

《DAPO: an Open-Source LLM Reinforcement Learning System at Scale》
摘要
推理规模化使大语言模型具备了前所未有的推理能力,其中强化学习是引发复杂推理的核心技术。然而,最先进的推理大语言模型的关键技术细节往往被隐藏(如 OpenAI 的博客和 DeepSeek R1 技术报告),因此社区仍然难以复现他们的强化学习训练结果。我们提出了解耦裁剪和动态采样策略优化(Decoupled Clip and Dynamic sAmpling Policy Optimization,DAPO)算法,并完全开源了一个最先进的大规模强化学习系统,该系统使用 Qwen2.5-32B 基础模型在 AIME 2024 上达到了 50 分。与之前隐藏训练细节的工作不同,我们介绍了算法的四个关键技术,使大规模 LLM 强化学习取得成功。此外,我们开源了基于 verl 框架构建的训练代码,以及精心策划和处理的数据集。我们开源系统的这些组件增强了可复现性,并支持未来大规模 LLM 强化学习的研究。
1 引言
测试时扩展(如 OpenAI 的 O1 和 DeepSeek 的 R1 )为大语言模型(LLM)[3-7] 带来了深刻的范式转变。测试时扩展支持更长的思维链推理,并诱导复杂的推理行为,使模型在 AIME 和 Codeforces 等竞争性数学和编程任务中表现卓越。
推动这一革命的核心技术是大规模强化学习(RL),它引发了诸如自我验证和迭代强化等复杂推理行为。然而,可扩展 RL 训练的实际算法和方法仍然是个谜,在现有推理模型的技术报告中被隐藏。在本文中,我们揭示了大规模 RL 训练中的重大障碍,并开源了一个可扩展的 RL 系统,包括完全开源的算法、训练代码和数据集,提供了具有行业级 RL 结果的民主化解决方案。
我们以 Qwen2.5-32B [12] 作为 RL 的预训练模型进行实验。在我们初始的 GRPO 运行中,在 AIME 上仅实现了 30 分——远低于 DeepSeek 的 RL(47 分)。深入分析表明,朴素的 GRPO 基线存在几个关键问题,如熵崩塌、奖励噪声和训练不稳定性。更广泛的社区在复现 DeepSeek 的结果时遇到了类似的挑战 ,这表明 R1 论文中可能省略了开发行业级、大规模且可复现的 RL 系统所需的关键训练细节。
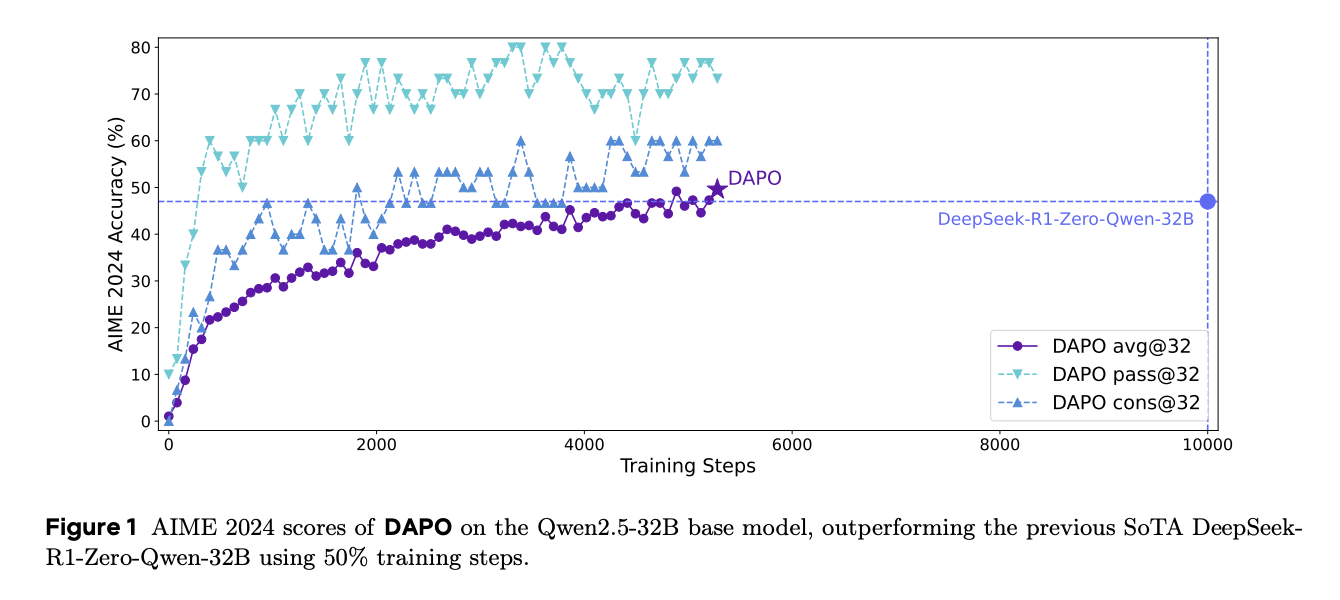
为弥补这一差距,我们发布了一个开源的最先进大规模 LLM RL 系统,该系统基于 Qwen2.5-32B 模型在 AIME 2024 上实现了 50 分,使用 50% 的训练步骤超过了之前最先进的 DeepSeek-RL-Zero-Qwen-32B (47 分)(图 1)。我们提出了解耦裁剪和动态采样策略优化(DAPO)算法,并介绍了 4 个关键技术,使 RL 在长思维链 RL 场景中脱颖而出。详细内容在第 3 节中呈现。
- 裁剪偏移(Clip-Shifting),促进系统多样性并允许自适应采样;
- 动态采样(Dynamic Sampling),提高训练效率和稳定性;
- Token级策略梯度损失(Token-Level Policy Gradient Loss),在长思维链 RL 场景中至关重要;
- 溢出奖励塑造(Overflowing Reward Shaping),减少奖励噪声并稳定训练。
我们的实现基于 Verl 。通过完全发布我们的最先进 RL 系统,包括训练代码和数据,我们旨在揭示大规模 LLM RL 的宝贵见解,造福更广泛的社区。
2 预备知识
2.1 近端策略优化(PPO)
PPO引入了一个裁剪的替代目标来进行策略优化。通过使用裁剪将策略更新限制在先前策略的近端区域内,PPO 稳定了训练并提高了样本效率。具体而言,PPO 通过最大化以下目标来更新策略:
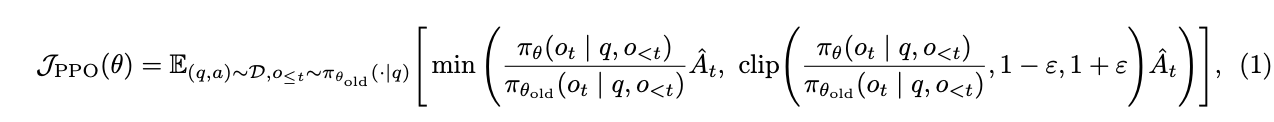
其中 $(q, a)$ 是来自数据分布 $D_e$ 的问题-答案对,$\epsilon$ 是重要性采样比率的裁剪范围,$\hat{A}_t$ 是时间步 $t$ 处优势的估计器。给定价值函数 $V$ 和奖励函数 $R$,$\hat{A}_t$ 使用广义优势估计(GAE)计算:
$$ \hat{A}_t^{GAE(\gamma,\lambda)} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l}, \tag{2} $$其中
$$ \delta_t = R_t + \gamma V(s_{t+1}) - V(s_t), \quad 0 \leq \gamma, \lambda \leq 1. \tag{3} $$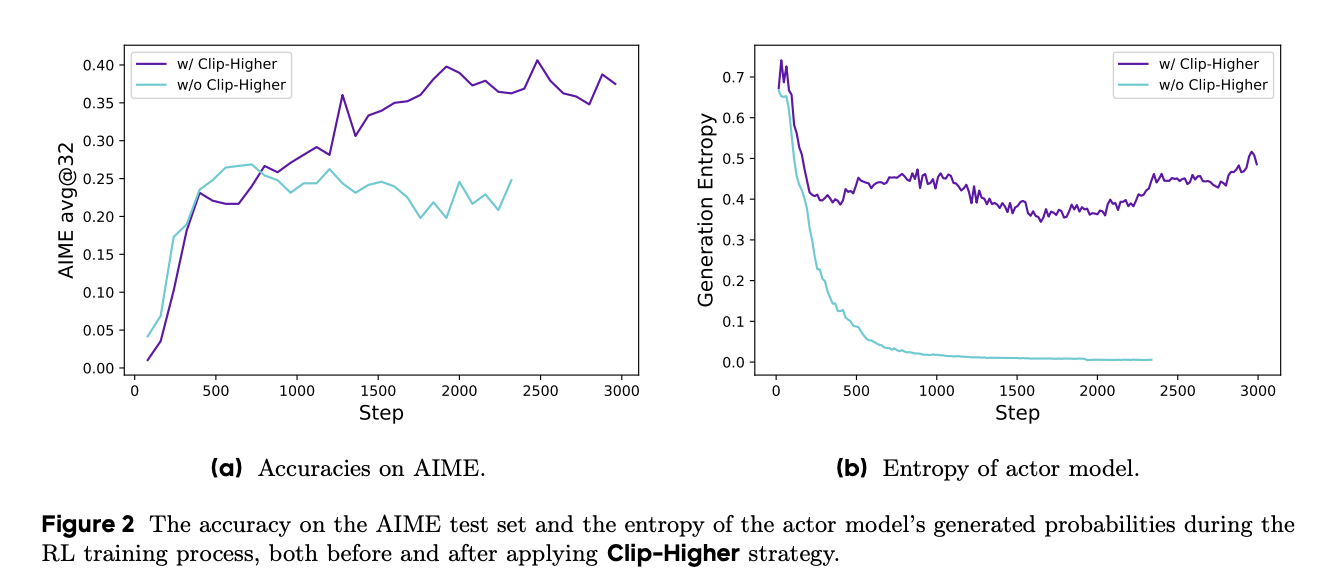
2.2 群体相对策略优化(GRPO)
与 PPO 相比,GRPO 消除了价值函数,并以群体相对方式估计优势。对于特定的问题-答案对 ((q, a)),行为策略 ( $\pi_{\text{old}}$) 采样一组 (G) 个独立响应 ($\{o_i\}_{i=1}^G$)。然后,通过归一化群体级奖励 ($\{R_i\}_{i=1}^G$) 计算第 ($i$) 个响应的优势:
$$ \hat{A}_{i,t} = \frac{r_i - \text{mean}(\{R_i\}_{i=1}^G)}{\quad \text{std}(\{R_i\}_{i=1}^G)} $$与 PPO 类似,GRPO 采用裁剪目标,并直接施加 KL 惩罚项:
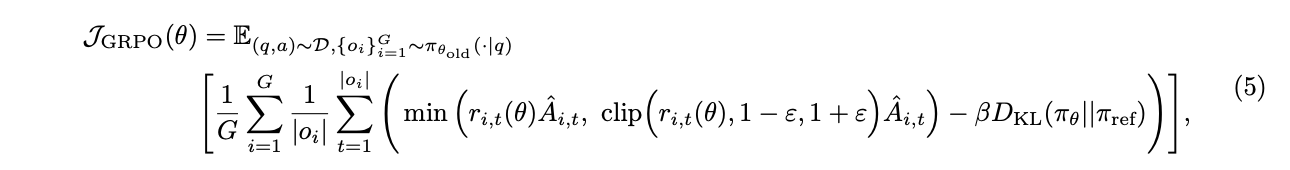
其中
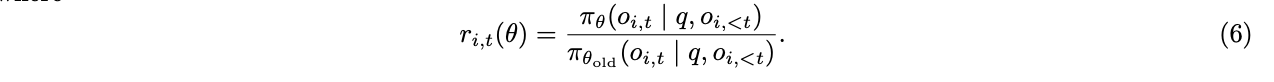
值得注意的是,GRPO 在样本级别计算目标。具体来说,GRPO 首先计算每个生成序列内的平均损失,然后对不同样本的损失取平均值。正如我们将在第 3.3 节中讨论的那样,这种差异可能会影响算法的性能。
2.3 移除 KL 散度
KL 惩罚项用于调节在线策略与冻结参考策略之间的散度。在 RLHF 场景中,RL 的目标是在不偏离初始模型太远的情况下调整模型行为。然而,在训练长思维链推理模型时,模型分布可能与初始模型显著偏离,因此这种限制不是必要的。因此,我们将从我们提出的算法中排除 KL 项。
2.4 基于规则的奖励建模
使用奖励模型通常会遇到奖励hack问题。相反,我们直接使用可验证任务的最终准确性作为结果奖励,使用以下规则计算:
$$ R(\hat{y}, y) = \begin{cases} 1, & \text{is\_equivalent}(\hat{y}, y) \\ -1, & \text{otherwise} \end{cases} \tag{7} $$其中 $y$ 是真实答案,$\hat{y}$ 是预测答案。这被证明是激活基础模型推理能力的有效方法,如在自动定理证明、计算机编程和数学竞赛等多个领域所示。
3 DAPO
我们提出解耦裁剪和动态采样策略优化(Decouple Clip and Dynamic sAmpling Policy Optimization,DAPO)算法。DAPO 为每个问题 $q$ 及其配对答案 $a$ 采样一组输出 $\{o_i\}_{i=1}^{G}$,并通过以下目标函数优化策略:
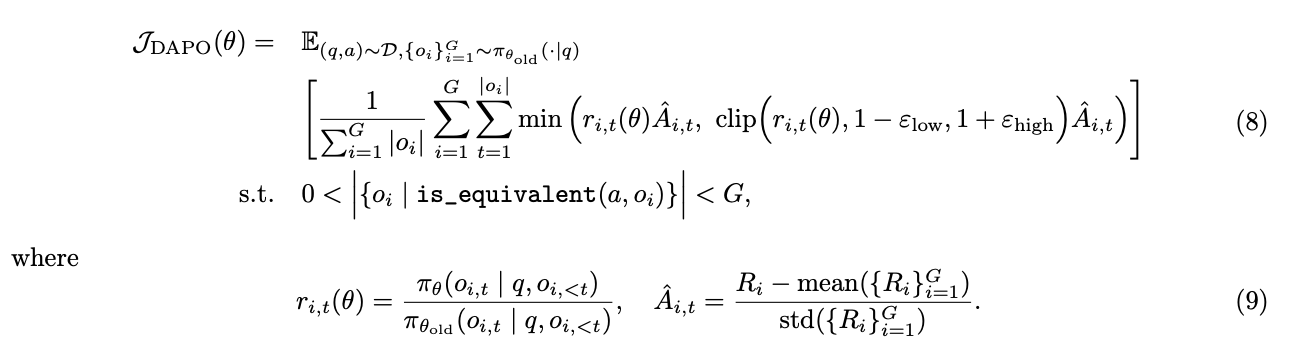
完整算法可在算法 1 中找到。在本节中,我们将介绍与 DAPO 相关的关键技术。
3.1 提高上限:更高裁剪(Clip-Higher)
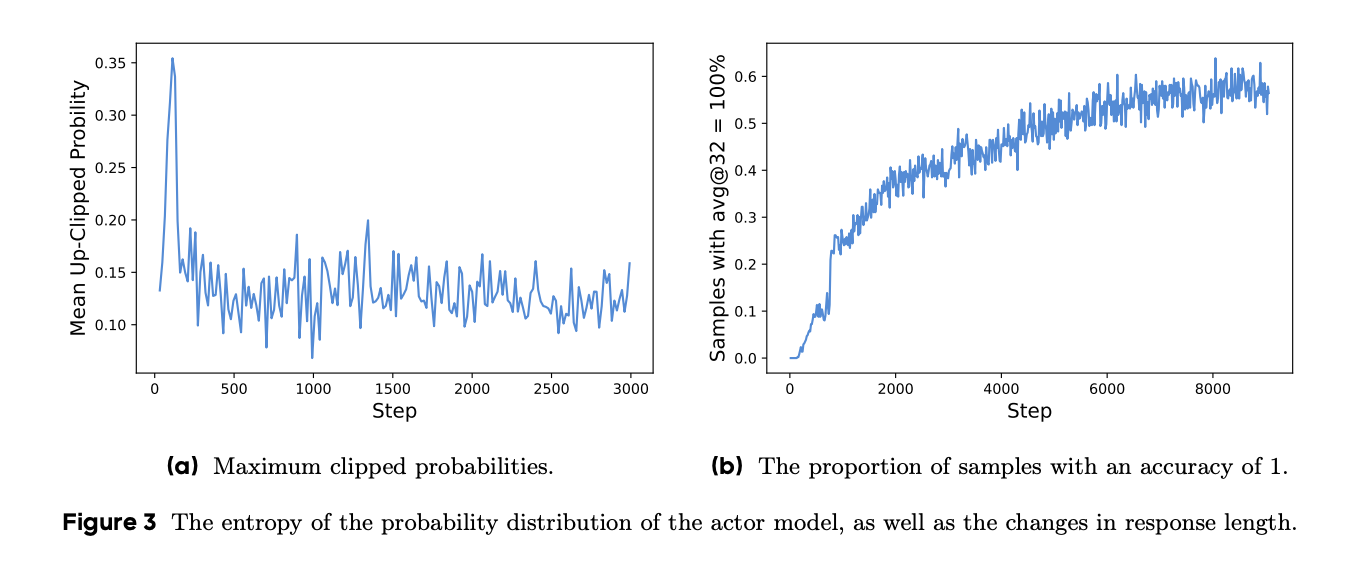
在我们使用朴素 PPO或 GRPO的初始实验中,我们观察到随着训练的进行,策略的熵迅速降低(图 2b)。某些组的采样响应往往几乎相同。这表明有限的探索和过早的确定性策略,可能会阻碍扩展过程。
我们提出了更高裁剪(Clip-Higher)策略来解决这个问题。对重要性采样比率的裁剪是在裁剪近端策略优化(PPO-Clip)中引入的,目的是限制信任区域并增强 RL 的稳定性。我们发现上裁剪可以限制策略的探索。在这种情况下,使"利用型 token"更有可能比提升"探索型 token"的概率要容易得多。
具体来说,当 $\epsilon = 0.2$(大多数算法的默认值)时,考虑两个动作,其概率分别为 $\pi_{\text{data}}(o_i | q) = 0.01$ 和 $0.9$。更新后的最大可能概率分别为 $\pi(o_i | q) = 0.012$ 和 $1.08$。这意味着对于概率较高的 token(如 $0.9$),受到的约束较少。相反,对于低概率 token,要实现概率的显著增加要困难得多。经验上,我们还观察到裁剪 token 的最大概率约为 $\pi(o_i | q) < 0.2$(图 3a)。这一发现支持了我们的分析,即上裁剪阈值确实限制了低概率 token 的概率,从而可能限制了系统的多样性。
遵循更高裁剪策略,我们将下裁剪和上裁剪范围解耦为 $\epsilon_{\text{low}}$ 和 $\epsilon_{\text{high}}$,如公式 10:
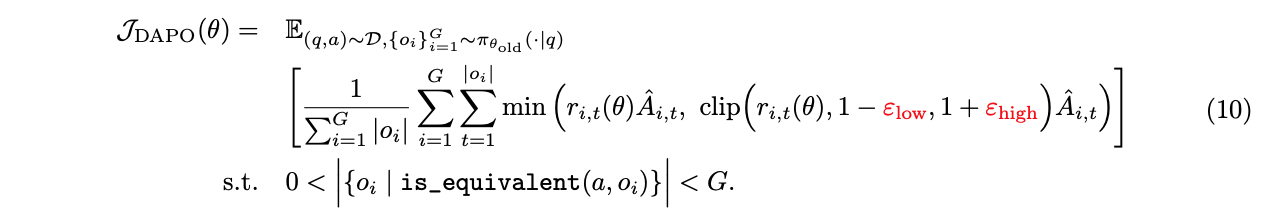
我们增加 ($\epsilon_{high}$) 的值,为低概率 Token 的增加留出更多空间。如图 2 所示,这种调整有效地提高了策略的熵,促进了更多样化样本的生成。我们选择保持 ($\epsilon_{low}$) 相对较小,因为增加它会最终抑制这些 Token 的概率,导致采样空间的崩塌。
3.2 多多益善:动态采样
现有的 RL 算法在某些提示的准确率等于 1 时通常会遇到梯度减少问题。例如对于 GRPO,如果特定提示的所有输出 $\{o_i\}^{G}_{1}$ 都是正确的并且获得相同的奖励 1,那么该组的结果优势为零。零优势导致策略更新没有梯度,从而降低了样本效率。实证上,准确率等于 1 的样本数量不断增加,如图 3b 所示。这意味着每个批次中有效提示的数量不断减少,这可能导致梯度方差更大,并削弱模型训练的梯度信号。
为此,我们提出对准确率等于 1 的提示进行过采样和过滤,如公式 11 所示,保留批次中所有具有有效梯度的提示,并保持提示数量的一致性。在训练前,我们不断采样,直到批次完全填满准确率既不为 0 也不为 1 的样本。
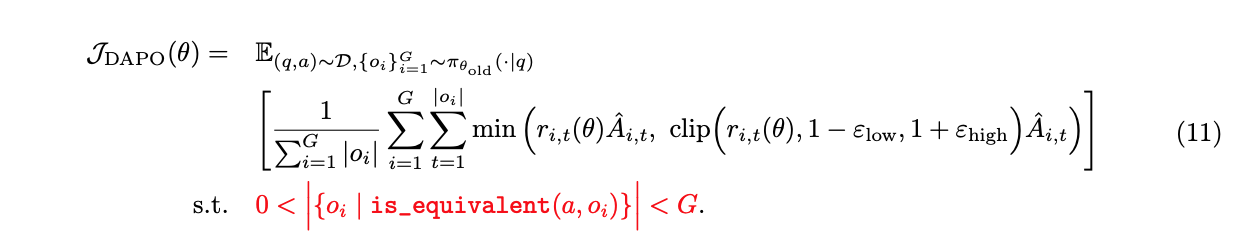
请注意,这种策略不一定会阻碍训练效率,因为如果 RL 系统是同步的且生成阶段是如此,那么生成时间通常由长尾样本的生成所主导。
3.3 再平衡行动:Token级策略梯度损失
原始的 GRPO 算法采用样本级损失计算,这涉及首先在每个样本内按 Token 平均损失,然后汇总样本间的损失。在这种方法中,每个样本在最终损失计算中被分配相同的权重。然而,我们发现这种损失降低方法在长思维链 RL 场景中引入了几个挑战。
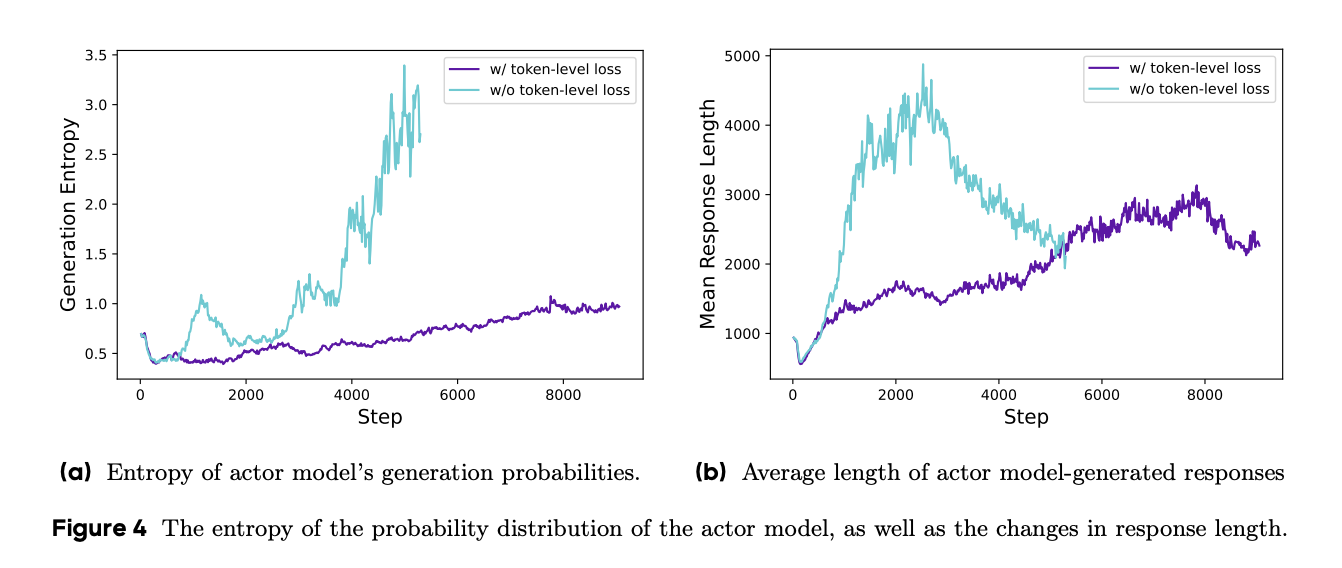
由于所有样本在损失计算中被赋予相同的权重,较长响应(含有更多 Token)中的 Token 对整体损失的贡献可能不成比例地低,这可能导致两种不利影响。首先,对于高质量的长样本,这种效应可能阻碍模型学习其中的推理相关模式。其次,我们观察到过长的样本通常表现出低质量模式,如胡言乱语和重复词。因此,样本级损失计算由于无法有效惩罚长样本中的这些不良模式,导致熵和响应长度不健康增加,如图 4a 和图 4b 所示。
我们在长思维链 RL 场景中引入了Token级策略梯度损失来解决上述限制:
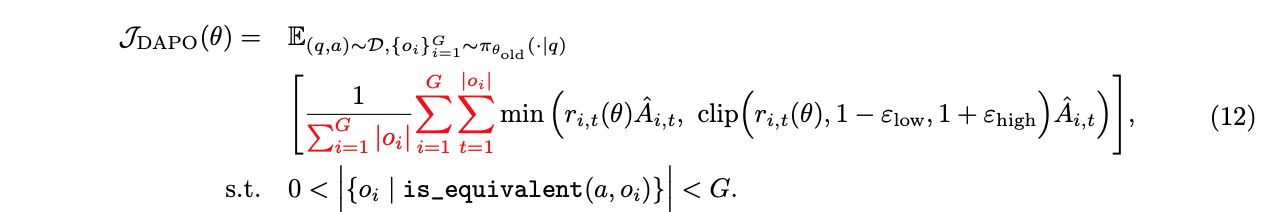
在这种设置下,较长序列相比较短序列对整体梯度更新的影响可能更大。此外,从单个 Token 的角度来看,如果特定生成模式能导致奖励增加或减少,无论它出现在哪种长度的响应中,都将被同等地促进或抑制。
3.4 躲猫猫:超长奖励塑造
在 RL 训练中,我们通常为生成设置最大长度,相应地截断超长样本。我们发现对截断样本不当的奖励塑造会引入奖励噪声,显著扰乱训练过程。
默认情况下,我们对截断样本分配惩罚性奖励。这种方法可能在训练过程中引入噪声,因为一个合理的推理过程可能仅仅因为长度过长而受到惩罚。这种惩罚可能使模型对其推理过程的有效性产生混淆。
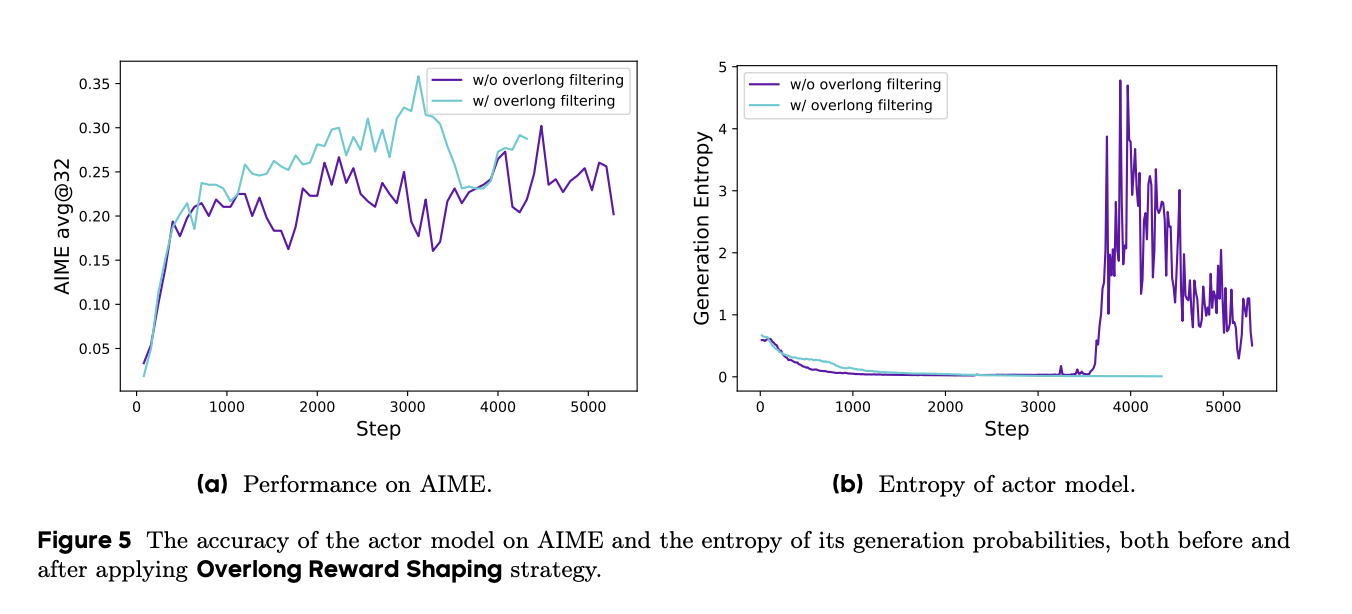
为研究这种奖励噪声的影响,我们首先应用了超长过滤策略,屏蔽截断样本的损失。我们发现这种方法显著稳定了训练并提高了性能,如图 5 所示。
此外,我们提出了软超长惩罚(公式 13),一种针对截断样本的长度感知惩罚机制。具体来说,当响应长度超过预定义的最大值时,我们定义一个惩罚区间。在该区间内,响应越长,受到的惩罚越大。这种惩罚添加到原始基于规则的正确性奖励中,从而向模型发出避免过长响应的信号。
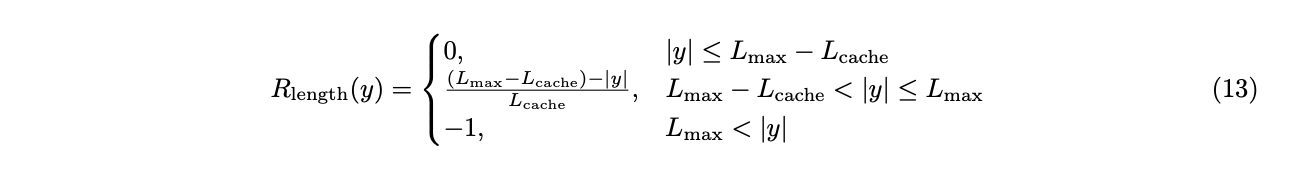

3.5 数据集转换
我们的数据集来自 AoPS¹ 网站和官方竞赛主页,通过网络爬取和人工注释的组合获取。数学数据集的答案通常以各种格式出现,如表达式、公式和数字,这使得设计全面的规则来解析它们变得具有挑战性。为了使用规则提供准确的奖励信号并最小化公式解析器引入的错误,借鉴 AIME,我们选择并转换答案为整数,这些整数易于解析。例如,如果原始答案以 $\frac{a+\sqrt{b}}{c}$ 的形式表示,我们指导 LLM 修改问题,使预期答案变为 $a + b + c$。经过选择和转换,我们获得了 DAPO-Math-17K 数据集,其中包含 17K 提示,每个提示都与一个整数答案配对。
4 实验
4.1 训练细节
在这项工作中,我们专注于数学任务来评估我们的算法,该算法可以轻松转移到其他具有明确精确奖励信号的可验证任务。我们采用 verl 框架进行训练。我们使用 GRPO 作为基线算法,并使用群体奖励归一化估计优势。
对于超参数,我们使用 AdamW优化器,学习率恒定为 $1 \times 10^{-6}$ ,包含 20 步的线性预热。对于rollout,我们采用 512 的提示批量大小,并为每个提示采样 16 个响应。对于训练,小批量大小设为 512,即每次rollout 16 次梯度更新。对于超长奖励塑造,我们将预期最大长度设为 16,384 个 Token,并分配额外的 4,906 个 Token 作为软惩罚缓存。因此,生成的最大 Token 数量设为 20,480 个 Token。至于更高裁剪机制,我们将裁剪参数 $c_{\text{low}}$ 设为 0.2, $c_{\text{high}}$ 设为 0.28,这有效平衡了探索与利用之间的权衡。应用动态采样时,尽管由于过滤掉零梯度数据需要采样更多数据,但总体训练时间并没有显著受到影响。如图 6 所示,尽管采样实例数量增加,但由于所需训练步骤减少,模型的收敛时间反而减少了。
4.2 主要结果
在 AIME 2024 上的实验表明,DAPO 已成功地将 Qwen-32B Base 模型训练成一个强大的推理模型,其性能优于 DeepSeek 在 Qwen2.5-32B 上使用 R1 方法的实验。在图 1 中,我们观察到 AIME 2024 上性能的显著提升,准确率从接近 0% 提高到 50%。值得注意的是,这一改进仅使用了 DeepSeek-R1-Zero-Qwen-32B 所需训练步骤的 50%。
我们分析了我们方法中每种训练技术的贡献,如表 1 所示。观察到的改进证明了这些技术在 RL 训练中的有效性,每种技术都在 AIME 2024 中贡献了几个准确率点。值得注意的是,在朴素 GRPO 设置下,从 Qwen.2-5-32B 基础模型训练只能达到 30% 的准确率。
对于 Token 级损失,尽管它带来的性能提升较少,但我们发现它增强了训练稳定性,使长度增长更加健康。
| 模型 | AIME24_avg@32 |
|---|---|
| DeepSeek-R1-Zero-Qwen-32B | 47 |
| 朴素 GRPO | 30 |
| + 超长过滤 | 36 |
| + 更高裁剪 | 38 |
| + 软超长惩罚 | 41 |
| + Token级损失 | 42 |
| + 动态采样 (DAPO) | 50 |
4.3 训练动态
大语言模型的强化学习不仅是一个前沿研究方向,还是一个本质上复杂的系统工程挑战,其特点是各个子系统之间的相互依存。对任何单一子系统的修改都会通过系统传播,由于这些组件之间的复杂相互作用而导致不可预见的后果。即使在某些条件下看似微小的变化,例如数据和超参数的变化,也可能通过迭代强化学习过程放大,导致结果的实质性偏差。这种复杂性经常使研究人员面临两难:即使在仔细分析和合理预期认为某项修改将增强训练过程的特定方面之后,实际结果经常偏离预期轨迹。因此,在实验过程中监测关键中间结果对于迅速识别差异来源并最终完善系统至关重要。
生成响应的长度是一个与训练稳定性和性能密切相关的指标,如图 7a 所示。长度的增加为模型提供了更大的探索空间,允许更复杂的推理行为被采样并通过训练逐步强化。然而,值得注意的是,长度并不总是在训练过程中保持持续上升趋势。在某些相当长的时期内,它可能呈现停滞甚至下降的趋势,这在 [2] 中也有所证明。我们通常将长度与验证准确率一起作为指标来评估实验是否在恶化。
训练期间奖励的动态一直是强化学习中关键的监测指标之一,如图 7b 所示。在我们的大多数实验中,奖励增加的趋势相对稳定,不会因实验设置的调整而显著波动或下降。这表明,给定可靠的奖励信号,语言模型可以稳健地拟合训练集的分布。然而,我们发现,训练集上的最终奖励通常与验证集上的准确率几乎没有相关性,这表明对训练集的过度拟合。
演员模型的熵和生成概率与模型的探索能力相关,是我们在实验中密切监测的关键指标。直观上,模型的熵需要保持在适当的范围内。过低的熵表明概率分布过于尖锐,导致探索能力丧失。相反,
在 RL 训练过程中,我们观察到一个有趣的现象:演员模型的推理模式随时间动态演变。具体来说,该算法不仅强化了现有的有助于正确解决问题的推理模式,还逐渐产生了最初不存在的全新推理模式。这一发现揭示了 RL 算法的适应性和探索能力,并为模型的学习机制提供了新的见解。
例如,在模型训练的早期阶段,几乎没有检查和反思先前推理步骤的情况。然而,随着训练的进行,模型表现出明显的反思和回溯行为,如表 2 所示。这一观察为进一步探索 RL 过程中推理能力的出现提供了启示,我们将这一点留给未来的研究。
5 结论
在本文中,我们发布了一个完全开源的大规模 LLM RL 系统,包括算法、代码基础设施和数据集。该系统实现了最先进的大规模 LLM RL 性能(使用 Qwen-32B 预训练模型在 AIME 上得到 50 分)。我们提出了解耦裁剪和动态采样策略优化(DAPO)算法,并介绍了 4 个关键技术,使 RL 在长 CoT RL优化(DAPO)算法,并介绍了 4 个关键技术,使 RL 在长 CoT RL 场景中强大有效和高效。此外,通过开源训练代码和数据集,我们为广大研究社区和社会提供了可扩展强化学习解决方案的实际访问途径,使所有人都能从这些进步中受益。