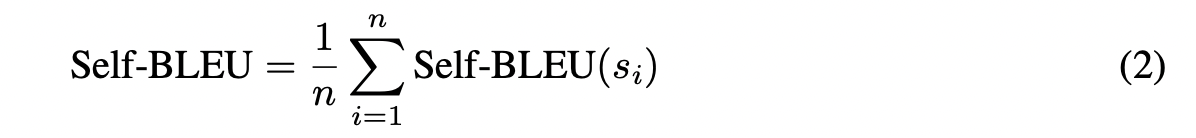
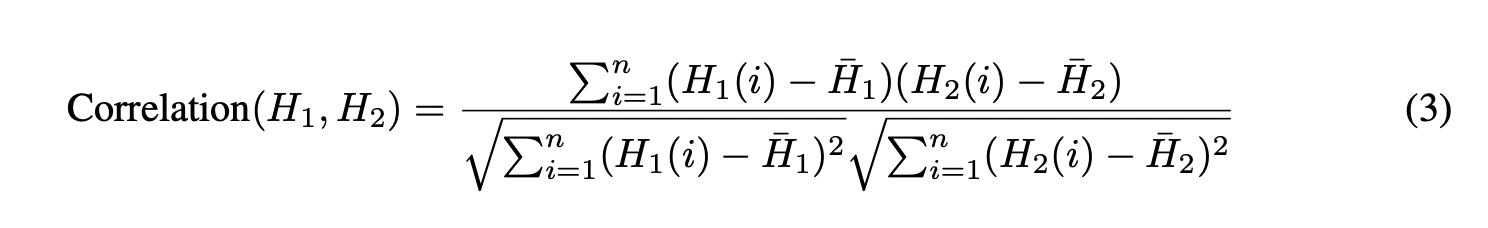
其中 $H_1$ 和 $H_2$ 代表两个视频片段的色彩直方图, $H_1(i)$ 和 $H_2(i)$ 代表直方图中第 $ i$ 个区间 (bin) 的值,而 $\bar{H_1}$ 和 $\bar{H_2}$ 分别代表 $H_1$ 和 $H_2$ 的平均值。平均值计算如下:
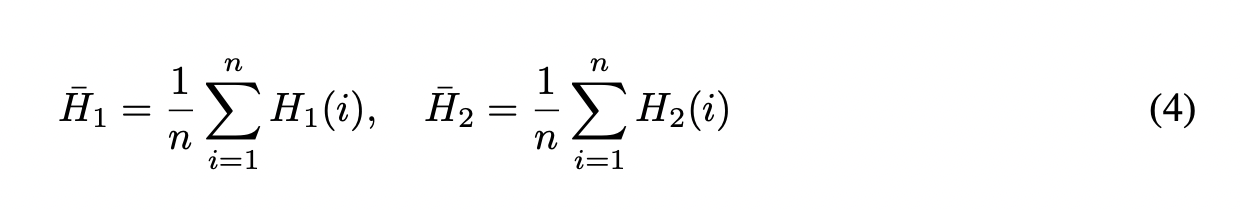
如果相邻视频片段间的色彩直方图相关性超过 0.5,则认为该视频的场景变化不显著,该视频随后被过滤掉。最终,我们获得了 1,872 个视频和总共 20,099 个标注,平均每个视频有 10.73 个标注。
评估指标基于现有工作 (Soldan et al. 2022; Pan et al. 2023)。对于定位任务,我们使用 R@N 和 IoU-M 计算方法,这些方法评估在 IoU 大于 M 的条件下检索到的时间戳的 top-N 准确率。对于描述生成任务,使用主流评估指标,如 BLEU (Papineni et al. 2002)、METEOR (Lavie & Agarwal 2007)、CIDEr (Vedantam et al. 2015) 和 ROUGE-L (Lin 2004),对生成的文本进行全面评估。此外,我们还包括 Bert score (Zhang et al. 2020) 来衡量生成文本的语义相似性,以减轻由不同生成风格引起的评估偏差。
5 实验