

SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
摘要
DeepSeek-R1 已经表明,通过一个简单的强化学习(RL)框架,结合基于规则的奖励,长链式思考(CoT)推理可以自然地涌现。在这种框架下,训练可以直接从基础模型开始——这种范式被称 zero RL training。 近期,许多尝试复现零 RL 训练的工作主要集中在 Qwen2.5 模型系列上,但这可能不具有代表性,因为我们发现这些基础模型已经展现出强大的指令遵循和自我反思能力。 在这项工作中,我们研究了 10 个不同的基础模型上的零 RL 训练,这些模型涵盖了不同的系列和规模,包括 LLama3-8B、Mistral-7B/24B、DeepSeek-Math-7B、Qwen2.5-math-7B 以及所有 Qwen2.5 模型(从 0.5B 到 32B)。 通过利用几个关键的设计策略——例如调整格式奖励和控制查询难度——我们在大多数设置中都实现了推理准确性和响应长度的显著提高。 然而,通过仔细监控训练动态,我们观察到不同的基础模型在训练过程中表现出不同的模式。 例如,响应长度的增加并不总是与某些认知行为的出现相关,例如验证(即“顿悟时刻”)。 值得注意的是,我们首次在非 Qwen 系列的小模型中观察到“顿悟时刻”。 我们分享了实现成功零 RL 训练的关键设计,以及我们的发现和实践。 为了促进进一步的研究,我们开源了代码、模型和分析工具。
介绍
回应长度的增加并不总是意味着“顿悟时刻”——有趣的是,对于构成当前大多数开源项目基础的 Qwen2.5 模型,尽管回应长度有所增加,我们并未观察到诸如自我反思等认知行为的频率有所上升。
我们首次观察到,在 Qwen 系列之外的小型模型中,尤其是在 Llama3-8B 和 DeepSeek-Math-7B 模型中,特定认知推理行为(例如验证)的频率显著增加。
强制执行严格的格式奖励(例如,将答案置于特定格式的框内)会显著抑制模型的探索能力,特别是对于那些最初难以遵循指令的基础模型。这种限制会降低它们的性能上限,并常常导致过度思考的行为。
训练数据的难度级别必须与基础模型的内在探索能力紧密对齐,否则零样本强化学习 (zero RL) 将会失败。
与 @shao2024deepseekmath 中的观察结果相反,零样本强化学习 (zero RL) 训练将 pass@k 准确率提高了 10-30 个绝对百分点,这是一个强有力的证据,证实零样本强化学习 (zero RL) 训练不仅仅是重新排序响应。
我们重新审视了传统的训练流程,该流程执行监督微调 (SFT) 以学习在强化学习 (RL) 训练之前遵循指令。具体来说,我们使用传统的监督微调 (SFT) 数据集作为强化学习 (RL) 的冷启动——这是在 DeepSeek-R1 发布之前的事实上的方法。虽然高质量的思维链 (CoT) 数据可以通过模仿迅速提高基础模型的性能,但我们发现它显着限制了模型在强化学习 (RL) 期间自由探索的能力。这种约束降低了后强化学习 (RL) 性能,并抑制了高级推理能力的出现。
零样本强化学习训练中涌现的推理能力
目前关于零样本强化学习训练的研究主要集中在 Qwen2.5 系列模型上,并且只追踪诸如准确率和响应长度等表面指标。首先,虽然 Qwen2.5 模型表现出强大的性能,但它们可能并不代表在实际环境中常见的基座模型。这是因为 Qwen2.5 模型在预训练期间整合了大量的合成数据,并且已经表现出强大的指令遵循能力和某些反思行为,正如我们在初步试验中观察到的那样。其次,响应长度的增加可能由多种因素导致,并不一定意味着“顿悟时刻”,即诸如自我反思等特定认知行为的出现。例如,我们观察到响应长度的增加有时可能是不健康的,源于毫无意义的重复。为了弥补这些差距,本节研究了跨越多个系列和规模的各种基座模型的零样本强化学习训练。通过仔细监控除准确率和响应长度之外的各种指标的训练动态,我们的目标是为实际环境中开放的基座模型的零样本强化学习训练提供更全面和透明的理解。
背景:“zero RL 训练”
在我们的研究中,我们遵循 @guo2025deepseek 中提出的零 RL 训练方法,使用各种开放的基础模型,并采用 GRPO 算法。GRPO 通过消除对单独价值模型的需求来优化计算效率;相反,它直接利用组归一化奖励来估计优势。对于一个查询 $q$ 和一组从旧策略模型 $\pi_{\text{old}}$ 采样的响应 $O = \{o_1, o_2, \dots, o_G\}$,我们采用 token 级别、长度修正的 GRPO 目标来优化策略模型 $\pi$:

数据集:
为了保持训练配方的简洁性,我们仅从 GSM8K 和 MATH 数据集中选择训练数据。对于 MATH 数据集,按照之前的研究,我们保留 MATH500 子集作为测试集,均匀采样额外的 500 个问题用于验证,并将剩余的 4,000 个测试问题与原始的 7,500 个训练问题结合起来,形成我们的训练集。MATH 数据集中的每个例子最初都标有 1 到 5 的难度级别。在我们的实验中,我们发现数据难度对于成功的零样本学习至关重要,并且有必要使用与模型能力相符的数据。为了研究这种现象,我们将数据分为三个难度级别:简单(GSM8K 和 MATH lv.1)、中等(MATH lv.1–4)和困难(MATH lv.3–5),每个类别包含大约 8,000 个问题。对于我们的主要训练运行,我们对 LLama-3.1-8B、Mistral- v0.1-7B 和 DeepSeek-Math-7B 使用简单难度的数据;对 Qwen-2.5-0.5B 使用中等难度的数据;对 Mistral-Small-24B、Qwen-2.5-Math-7B 和 Qwen-2.5-1.5B/7B/14B/32B 使用困难难度的数据。
奖励:
我们使用基于规则的奖励函数,该函数仅根据生成的响应的正确性来分配奖励:正确的最终答案获得 +1 的奖励,而错误的答案获得 0 的奖励。最近的研究通常将基于格式的规则纳入奖励计算中,鼓励模型遵循特定的输出格式。然而,我们发现这种方法可能会阻碍模型的探索,并最终损害其性能,特别是对于在初始阶段难以遵循格式的基础模型。
模型:
我们对 Llama-3.1-8B、DeepSeek-Math-7B、Mistral-v0.1-7B、Mistral-Small-24b-Base-2501 和 Qwen-2.5 (0.5B、1.5B、7B、14B、32B) 进行了零资源强化学习训练实验。由于我们对各种模型进行了实验,在极其简单的设置下,使用小型、简单的数据集,并且仅使用正确性奖励,我们将获得的模型称为 SimpleRL-Zoo,以表示一个简单的训练配方,适用于各种开放基础模型。对于指令遵循能力较弱的模型(Llama-3.1-8B、Mistral-v0.1-7B 和 Qwen-2.5-0.5B/1.5B),我们采用更简单的提示词,仅需要逐步推理。对于指令遵循能力较强的模型,我们使用更复杂的提示词,要求将最终答案放在框中。在我们的初步实验中,我们观察到,对于指令遵循能力较弱的模型,使用复杂的提示词通常会导致在训练早期生成大量不相关或无意义的内容,从而导致不稳定。
基准测试:
我们在标准数学推理基准上评估性能,包括 GSM8K、MATH 500、Minerva Math 和 OlympiadBench,以及竞赛级别的基准,例如 AIME 2024 和 AMC 2023。
其他配置:
我们使用 verl 框架训练我们的模型。具体来说,在训练期间,我们使用 1024 的提示词批大小,为每个提示词生成 8 个 rollout,设置最大 rollout 长度为 8,192 个 Token,并使用 256 的 mini-batch 大小进行训练。值得注意的是,我们使用相同的训练超参数来训练所有模型。在评估期间,我们将采样温度设置为 1.0,并允许最大生成长度为 16,384 个 Token。对于大多数基准测试,我们报告 pass@1 结果。但是,对于 AIME 2024 基准测试,由于数据点有限,我们特别报告 pass@1 和对 32 个样本计算的平均准确率 (avg@32)。
评估指标
在训练过程中,我们会监控标准指标,例如在各个基准测试中的准确率和响应长度。然而,正如之前讨论过的,我们观察到响应长度作为一个指标相当肤浅,无法准确反映模型推理行为的变化。因此,我们额外采用了以下指标:
推理行为比例:
为了更好地理解模型在整个训练过程中的推理模式,我们采用了 @gandhi2025cognitive 提出的认知行为框架,并使用 GPT-4o 来识别与推理相关的行为,包括“回溯”、“验证”、“设定子目标”和“枚举”。我们报告包含这些认知行为的响应所占的比例。尽管最近的一些研究建议使用相关关键词作为监控信号来跟踪反思行为,但我们认为这些关键词与反思和验证等高级推理模式的相关性很弱。因此,它们无法充分捕捉这些推理过程的发展。
Clip Ratio:
在训练的早期阶段,基础模型表现出较弱的指令遵循能力,并且经常无法适当地停止,从而导致不相关或过长的输出。在训练崩溃后,模型也可能生成重复或过度扩展的响应。由于模型具有固定的最大上下文长度,因此在训练和评估期间可能会截断此类输出。为了监控这个问题,我们将截断输出的比例定义为“裁剪率”。
平均停止长度:
被截断的生成结果通常源于重复模式或不完整的推理等问题,这些问题通常无助于形成有效的轨迹。为了考虑这一因素,我们引入了一个新的指标,用于跟踪在正常情况下停止的响应的平均长度。这是一个更可靠的指标,因为它只考虑有效的响应,从而消除了未停止响应所造成的干扰。
Pass@k 准确率:
我们追踪 pass@k 准确率,它表示对于每个问题采样 k 个回答时,至少获得一个正确回答的问题的百分比。Pass@k 作为模型探索能力的指标,对于强化学习(RL)尤其重要,因为它反映了模型生成能够获得正向奖励的回答的能力。此前,一些研究人员认为,强化学习训练可能仅仅是重新排序原始模型分布中的回答,因为强化学习训练后 pass@k 准确率没有提高就证明了这一点。
主要结果
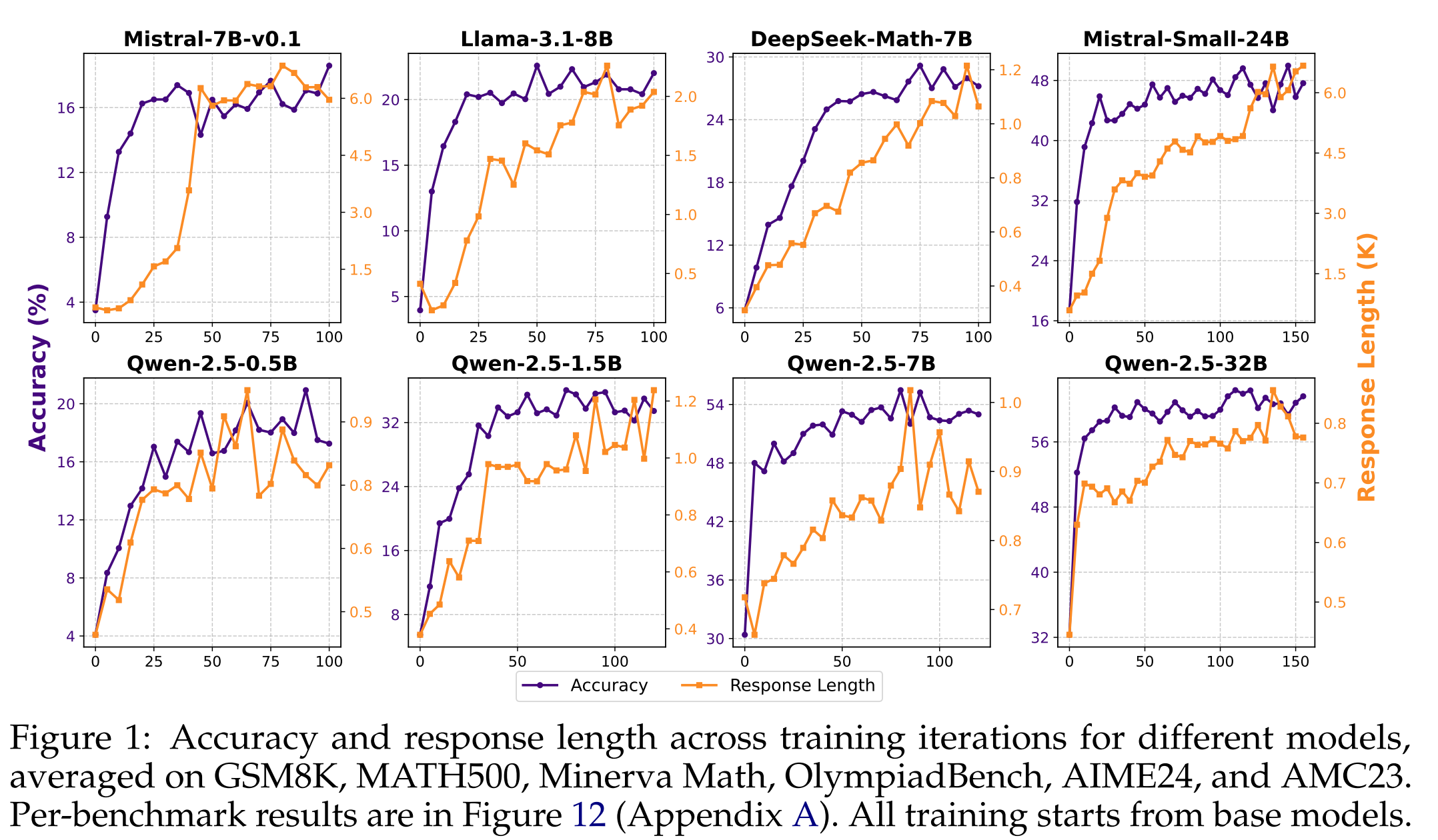
零样本强化学习训练显著提高准确率和回复长度:
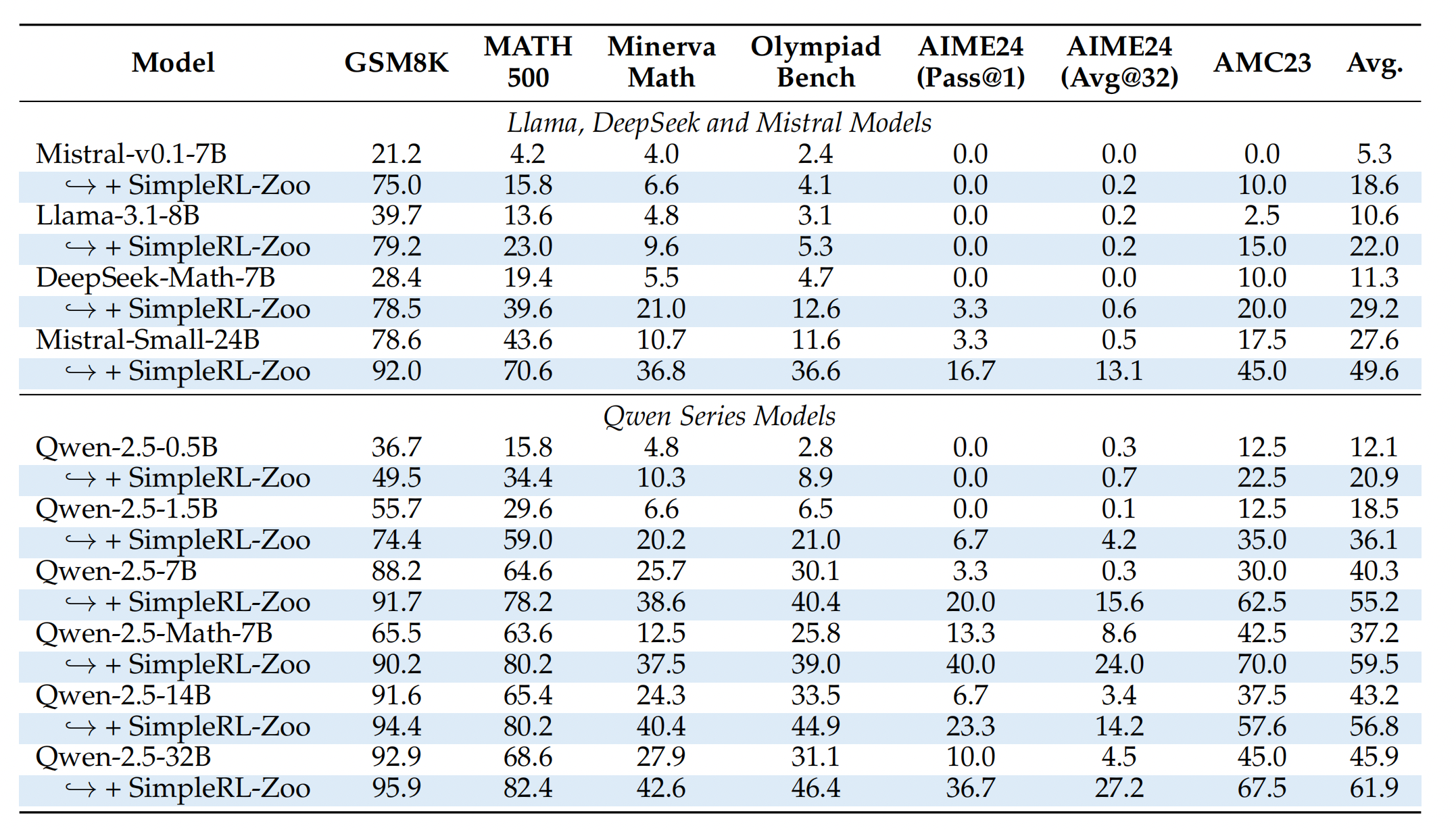
图 1 说明了在各种基准测试中,回复长度和平均准确率均呈现稳定提高的趋势。表1提供了详细的结果分析。 值得注意的是,即使仅使用 8K 训练数据,我们也能观察到所有基准测试的性能均有显著提升。 例如,Qwen-32b 在 AIME 24 上的 Pass@1 指标从 $10.0$ 飙升至 $36.7$,在 MATH 500 上,该指标从 $68.6$ 提升至 $82.4$。 尽管训练数据有限,仅包含 GSM8K 和 MATH 500,但我们观察到在 AIME 2024 和 AMC 2023 等竞赛级别的基准测试中,性能也得到了大幅提升。 这突显了零样本强化学习训练令人印象深刻的泛化能力,使模型能够弥合从简单到困难问题的差距。
除了 Qwen 系列模型外,我们还显著提高了其他初始基线较低的模型的性能和回复长度。 例如,DeepSeek-Math-7B 模型最初的性能得分约为 $10.0$。 仅经过 80 次训练迭代后,其性能就提升了三倍以上,而回复长度从大约 $300$ 个 Token 增加到超过 $1200$ 个 Token。
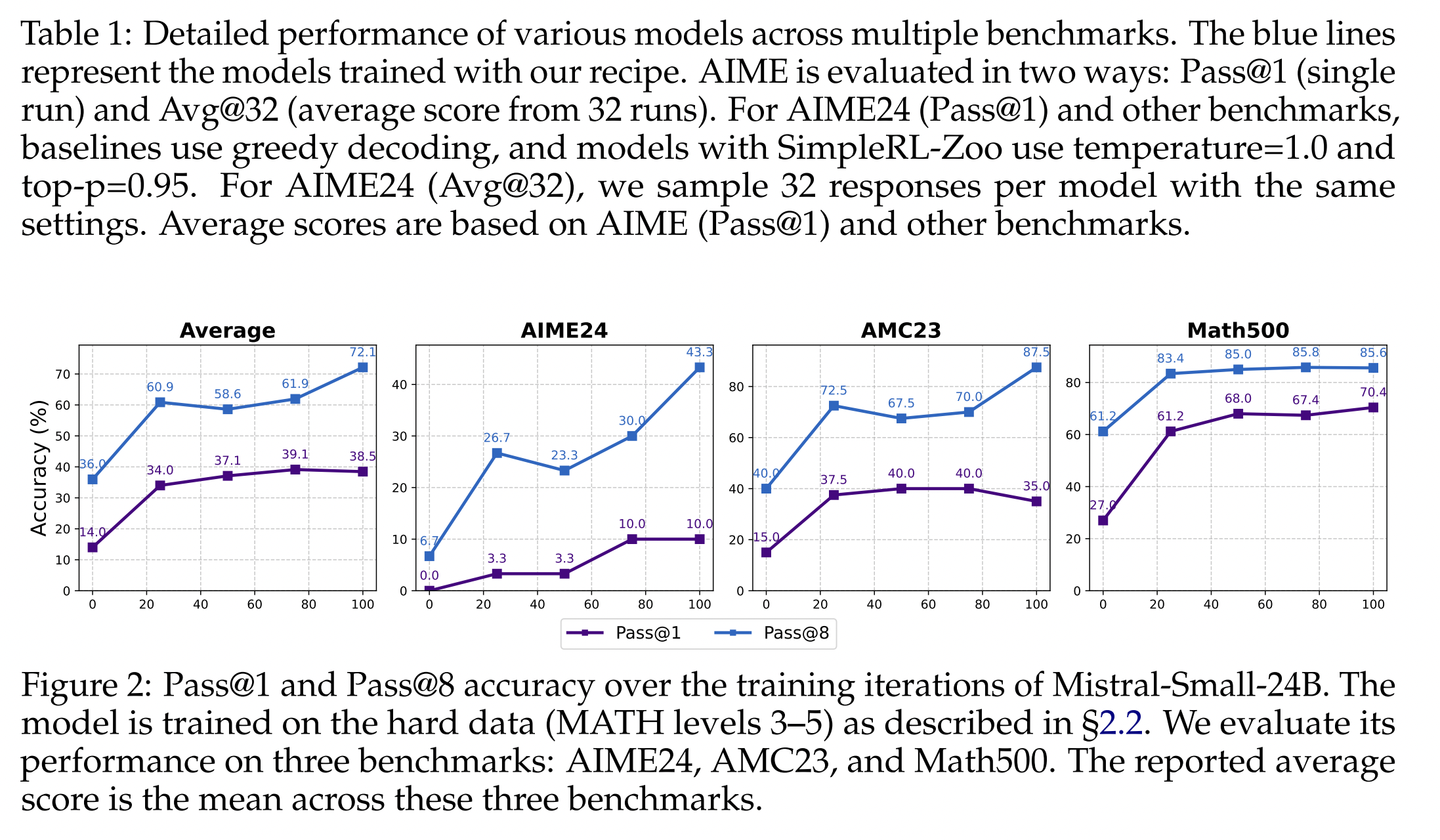
Pass@k 准确率的持续提升:
如图2所示,Mistral-Small-24B 在 MATH 500 数据集上展现出 pass@8 指标的显著提升。此外,随着训练的进行,模型的 pass@1 结果最终超越了基础模型的初始 pass@8 结果。 令人惊讶的是,Pass@1 和 Pass@8 之间的差距在训练过程中并未缩小,反而随着训练的推进而扩大。 在经过 100 次迭代后,这两个指标的平均差距超过了 30 个百分点。 这表明强化学习 (RL) 在未来仍有巨大的改进潜力,因为 pass@8 代表了模型探索并找到正确答案的能力。 此外,图3显示,即使在 k 值较高的情况下,基础模型与经过强化学习训练后的模型之间,pass@k 的性能差距依然显著。 值得注意的是,仅经过 100 次训练迭代,该模型所达到的 pass@1 性能就与基础模型的 pass@16 性能相当。

这表明无需强化学习 (RL) 训练,模型不仅调整了其输出分布,使其更倾向于前 k 个候选答案中的正确答案,还增强了模型的内部推理能力。
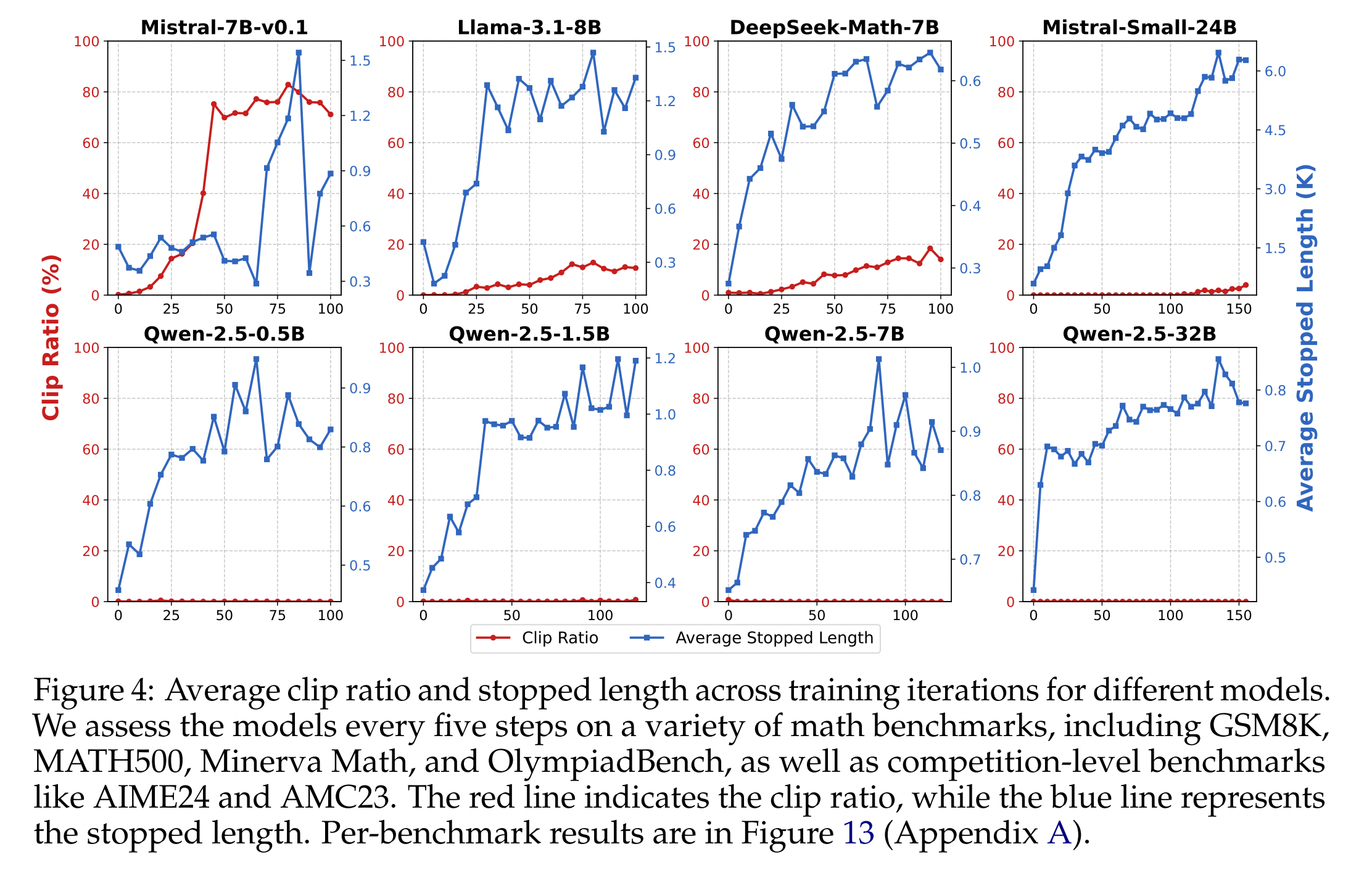
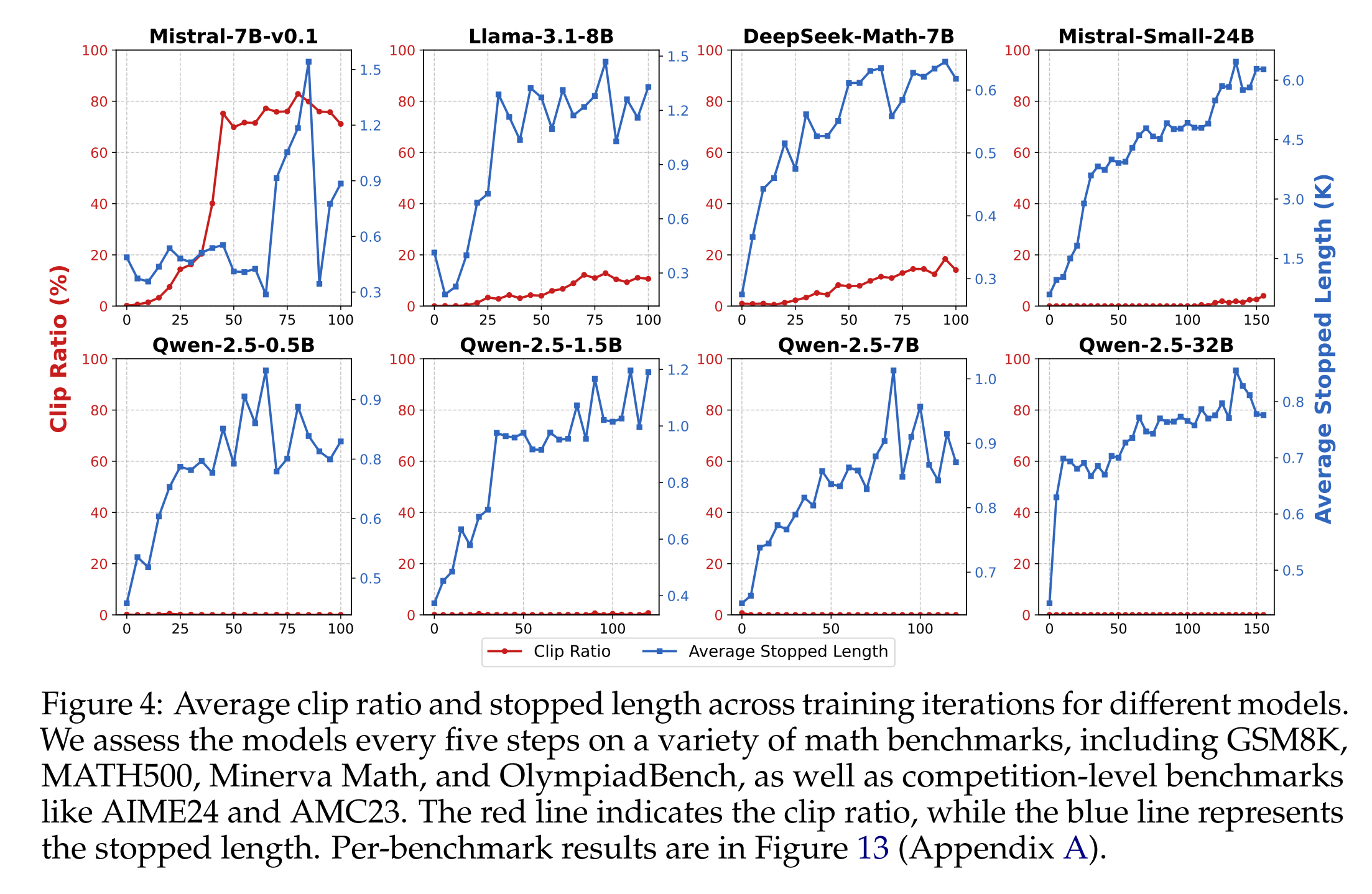
回复长度的增长可能是不健康的:
回复长度并不总是反映推理能力的真正增长。在某些情况下,不稳定的训练可能导致模型生成过多的重复内容,直到达到上下文长度限制,从而人为地夸大回复长度,而没有提高推理深度。例如,图4显示,虽然大多数模型保持较低的裁剪率(低于数据的 5%),但当它们的平均停止长度稳步增加时,Mistral-7B-v0.1 表现出较高的裁剪率和停止长度的显著波动。通过更仔细地检查其回复,我们发现这些回复由不连贯的、混合语言的无意义内容组成,这表明它的思考过程并没有真正扩展。我们注意到,这种模式不会被图1中的回复长度所捕获。这些发现表明,大多数模型表现出回复长度的有意义且结构化的增加。这引出了一个重要问题:随着思考时间的增加,模型到底学习到了什么?我们将在接下来回答这个问题。
“推理行为涌现的量化”——量化推理行为的涌现
图5展示了模型训练期间 OlympiadBench 上的推理行为比率。通过比较图5与图4, 我们观察到推理行为比率的波动有效地解释了平均停止长度的变化。有趣的是,我们发现不同的模型在推理行为变化方面表现出完全不同的趋势。较小的模型,例如 Qwen-2.5-0.5B 和 Qwen-2.5-1.5B,倾向于优先学习“设定子目标”行为,其比例增加了约 4-5 倍。此外,“验证”和“枚举”的比例也显示出显着增长。相比之下,对于其他本身就具有逐步推理能力的基础模型,在强化学习训练过程中,“设定子目标”的调整相对较小。
在训练过程中,我们观察到 DeepSeek-Math-7B、Llama-3.1-8B 和 Mistral-Small-24B 在“枚举法”和“验证”行为的比例上出现了显著增长,从相对较低的初始水平上升了大约 3-4 倍。这种增长与它们平均停止 Token 长度的变化密切相关,表明随着时间的推移,推理模式发生了转变。例如,在 Mistral-Small-24B 中,诸如“验证”和“回溯”等面向反思的行为从接近 0% 显著增加到大约 50%,表明反思行为是从头开始出现的。这种转变表明,该模型逐渐将验证机制内化为推理过程的一部分,为进一步增强提供了有希望的轨迹。
相比之下,Qwen-2.5-7B 和 32B 从一开始就表现出强大的推理行为,并且在整个训练过程中变化很小。这种稳定性与它们缓慢的长度调整相符,并表明 Qwen 模型本身就具有强大的推理能力。它们主要受益于思考时间的少量增加,而不是推理过程的结构性转变,这会带来显著的性能提升。最后,我们观察到 Mistral-7B-v0.1 始终表现出较低的推理行为,且没有明显的增长。
为了直观地说明推理行为的变化,我们在图6中展示了 Mistral 24B 在“零训练”前后的推理示例。我们观察到,与基础模型不同,零训练模型会积极尝试验证其初始解是否有效,方法是将其代回原始表达式。在认识到第一个解不满足必要条件后,该模型会明确启动回溯方法,声明“让我们尝试另一种可能性”,最终得出正确答案。
塑造零训练的关键因素
在本节中,我们确定了影响零 RL 训练期间稳定性和性能的关键因素,尤其是在处理早期或较弱的模型时。首先,我们探讨过度依赖格式奖励如何限制探索。接下来,我们分析数据难度如何影响探索行为,说明接触不同难度级别如何塑造基础模型的探索动态。

过度依赖格式奖励
我们发现,强制执行严格的格式约束,例如要求最终答案必须包含在 LaTeX 命令 \boxed{} 中,会阻碍模型自由探索,并最终降低性能。 这是因为许多基础模型在初始阶段无法很好地遵循格式约束,而施加格式奖励会惩罚许多正确的探索。 我们比较了两种奖励函数:一种没有格式约束,仅根据答案的正确性来奖励响应,另一种严格执行格式,如果响应未能遵守要求的格式,则以 -1 的奖励来惩罚。 如图7所示,较弱的模型(如 Llama-3.1-8B)在严格的格式要求下表现不佳,导致训练初期响应长度迅速增加,但性能没有提高。 该模型花费了过多的精力来遵守格式,但未能学会如何正确回答,最终导致模型崩溃。 图 7a进一步表明,即使是更强大的模型(如 Qwen-2.5-7B),虽然最初符合格式约束,但在后来的训练阶段也会受到影响。 这包括性能下降和 CoT (Chain of Thought, 思维链) 长度的显著减少。 此外,严格的格式约束限制了模型的上限性能潜力,表明刚性约束会扼杀其有效探索和改进解决方案的能力。
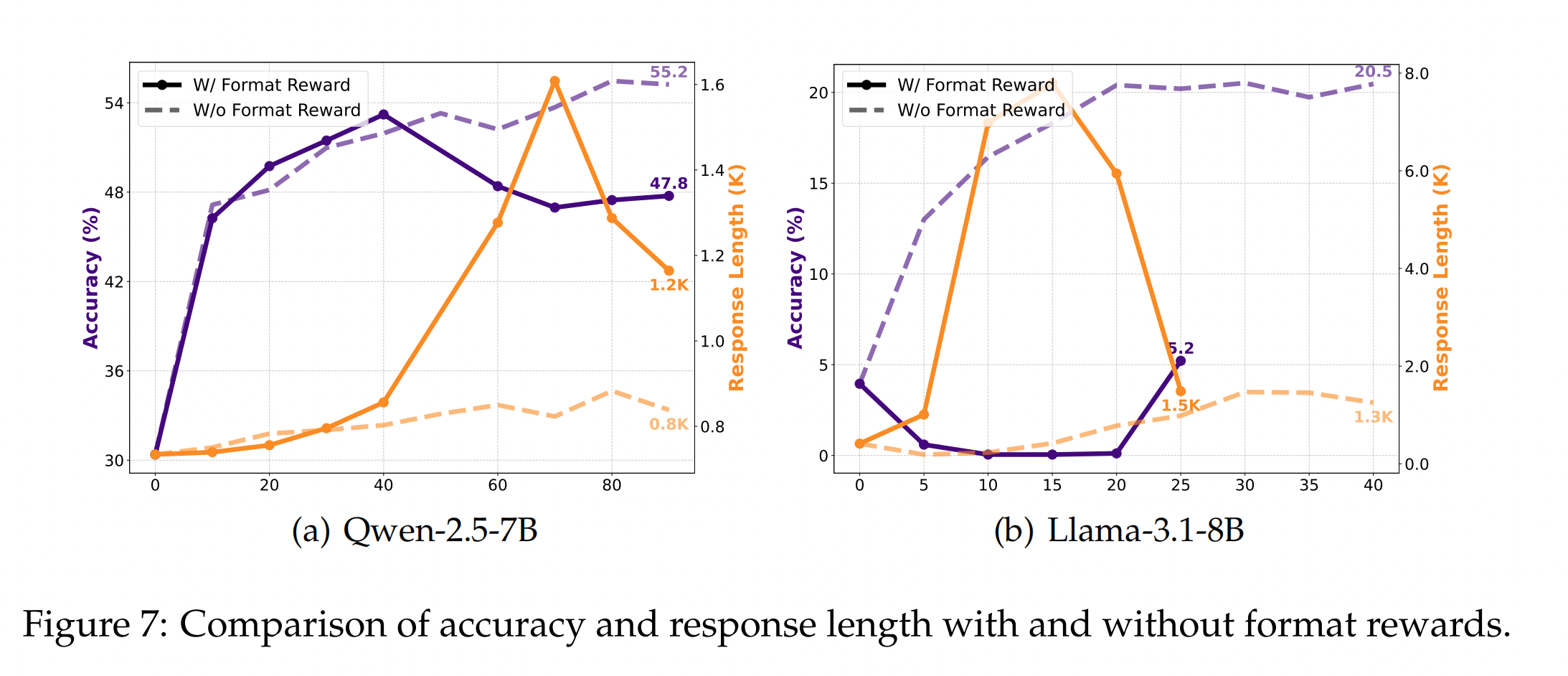
这些发现突显了一个关键的见解:在零样本强化学习(zero RL)训练环境中,我们应该优先保持响应的可验证性,同时允许足够的灵活性进行探索,而不是强加严格的格式规则。
探索行为中的数据难度
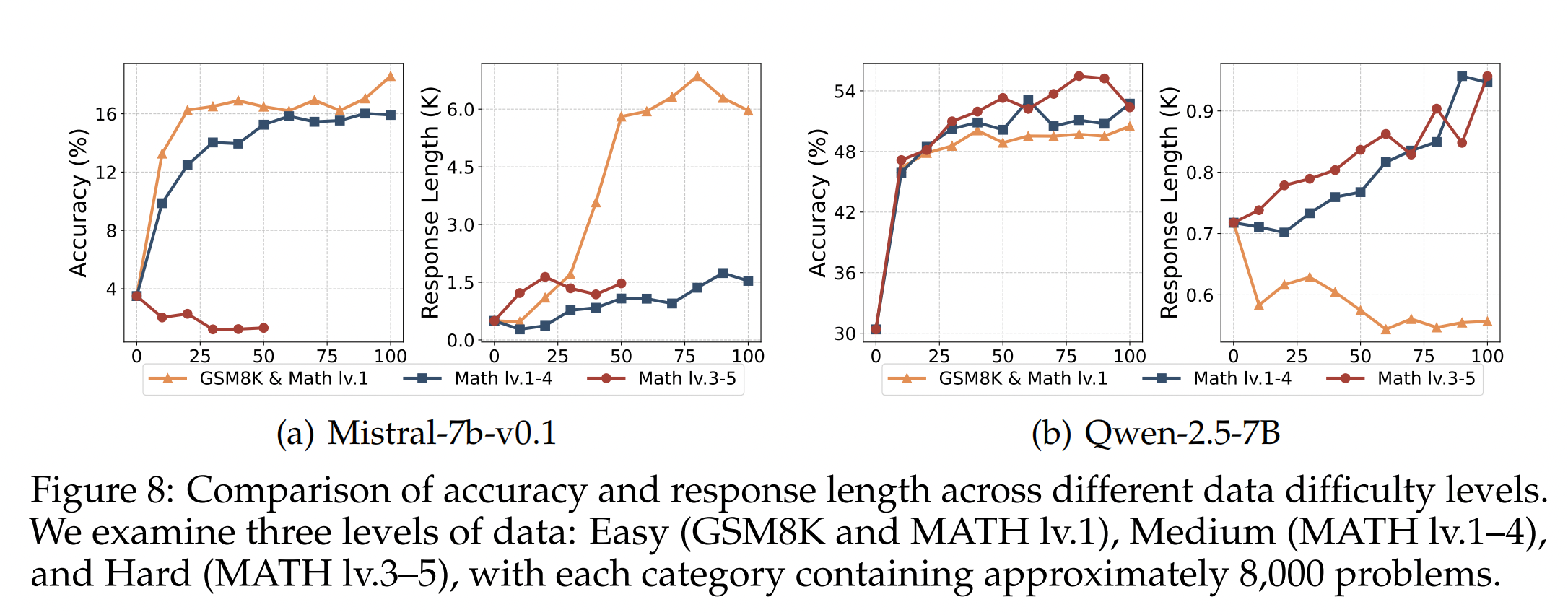
基础模型在不同强化学习(RL)数据上训练时,表现出不同的性能和思维链(CoT)行为。图8比较了Mistral-7B和Qwen-2.5-7B在简单(GSM8K,MATH Lv.1)、中等(MATH Lv.1-4)和困难(MATH Lv.3-5)数据集上的性能。我们观察到一个明显的趋势:随着数据难度的增加,Mistral-7B的性能逐渐恶化。当面对高难度数据(困难:MATH levels 3-5)时,该模型难以生成能够从奖励系统中获得积极反馈的响应。这种失败导致响应长度显著增加,但准确性没有任何相应的提高,这表明训练过程崩溃—通常被称为训练崩溃。图8表明,Qwen-2.5-7B表现出与Mistral-7B-v0.1完全相反的模式。具体而言,随着数据集难度的降低,模型的平均准确率和响应长度都会下降,且这种影响在最简单的数据集上最为明显,甚至响应长度也会下降。这一发现与我们之前对Qwen-2.5-7B的分析一致,强化了Qwen本身就具有强大推理能力的观点。为了进一步提高其响应长度,训练应包含更具挑战性的数据集,例如竞赛级别的问题,以鼓励更深入的推理和更长的思考时间。该分析突出显示了一个关键见解:零强化学习训练数据必须与基础模型固有的推理能力相一致,例如考虑其Pass@K性能等指标。
传统 SFT 如何影响 RL 驱动的推理涌现
鉴于基础模型可能无法很好地遵循指令,并且对零样本强化学习 (zero RL) 训练构成重大挑战,人们可能会想知道,一个简单的 SFT 阶段作为冷启动是否有助于学习更好地遵循指令。在本节中,我们重新审视传统 SFT 方法(即响应并非来自长链思维 (CoT) 模型)作为冷启动对强化学习 (RL) 训练性能和推理行为的影响——值得注意的是,在 DeepSeek-R1 之前,这是最常用的后训练流程,即在 SFT 阶段之后进行 RL。具体来说,我们使用从 GSM8K 和 MATH[^3] 派生的 NuminaMath 数据集的子集,其中包含大约 15K 个高质量的短链思维 (CoT) 响应。我们使用 Mistral 24B 在此数据上进行 SFT,并选择 100 步和 500 步训练步骤的模型作为强化学习 (RL) 训练的起点。

在图10中,我们展示了在使用不同初始模型时,强化学习(RL)训练期间模型准确性和输出长度的演变情况。 我们的结果表明,从监督微调(SFT)模型开始,最初可以显著提高性能;然而,与在长时间的强化学习(RL)训练期间从基础模型开始相比,这些模型在最大可实现的准确性和响应长度方面遇到了明显的限制。 至关重要的是,我们观察到,随着初始监督微调(SFT)步骤数量的增加,这些限制变得越来越明显。 例如,虽然基础模型在强化学习(RL)训练期间可以达到约49.6%的pass@1准确率,但使用100和500个监督微调(SFT)步骤初始化的模型分别只能达到约47.3%和40.3%的最大准确率。
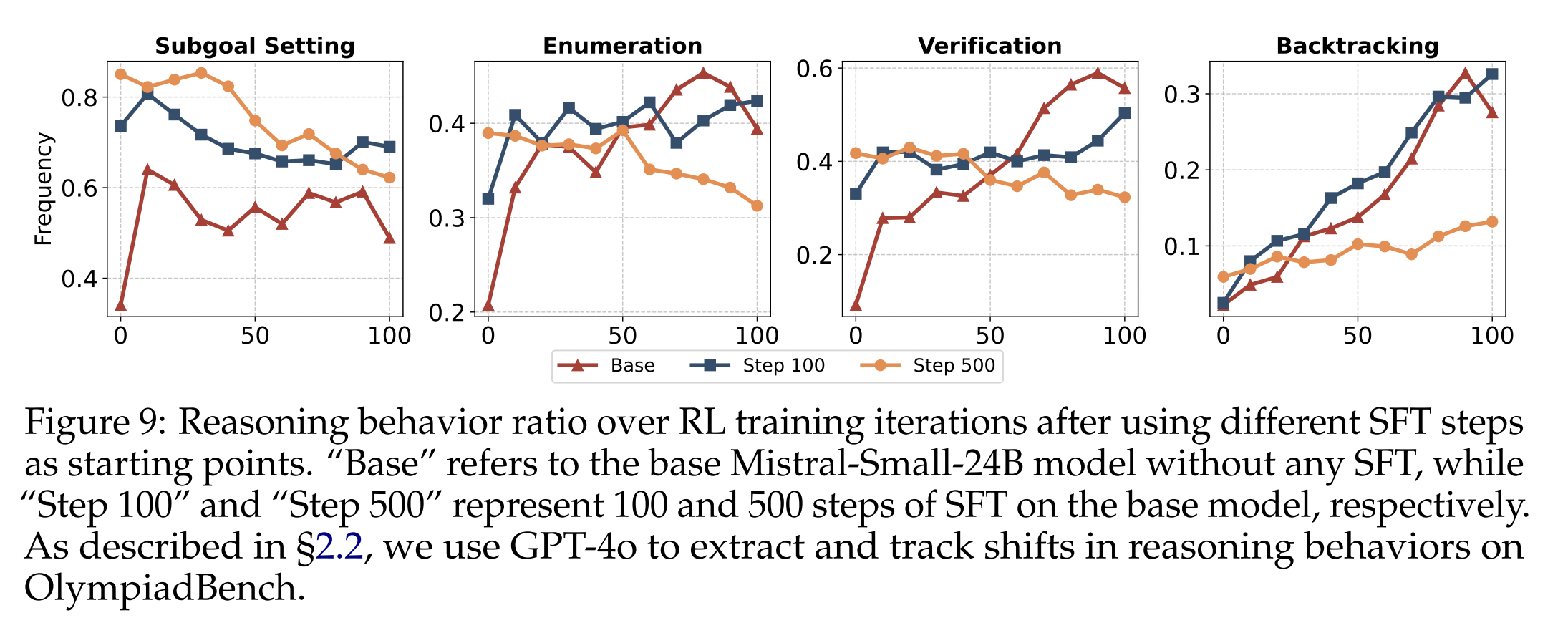
为了进一步研究初始的微调 (SFT) 如何影响推理行为的出现,我们分析了在不同起点训练期间,特定推理行为出现的频率,如图9所示。我们的分析表明,初始的微调 (SFT) 对关键推理行为的发展产生了负面影响。具体而言,与基础模型相比,经过 100 步微调 (SFT) 的模型在诸如“枚举”、“验证”和“回溯”等基本推理行为中表现出较低的上限。更值得注意的是,经过 500 步微调 (SFT) 的模型在后期训练阶段的“枚举”和“验证”行为显著下降,突显了过度微调 (SFT) 对推理能力的长期不利影响。 这促使我们重新考虑传统的微调 (SFT) 是否固有地限制了模型的探索能力,或许突显了未来冷启动策略需要优先考虑探索能力——无论是通过整合长链思维 (CoT) 数据,还是设计在模仿和探索之间取得平衡的微调 (SFT) 技术——以实现模型推理性能的持续改进。
结论
我们的论文证明了零样本强化学习 (zero RL) 训练在各种基础模型上的有效性,从而在推理准确性和响应长度方面产生了显著的改进。我们提供了强有力的证据,表明零样本强化学习训练不仅仅是重新排序,而是一种真正的增强。此外,我们还确定了奖励设计、数据难度和模型固有能力等关键因素,这些因素塑造了高级推理行为的出现。我们的研究结果还表明,从经过传统 SFT(监督微调)的模型开始强化学习训练可能会限制高级推理行为的发展。总的来说,我们的工作强调了有效零样本强化学习训练的关键因素,并为未来的模型改进提供了见解。