
摘要
我们提出VAPO(面向推理模型的基于价值的增强型近端策略优化框架),这是一个专为推理模型设计的新型框架,立足于价值导向范式。在AIME 2024数据集的基准测试中,基于Qwen 32B预训练模型构建的VAPO获得了60.4的最高分。在完全相同的实验条件下进行直接对比时,VAPO的表现超过先前报告的DeepSeek-R1-Zero-Qwen-32B和DAPO模型10分以上。
VAPO的训练过程以稳定性和效率见长。它仅需5,000步即可达到最先进的性能水平。此外,在多次独立运行测试中,未出现任何训练崩溃现象,充分证明了其可靠性。
本研究深入探讨了使用基于价值的强化学习框架进行长思维链(long-CoT)推理。我们识别出影响基于价值方法的三个关键挑战:价值模型偏差、异构序列长度以及奖励信号稀疏性。通过系统化设计,VAPO提供了一个综合解决方案,有效缓解了这些挑战,从而提升了长思维链推理任务的性能表现。
引言
在大语言模型(LLM)的强化学习(RL)训练中,像 GRPO 和 DAPO 这样的无价值方法已展现出显著的有效性。这些方法消除了学习价值模型的计算开销,而是仅根据整个轨迹的最终奖励来计算优势。然后,轨迹级别的优势被直接分配为序列中每个位置的 Token 级别优势。当训练一个可靠的价值模型特别具有挑战性时,无价值方法通过对一个组内多个轨迹的奖励进行平均,为优势计算提供了一个准确且稳定的基线。这种基于组的奖励聚合减轻了对显式价值估计的需求,而显式价值估计在复杂任务中常常存在不稳定性。因此,无价值方法在解决诸如长思维链(CoT)推理等难题方面获得了显著的关注,大量的研究工作都集中在优化其框架上。
尽管不基于价值的方法已取得了显著成功,但我们认为,如果能够克服训练价值模型中的挑战,基于价值的方法则拥有更高的性能上限。首先,价值模型通过精确追踪每个动作对后续回报的影响,能够实现更精确的信用分配,从而促进更细粒度的优化。这对于复杂的推理任务尤为关键,因为在这类任务中,单个步骤的细微错误往往会导致灾难性的失败,而对于在不基于价值的框架下进行优化的模型而言,这仍然是一个挑战。其次,相较于不基于价值的方法中利用蒙特卡洛方法得出的优势估计,价值模型能为每个 Token 提供方差更低的值估计,进而增强训练的稳定性。此外,一个训练良好的价值模型展现出内在的泛化能力,使其能够更有效地利用在线探索过程中遇到的样本。这显著提升了强化学习算法的优化上限。因此,尽管为复杂问题训练价值模型面临着艰巨挑战,但克服这些困难所能带来的潜在收益是巨大的。然而,在长思维链(Long CoT)任务中训练一个完美的价值模型存在显著的挑战。第一,鉴于轨迹漫长以及以自举方式学习价值存在不稳定性,学习一个低偏差的价值模型并非易事。第二,同时处理长响应和短响应也颇具挑战性,因为它们在优化过程中可能对偏差-方差权衡表现出截然不同的偏好。最后但同样重要的是,来自验证者的奖励信号的稀疏性,因长思维链模式而进一步加剧,这内在地要求采用更好的机制来平衡探索与利用。为应对上述挑战并充分释放基于价值的方法在推理任务中的潜力,我们提出了Value Augmented proximal Policy Optimization(VAPO),一个基于价值的强化学习训练框架。VAPO 从 VC-PPO 和 DAPO 等先前的研究工作中汲取灵感,并对其概念进行了进一步扩展。我们将我们的主要贡献总结如下:
- 我们引入了 VAPO,这是首个在长 COT 任务上显著优于无价值方法的基于价值的强化学习 (RL) 训练框架。VAPO 不仅表现出显著的性能优势,而且还展示了更高的训练效率,简化了学习过程,并突显了其作为该领域新基准的潜力。
- 我们提出了长度自适应 GAE (Length-adaptive GAE),它根据响应长度自适应地调整 GAE (Generalized Advantage Estimation) 计算中的 $\lambda$ 参数。通过这样做,它有效地满足了与长度差异极大的响应相关的独特偏差-方差权衡需求。因此,它优化了优势估计过程的准确性和稳定性,特别是在数据序列长度变化广泛的场景中。
- 我们系统地整合了先前工作的技术,例如来自 DAPO 的 Clip-Higher 和 Token 级损失 (Token-level Loss),来自 VC-PPO 的价值预训练 (Value-Pretraining) 和解耦 GAE (Decoupled-GAE),来自 SIL 的自模仿学习 (self-imitation learning),以及来自 GRPO 的组采样 (Group-Sampling)。此外,我们通过消融研究进一步验证了这些技术的必要性。
VAPO 是一个有效的强化学习系统,它整合了这些改进。这些改进平稳地协同作用,产生的整体效果优于各独立部分的总和。我们使用 Qwen2.5-32B 预训练模型进行实验,确保在所有实验中均未引入 SFT 数据,以保持与相关工作(DAPO 和 DeepSeek-R1-Zero-Qwen-32B)的可比性。VAPO 的性能得分相较于原始 PPO 从 5 分提升至 60 分,超越了先前最先进的(SOTA)不依赖价值函数的方法 DAPO 10 分。更重要的是,VAPO 非常稳定 —— 我们在训练期间没有观察到任何崩溃,并且多次运行的结果高度一致。
预备知识
本节介绍了作为我们提出的算法基础的基本概念和符号表示。我们首先探讨了将语言生成表示为强化学习任务的基本框架。随后,我们介绍了近端策略优化(Proximal Policy Optimization)和广义优势估计(Generalized Advantage Estimation)。
将语言生成建模为 Token 级 MDP
强化学习旨在学习一个策略,以最大化智能体在与环境交互过程中获得的累积奖励。在本研究中,我们将语言生成任务置于马尔可夫决策过程(MDP)的框架内。令提示词表示为 $x$,对此提示词的响应表示为 $y$。$x$ 和 $y$ 都可以分解为 Token 序列。例如,提示词 $x$ 可以表示为 $x=(x_0,\dots,x_m)$,其中 Token 来自固定的离散词汇表 $\mathcal{A}$。 我们将 Token 级 MDP 定义为元组 $\mathcal{M}=(\mathcal{S},\mathcal{A},\mathbb{P},R,d_0,\omega)$。各组成部分的详细说明如下:
- 状态空间 ($\mathcal{S}$):此空间包含截至给定时间步已生成的所有 Token 所形成的所有可能状态。在时间步 $t$,状态 $s_t$ 定义为 $s_t=(x_0,\dots,x_m,y_0,\dots,y_t)$。
- 动作空间 ($\mathcal{A}$):它对应于固定的离散词汇表,在生成过程中从中选择 Token。
- 动态 ($\mathbb{P}$):动态 ($\mathbb{P}$) 代表了 Token 之间的确定性转移模型。给定状态 $s_t=(x_0,\dots,x_m,y_0,\dots,y_t)$、动作 $a = y_{t + 1}$ 以及后续状态 $s_{t+1}=(x_0,\dots,x_m,y_0,\dots,y_t,y_{t+1})$,其转移概率为 $\mathbb{P}(s_{t+1}|s_t,a)=1$。
- 终止条件:当执行终止动作 $\omega$(通常是句子结束 Token)时,语言生成过程即告结束。
- 奖励函数 ($R(s,a)$):该函数提供标量反馈,用以评估 AI 智能体在状态 $s$ 下采取动作 $a$ 后的性能。在来自人类反馈的强化学习 (RLHF) 的背景下,奖励函数可以从人类偏好中学习得到,或者由特定于任务的一组规则来定义。
- 初始状态分布 ($d_0$):这是一个关于提示词 $x$ 的概率分布。初始状态 $s_0$ 包含提示词 $x$ 内的 Token。
RLHF 学习目标
我们将优化问题表述为一个 KL 正则化的强化学习任务。我们的目标是逼近最优的 KL 正则化策略,该策略由以下公式给出:
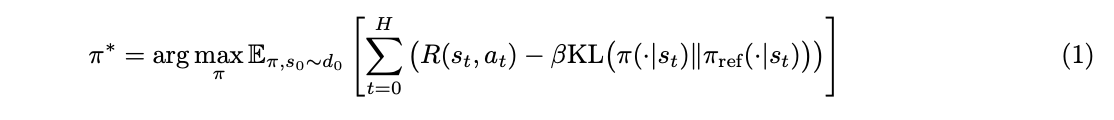
在此等式中,$H$ 代表决策步骤的总数,$s_0$ 是从数据集中抽样得到的提示词,$R(s_t, a_t)$ 是从奖励函数获得的 token 级别的奖励,$\beta$ 是一个控制 KL 正则化强度的系数,而 $\pi_{\text{ref}}$ 是初始化策略。
在传统的 RLHF 和大多数与大语言模型相关的任务中,奖励是稀疏的,并且仅在终止动作 $\omega$ 时分配,即句子结束 token <eos>。
近端策略优化
PPO 使用一个裁剪的替代目标函数 (clipped surrogate objective) 来更新策略。其关键思想是限制每次更新步骤中策略的变化幅度,以防止过大的策略更新导致不稳定。令 $\pi_{\theta}(a|s)$ 为由参数 $\theta$ 定义的策略,$\pi_{\theta_{\text{old}}}(a|s)$ 为来自上一次迭代的旧策略。PPO 的替代目标函数定义为:
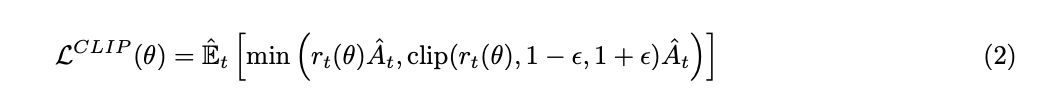
其中 $r_t(\theta)=\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)}$ 是概率比 (probability ratio),$\hat{A}_t$ 是在时间步 $t$ 估计的优势函数值 (estimated advantage),$\epsilon$ 是一个控制裁剪范围的超参数。
$$ \hat{A}_t=\sum_{l = 0}^{T-t-1}(\gamma\lambda)^l\delta_{t + l} $$其中 $\gamma$ 是折扣因子,$\lambda\in[0, 1]$ 是 GAE 参数,而 $\delta_t=R(s_t, a_t)+\gamma V(s_{t + 1})-V(s_t)$ 是时序差分 (TD) 误差。这里,$R(s_t, a_t)$ 是时间步 $t$ 的奖励,而 $V(s)$ 是价值函数。由于在 RLHF 中通常使用折扣因子 $\gamma = 1.0$,为了简化本文后续章节的表示,我们省略了 $\gamma$。
长 CoT RL 在推理任务中的挑战
长 CoT 任务给 RL 训练带来了独特的挑战,特别是对于那些使用价值模型来减少方差的方法。在本节中,我们系统地分析了由序列长度动态变化、价值函数不稳定性和奖励稀疏性引起的技术问题。
长序列上的价值模型偏差
正如 VC-PPO 中所指出的,使用奖励模型初始化价值模型会引入显著的初始化偏差。这种正偏差源于两种模型之间的目标不匹配。奖励模型被训练用于对 <EOS> Token 进行评分,这激励它因上下文不完整而给较早的 Token 分配较低的分数。相比之下,价值模型则估计在给定策略下,所有先于 <EOS> 的 Token 的预期累积奖励。在早期训练阶段,鉴于 GAE 的反向计算方式,在每个时间步 $t$ 都会存在一个正偏差,并且该偏差会沿着轨迹累积。
另一个使用 $\lambda=0.95$ 的 GAE 的标准做法可能会加剧这个问题。终止 Token 处的奖励信号 $R(s_T, \text{
训练过程中的异构序列长度
在复杂的推理任务中,长的 CoT 对于得出正确答案至关重要,模型生成的响应长度通常变化很大。这种可变性要求算法足够鲁棒,能够管理从非常短到非常长的序列。因此,常用的具有固定 $\lambda$ 参数的 GAE 方法遇到了显著的挑战。
即使价值模型是完美的,静态的 $\lambda$ 也可能无法有效适应不同长度的序列。对于短长度的响应,通过 GAE 获得的估计往往具有高方差。这是因为 GAE 代表了偏差和方差之间的权衡。在短响应的情况下,估计偏向于方差主导的一侧。另一方面,对于长长度的响应,由于自举,GAE 通常导致高偏差。GAE 的递归性质依赖于未来状态值,在长序列上会累积误差,从而加剧了偏差问题。这些局限性深深植根于 GAE 计算框架的指数衰减特性。
基于验证器的任务中奖励信号的稀疏性
复杂的推理任务经常部署验证器作为奖励模型。与提供密集信号(例如,范围从-4到4的连续值)的传统基于语言模型的奖励模型不同,基于验证器的奖励模型通常提供二元反馈(例如,0和1)。奖励信号的稀疏性因长思维链(CoT)推理而进一步加剧。由于CoT显著增加了输出长度,它不仅增加了计算时间,而且降低了接收非零奖励的频率。在策略优化中,采样到的包含正确答案的响应可能极其稀缺和宝贵。
这种情况带来了一个独特的探索-利用困境。一方面,模型必须保持相对较高的不确定性。这使其能够采样多样化的响应,从而增加针对给定提示词生成正确答案的可能性。另一方面,算法需要有效利用通过艰苦探索获得的、包含正确答案的采样响应,以提高学习效率。如果未能在这两者之间取得适当的平衡,模型可能会因过度利用而陷入次优解,或者因无效探索而浪费计算资源。
减轻长序列上的价值模型偏差
基于对基于价值模型的分析,我们提议使用价值预训练(Value-Pretraining)和解耦 GAE(decoupled-GAE)来应对长序列中价值模型偏差的关键挑战。这两种技术均借鉴了先前在 VC-PPO 中引入的方法。价值预训练旨在减轻价值初始化偏差。将 PPO 朴素地应用于长 CoT(思维链)任务会导致诸如输出长度坍缩和性能下降等失败。其原因是价值模型由奖励模型初始化,但奖励模型的目标与价值模型的目标不匹配。这一现象最早在 VC-PPO 中被识别并得到解决。在本文中,我们沿用价值预训练技术,具体步骤概述如下:
- 通过从一个固定策略(例如 $\pi_{\text{sft}}$)采样来持续生成响应,并使用蒙特卡洛(Monte-Carlo)回报更新价值模型。
- 训练价值模型,直至关键训练指标,包括价值损失(value loss)和可解释方差(explained variance),达到足够低的值。
- 保存价值检查点 (value checkpoint),并在后续实验中加载此检查点。解耦 GAE (Decoupled-GAE) 在 VC-PPO 中被证明是有效的。该技术将价值 (value) 和策略 (policy) 的优势计算 (advantage computation) 进行了解耦。对于价值更新,建议使用 $\lambda = 1.0$ 来计算价值更新目标 (value-update target)。这种选择可以实现无偏的梯度下降优化,有效解决了长 CoT 任务中的奖励衰减 (reward-decay) 问题。
然而,对于策略更新,建议使用较小的 $\lambda$ 以在计算和时间约束下加速策略收敛 (policy convergence)。在 VC-PPO 中,这是通过在优势计算中使用不同的系数来实现的:$\lambda_{\text{critic}} = 1.0$ 和 $\lambda_{\text{policy}} = 0.95$。在本文中,我们采用了 GAE 计算解耦的核心思想。
管理训练过程中的异构序列长度
为应对训练过程中序列长度异构的挑战,我们提出了长度自适应 GAE (Length-Adaptive GAE)。此方法根据序列长度动态调整 GAE 中的参数,从而能够对不同长度的序列进行自适应的优势估计。此外,为提升混合长度序列训练的稳定性,我们将传统的样本级策略梯度损失替换为 Token 级策略梯度损失。关键技术细节阐述如下:
长度自适应 GAE 是为解决不同长度序列间最优 $\lambda_{\text{policy}}$ 值不一致的问题而专门提出的。在 VC-PPO 中,$\lambda_{\text{policy}}$ 被设为一个常量值 $\lambda_{\text{policy}}=0.95$。然而,在考虑 GAE 计算时,对于长度 $l>100$ 的较长输出序列,与奖励相对应的 TD 误差的系数为 $0.95^{100}\approx0.006$,这几乎为零。因此,当 $\lambda_{\text{policy}}$ 固定为 $0.95$ 时,GAE 的计算会变得由可能带有偏差的自举 (bootstrapping) TD 误差所主导。这种方法对于处理极长的输出序列而言,可能并非最优。
$$ \sum_{t = 0}^{\infty}\lambda_{\text{policy}}^t\approx\frac{1}{1-\lambda_{\text{policy}}}=\alpha l, \label{eq:variable_lam} $$$$ \lambda_{\text{policy}} = 1-\frac{1}{\alpha l} $$这种在 GAE 计算中对 $\lambda_{\text{policy}}$ 采用长度自适应的方法,可以更有效地处理不同长度的序列。
Token 级策略梯度损失 (Token-Level Policy Gradient Loss)。遵循 DAPO 的方法,我们也修改了策略梯度损失的计算方式,以调整在长思维链(COT)场景下的损失权重分配。具体来说,在之前的实现中,策略梯度损失按如下方式计算:
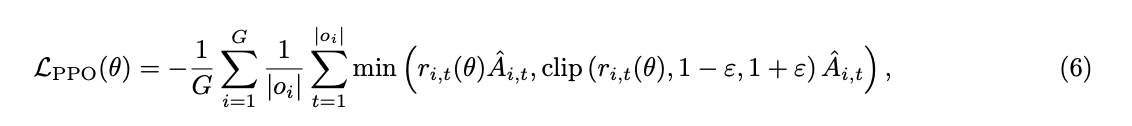
其中 $G$ 是训练批次的大小,$o_i$ 是第 $i$ 个样本的轨迹。在这种损失函数表述中,所有 Token 的损失首先在序列级别进行平均,然后进一步在批次级别进行平均。这种方法导致来自较长序列的 Token 对最终损失值的贡献较小。因此,如果模型在处理长序列时遇到关键问题——这种情况在强化学习(RL)训练的探索阶段很可能发生——那么由于这些长序列 Token 的权重降低而导致的抑制不足,可能会引发训练不稳定甚至崩溃。为了解决这种 Token 对最终损失贡献的不平衡问题,我们将损失函数修正为以下形式:
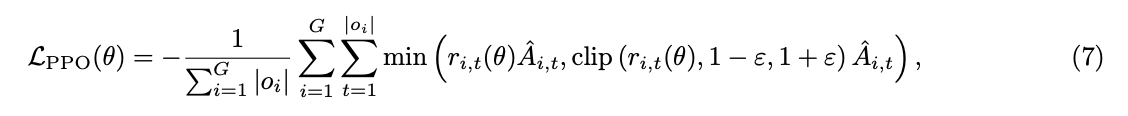
在此形式中,单个训练批次内的所有 Token 都被赋予统一的权重,从而能够更有效地解决长序列带来的问题。
处理基于验证器的任务中的奖励信号稀疏性问题
在奖励信号高度稀疏的场景下,提升强化学习(RL)训练中探索-利用权衡(exploration-exploitation tradeoff)的效率变得极具挑战性。为解决这一关键问题,我们采用了三种方法:Clip-Higher、正例语言模型损失(Positive Example LM Loss)和分组采样(Group-Sampling)。技术细节阐述如下: Clip-Higher 方法用于缓解在 PPO 和 GRPO 训练过程中遇到的熵坍塌(entropy collapse)问题,该方法最早由 DAPO 提出。我们将下界裁剪范围 $\varepsilon_\text{low}$ 和上界裁剪范围 $\varepsilon_\text{high}$ 进行解耦:
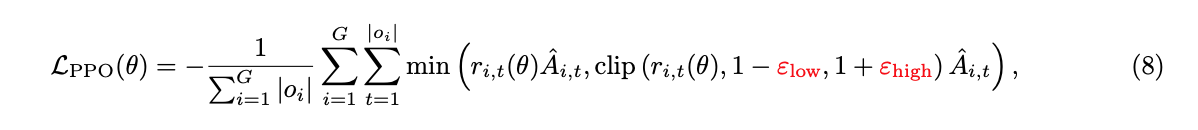
我们增大 $\varepsilon_\text{high}$ 的值,以便为低概率 Token 的概率提升留出更多空间。我们选择保持 $\varepsilon_\text{low}$ 相对较小,因为增大该值会将这些 Token 的概率抑制趋近于 0,从而导致采样空间(sampling space)的坍塌。
$$ \begin{aligned} \mathcal{L}_{\text{NLL}}(\theta) =- \frac{1}{\sum_{o_i \in \mathcal{T}}|o_i|} \sum_{o_i \in \mathcal{T}} \sum_{t = 1}^{|o_i|} \log\pi_{\theta}\left(a_t|s_t\right), \end{aligned} $$$$ \begin{aligned} \mathcal{L}(\theta) = \mathcal{L}_{\text{PPO}}(\theta) + \mu * \mathcal{L}_{\text{NLL}}(\theta). \end{aligned} $$组采样(Group-Sampling) 用于在同一个提示词内采样区分性的正样本和负样本。在给定的固定计算预算下,存在两种分配计算资源的主要方法。第一种方法是尽可能多地使用提示词,每个提示词只采样一次。第二种方法是减少每批次中不同提示词的数量,并将计算资源转向重复生成。我们观察到后一种方法性能略有提升,这归因于它引入了更丰富的对比信号,从而增强了策略模型的学习能力。
训练细节
在这项工作中,我们基于 Qwen-32B 模型,通过对 PPO 算法引入各种修改,增强了模型的数学性能。这些技术对于其他推理任务,例如代码相关任务,也是有效的。对于基本的 PPO,我们使用 AdamW 作为优化器,将 actor 学习率设置为 $1 \times 10^{-6}$,critic 学习率设置为 $2 \times 10^{-6}$,因为 critic 需要更快地更新以跟上策略的变化。学习率采用了 warmup-constant 调度器。批处理大小为 8192 个提示,每个提示采样一次,每个小批量大小设置为 512。价值网络使用奖励模型进行初始化,GAE $\lambda$ 设置为 0.95,$\gamma$ 设置为 1.0。使用了样本级损失,并且裁剪 $\epsilon$ 设置为 0.2。与标准 PPO 相比,VAPO 进行了以下参数调整:
- 在启动策略训练之前,基于奖励模型(RM)对价值网络进行了 50 步的预热。
- 使用了解耦 GAE,其中价值网络从使用 $\lambda$=1.0 估计的回报中学习,而策略网络则从使用单独 lambda 获得的优势中学习。
- 根据序列长度自适应地设置优势估计的 lambda,遵循公式:$\lambda_{\text{policy}} = 1-\frac{1}{\alpha l}$,其中 $\alpha=0.05$。
- 将裁剪范围调整为 $\epsilon_\text{high}$=0.28 和 $\epsilon_\text{low}$=0.2。
- 采用了 Token 级别的策略梯度损失。
- 在策略梯度损失中添加了权重为 0.1 的正例语言模型(LM)损失。
- 每次采样使用 512 个提示词,每个提示词采样 16 次,并将小批量大小设置为 512。 我们还将分别展示从 VAPO 中单独移除这七项修改中每一项的最终效果。对于评估指标,我们使用 AIME24 在 32 次测试中的平均通过率,采样参数设置为 topp=0.7 和 temperature=1.0。
消融研究结果
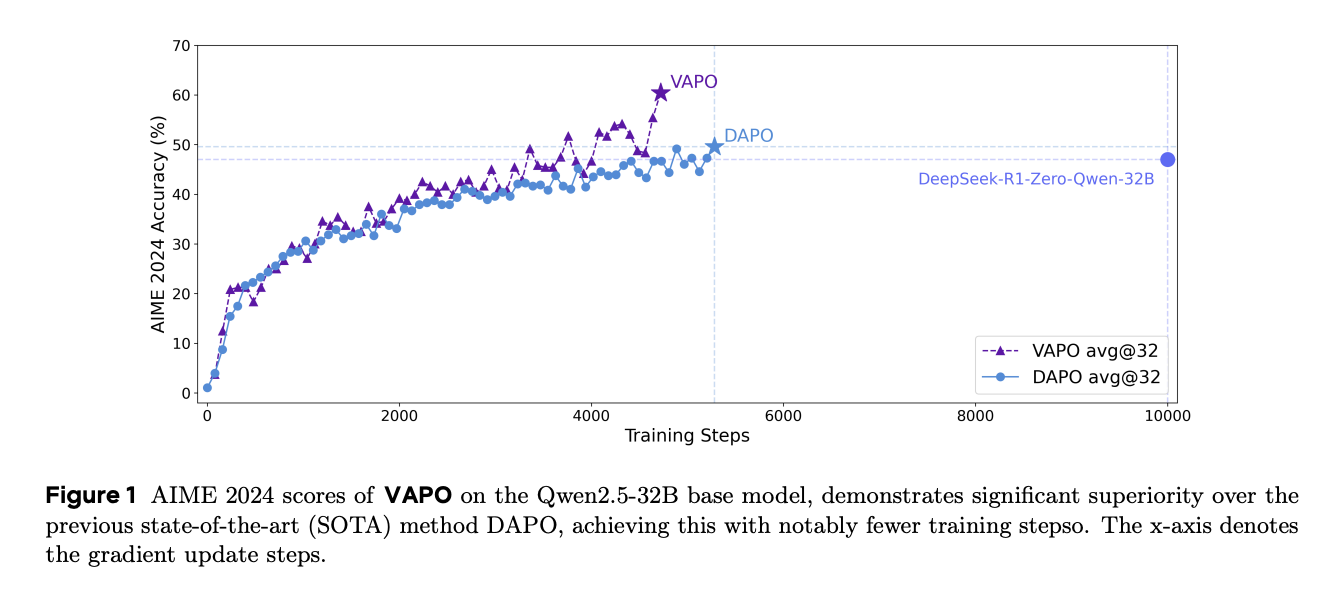
在 Qwen-32b 上,使用 GRPO 的 DeepSeek R1 在 AIME24 上获得 47 分,而 DAPO 使用 50% 的更新步数达到了 50 分。在图1中,我们提出的 VAPO 仅用 DAPO 60% 的步数就达到了同等性能,并且仅在 5000 步内就取得了 60.4 分的当前最佳分数,展示了 VAPO 的效率。此外,VAPO 保持了稳定的熵——既不崩溃也不过高——并且在三次重复实验中始终获得 60-61 的峰值分数,突显了我们算法的可靠性。
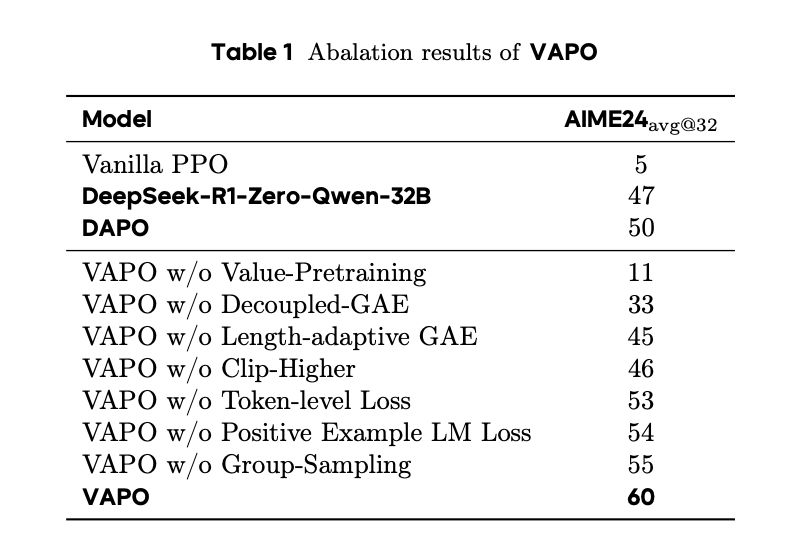
表1系统地展示了我们的实验结果。标准 PPO 方法因受到价值模型学习崩溃的阻碍,在训练后期仅能达到 5 分,其特征表现为响应长度急剧缩短,且模型不经推理直接回答问题。我们的 VAPO 方法最终达到了 60 分,这是一个显著的提升。我们通过逐一移除七项提出的修改(消融实验),进一步验证了它们的有效性:
- 若无价值预训练,模型在训练期间会经历与标准 PPO 相同的崩溃,最高收敛到约 11 分。
- 移除解耦 GAE 会导致奖励信号在反向传播过程中指数级衰减,阻止模型对长格式响应进行充分优化,并导致 27 分的性能下降。
- 自适应 GAE 平衡了短响应和长响应的优化,带来了 15 分的改进。
- 提高裁剪上限 (Clip higher) 鼓励进行充分的探索和利用;移除该项会将模型的最高收敛分数限制在 46 分。
- Token 级别损失隐式地增加了长响应的权重,贡献了 7 分的提升。
- 引入正样本语言模型损失使模型性能提升了近 6 分。
- 使用分组采样生成较少但重复次数更多的提示词,也带来了 5 分的改进。
训练动态

VAPO 的训练曲线比 DAPO 更平滑,表明 VAPO 的算法优化过程更为稳定。
VAPO 展现出优于 DAPO 的长度扩展性。在当前背景下,更好的长度扩展性被广泛认为是模型性能改进的标志,因为它能增强模型的泛化能力。