
1. 要点
三大模型概览:Llama 4 Scout(小型)、Llama 4 Maverick(中型)、Llama 4 Behemoth(大型),Behemoth还在训练,其余模型都是Behemoth蒸馏而来。
技术参数对比:
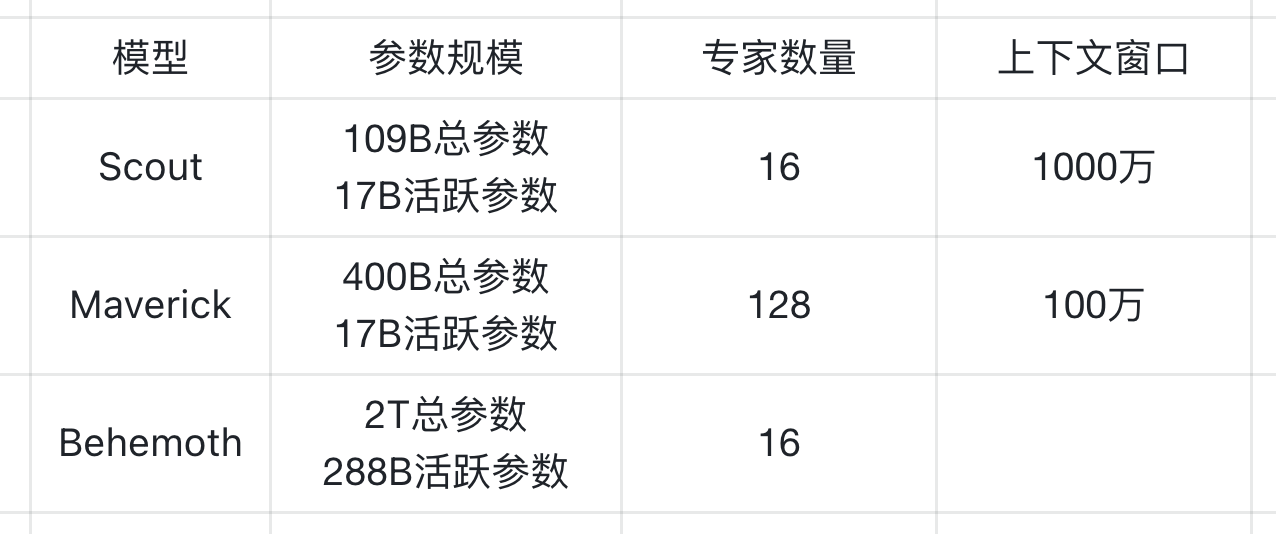
性能优势:多模态能力、Maverick在LMArena 1714分,Behemoth 声称击败所有模型
部署效率:单GPU适配
2. 预训练
- MoE架构原理:参数激活机制、计算效率提升
- 多模态融合:早期融合技术、文本与视觉token集成
- 视觉增强:改进的MetaCLIP视觉编码器
- 训练创新:MetaP超参数设置、FP8精度训练
- 数据规模:30万亿Token、200种语言支持
- 上下文扩展:中期训练阶段、1000万Token长度
3.后训练
- 多模态挑战:不同输入模态平衡
- 优化流程:轻量级SFT → 在线RL → 轻量级DPO
- 数据策略:模型评判器过滤、难度筛选
- 迭代方法:连续在线强化学习、自适应过滤
- 效果验证:智能与对话能力平衡
4.模型特性与能力
- Maverick特点:大规模专家(128)、跨语言应用、创意写作
- Scout创新:iRoPE架构、交错注意力层、无位置嵌入
- 长上下文技术:推理时温度缩放、旋转位置嵌入
- 视觉理解:多图像处理(最多48张)、时间相关活动理解
- 图像定位:精确视觉问答、对象定位能力
5. 2T Behemoth模型
- 规模与定位:288B活跃参数、2T总参数、教师模型角色
- 蒸馏技术:共同蒸馏、动态加权损失函数
- 训练挑战:95%数据裁剪、大规模强化学习
- 提示词策略:难度递增计划、零优势动态过滤
- 基础设施创新:异步在线RL框架、灵活GPU分配
- 效率提升:训练速度10倍提升、资源平衡
以下为原文:包含更多细节
预训练
构建下一代 Llama 模型要求我们在预训练期间采取几种新方法。
我们新的 Llama 4 模型是我们首批使用混合专家(MoE)架构的模型。在 MoE 模型中,单个 Token 仅激活总参数中的一小部分。MoE 架构在训练和推理方面计算效率更高,并且在给定的固定训练 FLOPs 预算下,与密集模型相比,能够提供更高的质量。 
例如,Llama 4 Maverick 模型包含 17B (170亿) 活跃参数和 400B (4000亿) 总参数。我们交替使用密集层和混合专家 (MoE) 层以提升推理效率。MoE 层使用了 128 个路由专家和一个共享专家。每个 token 会被发送到共享专家,同时也会发送到 128 个路由专家中的一个。因此,尽管所有参数都存储在内存中,但在运行这些模型进行服务时,只有总参数的一个子集会被激活。这通过降低模型服务成本和延迟来提高推理效率——Llama 4 Maverick 既可以在单台 NVIDIA H100 DGX 主机上运行以便于部署,也可以通过分布式推理实现最高效率。 Llama 4 模型采用原生多模态设计,并结合了早期融合技术,将文本和视觉 token 无缝集成到统一的模型骨干网络中。早期融合是一项重大进步,因为它使我们能够利用大量未标记的文本、图像和视频数据对模型进行联合预训练。我们还改进了 Llama 4 中的视觉编码器。该编码器基于 MetaCLIP,但与一个冻结的 Llama 模型协同进行了单独训练,旨在使编码器能更好地适配大语言模型 (LLM)。
我们开发了一种新的训练技术,我们称之为 MetaP,它使我们能够可靠地设置关键的模型超参数,例如每层学习率和初始化尺度。我们发现,所选的超参数在不同的批次大小、模型宽度、深度和训练 Token 数量下都能很好地迁移。Llama 4 通过在 200 种语言上进行预训练,支持开源微调工作,其中包括超过 100 种语言各有超过 10 亿个 Token,并且多语言 Token 总量是 Llama 3 的 10 倍。此外,我们通过使用 FP8 精度来专注于高效的模型训练,在不牺牲质量的同时确保高模型 FLOPs 利用率——在使用 FP8 和 32K GPU 预训练我们的 Llama 4 Behemoth 模型时,我们实现了 390 TFLOPs/GPU。用于训练的整体数据组合包含超过 30 万亿个 Token,是 Llama 3 预训练数据组合的两倍多,并包括多样化的文本、图像和视频数据集。
我们继续在一个我们称之为“中期训练”的阶段训练模型,通过新的训练方案(包括使用专门数据集进行长上下文扩展)来提高核心能力。这使我们能够提高模型质量,同时也为 Llama 4 Scout 解锁了同类最佳的 1000 万输入上下文长度。对我们的新模型进行后训练
我们最新的模型提供了更小和更大的选项,以满足广泛的应用场景和开发者需求。Llama 4 Maverick 在图像和文本理解方面展现了无与伦比、行业领先的性能,使其能够创建可跨越语言障碍的复杂人工智能应用。作为我们面向通用助手和聊天场景的主力产品模型,Llama 4 Maverick 非常擅长精确的图像理解和创意写作。
在对 Llama 4 Maverick 模型进行后训练时,最大的挑战是在多种输入模态、推理能力和对话能力之间保持平衡。为了混合不同模态,我们提出了一种精心策划的课程策略,与单一模态专家模型相比,该策略不会牺牲性能。对于 Llama 4,我们通过采用不同的方法改进了我们的后训练流程:轻量级监督微调 (SFT) > 在线强化学习 (RL) > 轻量级直接偏好优化 (DPO)。我们学到的关键一点是,SFT 和 DPO 可能会过度约束模型,限制在线强化学习 (RL) 阶段的探索,并导致准确率次优,尤其是在推理、编码和数学领域。为了解决这个问题,我们使用 Llama 模型作为评判器,移除了超过 50% 被标记为简单的数据,并对其余更难的数据集进行了轻量级 SFT。在随后的多模态在线强化学习 (RL) 阶段,通过仔细选择更难的提示词,我们得以实现性能的阶跃式提升。此外,我们实施了一种连续在线强化学习 (RL) 策略,即在训练模型和使用模型之间交替进行,以持续筛选和仅保留中等到困难难度的提示词。事实证明,该策略在计算和准确率权衡方面非常有益。然后,我们进行了轻量级 DPO 来处理与模型响应质量相关的边界情况,有效地在模型的智能和对话能力之间取得了良好的平衡。流程架构和带有自适应数据过滤的连续在线强化学习 (RL) 策略最终打造出一个行业领先的、具有最先进智能和图像理解能力的通用聊天模型。
作为一个通用大语言模型,Llama 4 Maverick 包含 170 亿活跃参数、128 个专家和 4000 亿总参数,与 Llama 3.3 70B 相比,以更低的价格提供高质量。Llama 4 Maverick 是同类最佳的多模态模型,在编码、推理、多语言、长上下文和图像基准测试方面超越了 GPT-4o 和 Gemini 2.0 等同类模型,并且在编码和推理方面可与规模大得多的 DeepSeek v3.1 媲美。 我们较小的模型 Llama 4 Scout 是一款通用模型,拥有 170 亿活跃参数、16 个专家和 1090 亿总参数,在其同类模型中展现了顶尖性能。Llama 4 Scout 将支持的上下文长度从 Llama 3 的 128K 大幅增加到行业领先的 1000 万 Token。这开启了无限可能,包括多文档摘要、解析海量用户活动以执行个性化任务,以及对庞大的代码库进行推理。
Llama 4 Scout 的预训练和后训练均采用了 256K 的上下文长度,这赋予了基础模型先进的长度泛化能力。我们在诸如文本“大海捞针”式检索以及超过 1000 万代码 Token 的累积负对数似然(NLLs)等任务中展示了令人信服的结果。Llama 4 架构的一项关键创新是使用了不含位置嵌入的交错注意力层。此外,我们采用了注意力的推理时温度缩放来增强长度泛化能力。我们称此为 iRoPE 架构,其中“i”代表“交错”(interleaved)注意力层,突显了支持“无限”上下文长度的长期目标,而“RoPE”则指代大多数层级中采用的旋转位置嵌入。
我们训练了我们的两个模型,使用了各种各样的图像和视频静帧,使其具备广泛的视觉理解能力,包括理解时间相关的活动和相关图像。这使得模型能够轻松地处理多图像输入,并结合文本提示词来执行视觉推理和理解任务。这些模型在预训练阶段最多使用了48张图像进行训练,并且我们在训练后测试中发现,使用多达八张图像也能取得良好效果。
Llama 4 Scout 在图像定位方面也是同类最佳的,能够将用户提示词与相关的视觉概念对齐,并将模型响应锚定到图像中的区域。这使得大语言模型能够进行更精确的视觉问答,以更好地理解用户意图并定位感兴趣的对象。Llama 4 Scout 在编码、推理、长上下文和图像基准测试方面也超越了同类模型,并且比所有之前的 Llama 模型表现出更强的性能。 
将 Llama 推向新规模:2T Behemoth
我们很高兴分享 Llama 4 Behemoth 的预览版,这是一个教师模型,在其同类模型中展现出先进的智能。Llama 4 Behemoth 也是一个多模态混合专家模型,拥有 2880 亿活跃参数、16 个专家以及近两万亿的总参数。该模型在数学、多语言能力和图像基准测试方面为非推理模型提供了最先进的性能,因此是教授较小的 Llama 4 模型的理想选择。我们以 Llama 4 Behemoth 作为教师模型,对 Llama 4 Maverick 模型进行了共同蒸馏,从而在各项最终任务评估指标上实现了显著的质量提升。我们开发了一种新颖的蒸馏损失函数,该函数在训练过程中动态地对软目标和硬目标进行加权。在预训练阶段,通过 Llama 4 Behemoth 进行共同蒸馏,可以分摊计算蒸馏目标所需的资源密集型前向传播的计算成本;这些蒸馏目标是针对学生模型训练所用的大部分训练数据计算的。对于学生模型训练中新增的额外数据,我们在 Behemoth 模型上运行了前向传播以创建蒸馏目标。
对一个拥有两万亿参数的模型进行后训练同样是一项重大挑战,这要求我们从数据规模入手,全面地审视并改进我们的训练方案。为了最大化性能,我们不得不裁剪掉 95% 的 SFT (监督微调) 数据——相比之下,较小模型仅为 50%——以实现对质量和效率的必要聚焦。我们还发现,先进行轻量级的 SFT,随后进行大规模强化学习(RL),能更显著地提升模型的推理和编码能力。我们的强化学习方案侧重于通过策略模型进行 pass@k 分析来抽样困难的提示词,并精心设计一个提示词难度递增的训练计划。我们同时发现,在训练过程中动态滤除零优势 (zero advantage) 的提示词,以及构建包含来自多种能力的混合提示词的训练批次,这两点对于提升模型在数学、推理和编码方面的表现起到了关键作用。最后,从多样化的系统指令中进行抽样,对于确保模型在推理和编码任务中保持其指令遵循能力,并在各种任务上表现出色至关重要。
为拥有两万亿参数的模型扩展强化学习(RL)应用,也要求我们彻底改造底层的强化学习基础设施,因其达到了前所未有的规模。我们优化了 MoE 并行化设计以提高速度,从而实现了更快的迭代。我们开发了一个完全异步的在线强化学习训练框架,增强了灵活性。相较于现有的分布式训练框架(该框架为了将所有模型堆叠在内存中而牺牲了计算内存),我们的新基础设施能够将不同的模型灵活地分配到独立的 GPU 上,并根据计算速度平衡各模型间的资源。这项创新使训练效率相较于前几代提升了约 10 倍。